table of Contents
This article first describes how the general gradient descent method is to update the parameters, then describes how to update the parameters of Adam, and Adam and learn how to combine the rate of decay.
Gradient descent update parameters
Gradient descent update method parameters formula:
\ [\ theta_ +. 1 {T} = \ theta_ {T} - \ ETA \ CDOT \ nabla J (\ theta_t) \]
Wherein, \ (\ ETA \) is the learning rate, \ (\ theta_t \) is the first \ (T \) wheel parameters, \ (J (\ theta_t) \) is the loss function, \ (\ nabla J (\ theta_t ) \) is a gradient.
In the simplest gradient descent, the learning rate \ (\ eta \) is a constant, is the need to achieve a good super set parameters, parameter update in each round are the same, in a study of each parameter update rates are the same.
To represent simple, so \ (G_T = \ nabla J (\ theta_t) \) , so the gradient descent algorithm can be expressed as:
\ [\ theta_ {T +. 1} = \ theta_ {T} - \ ETA \ CDOT G_T \]
Adam parameter update
ADAM, full name Adaptive Moment Estimation, an optimizer, a variant of a gradient descent method, is used to update the weights of the neural network weights.
Adam 更新公式:
\[ \begin{aligned} m_{t} &=\beta_{1} m_{t-1}+\left(1-\beta_{1}\right) g_{t} \\ v_{t} &=\beta_{2} v_{t-1}+\left(1-\beta_{2}\right) g_{t}^{2} \\ \hat{m}_{t} &=\frac{m_{t}}{1-\beta_{1}^{t}} \\ \hat{v}_{t} &=\frac{v_{t}}{1-\beta_{2}^{t}} \\ \theta_{t+1}&=\theta_{t}-\frac{\eta}{\sqrt{\hat{v}_{t}}+\epsilon} \hat{m}_{t} \end{aligned} \]
Adam in the original paper and some deep learning framework, the default is \ (\ ETA = 0.001 \) , \ (\ beta_1 = 0.9 \) , \ (\ beta_2 = 0.999 \) , \ (\ Epsilon = 1E-8 \ ) . Wherein, \ (\ beta_1 \) and \ (\ beta_2 \) are close to the number 1, \ (\ Epsilon \) to prevent division by zero. \ (g_ {t} \) denotes the gradient.
At first sight very complex, took unpack:
- 前两行:
\[ \begin{aligned} m_{t} &=\beta_{1} m_{t-1}+\left(1-\beta_{1}\right) g_{t} \\ v_{t} &=\beta_{2} v_{t-1}+\left(1-\beta_{2}\right) g_{t}^{2} \end{aligned} \]
This is the square of the gradient and the gradients were moving average , even though every time an update was both relevant and historical value.
The two middle lines:
\ [\ the aligned the begin {} \ Hat} m {T} {_ & = \ {m_Low FRAC} {T} {l- \ beta_. 1} ^ {} {} T \\ \ Hat {V} _ {t} & = \ frac
{v_ {t}} {1- \ beta_ {2} ^ {t}} \ end {aligned} \] this is the beginning of a larger moving average deviation correction, called the bias correction when \ (\ T) when growing, \ (l- \ beta_ {1} ^ {T} \) and \ (1- \ beta_ {2} ^ {t} \) converges to 1, At this bias correction of the task is finished.Last line:
\ [\ theta_ {T +. 1} = \ theta_ {T} - \ FRAC {\ ETA} {\ sqrt {\ Hat {V} _ {T}} + \ Epsilon} \ Hat {m} _ { t} \]
This is the parameter update formula.
Learning rate \ (\ FRAC {\ ETA} {\ sqrt {\} _ {V} + {T} \ Hat Epsilon} \) , each round of learning rate is no longer held constant, in one each learning rate parameter is not the same, because \ (\ ETA \) dividing each parameter \ (\ frac {1} { 1- \ beta_2} = 1000 \) wheel and the root mean square gradient, i.e., \ (\ sqrt {\ FRAC. 1} {1000} {\ sum_ K = {999} T-T ^ {2}} G_k ^ \) . The gradient of each parameter is different, so the learning rate for each parameter even in the same round are also not the same. (May be in doubt, \ (t \) is not in front of 999 update how to do, then how many rounds even if the number of rounds, as well as bias correction at this time.)
And the direction of the updated parameters is not just the front wheel gradient \ (G_T \) , but rather the current and past wheel co \ (\ frac {1} { 1- \ beta_1} = 10 \) average wheel gradient.
Understanding about the moving average, you can refer to my previous blog: understanding Moving Average (Exponential Moving Average) .
Adam + learning rate decay
There is a question on StackOverflow Should WE do for ADAM Learning Decay Rate Optimizer - Stack Overflow , I have thought about this problem, these methods Adam adaptive learning rate, but also should not be learning rate decay?
I simply did an experiment, training LeNet-5 model on cifar-10 data sets, using a learning rate decay tf.keras.callbacks.ReduceLROnPlateau (patience = 5), the other not. Adam and optimizer to use the default parameters, \ (\ = ETA from 0.001 \) . The results are as follows:
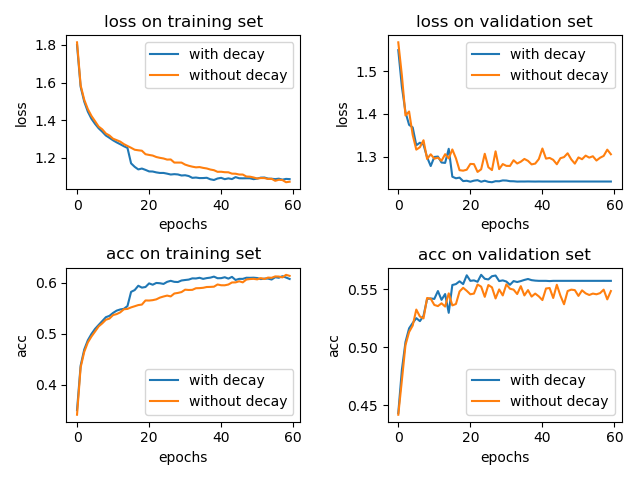
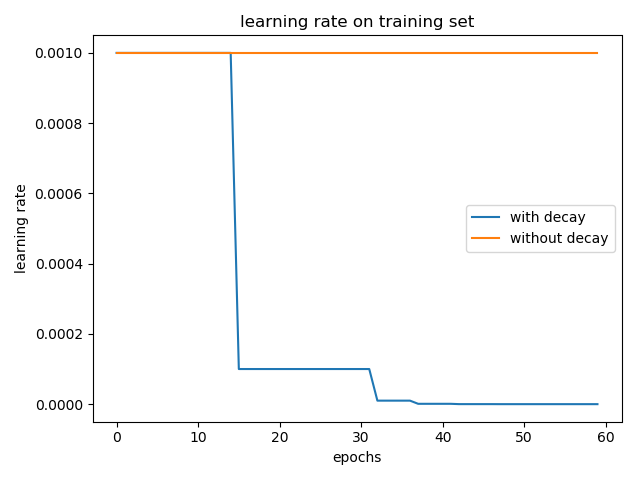
Join the learning rate and without attenuation accuracy in both cases the test collection are: 0.5617 and 0.5476. (The results took a chance on average, the experimental results of the two is still there)
By a small experiment above, we can know, the learning rate decay or useful. (Of course, small experiments where only represents a small part of the case, I want to explain the learning rate decay hundred percent effective, and must have proved theoretically.)
Of course, when you set the parameters you can reduce the super \ (\ eta \) value so that the learning rate decay can not achieve good results.
The learning rate change from the default 0.0001 0.001, epoch increased to 120, the experimental results are shown below:
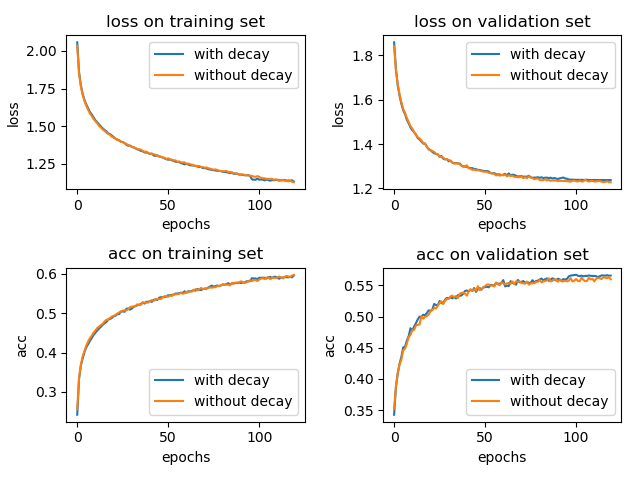
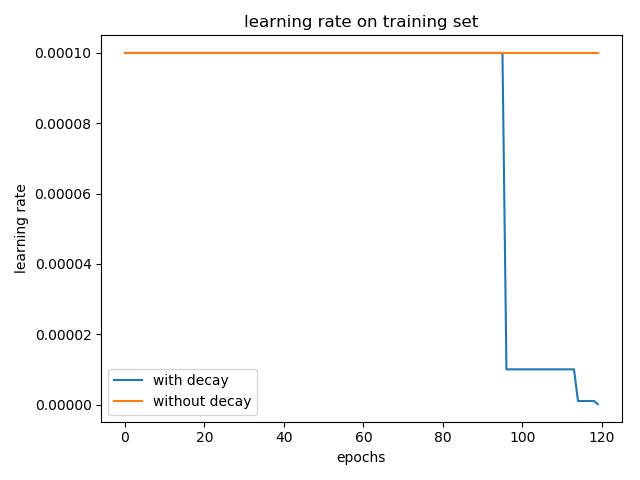
Join the learning rate and without attenuation accuracy in both cases the test collection are: 0.5636 and 0.5688. (Average of three experiments, the experimental results are still contingent)
This time, affect the learning rate decay brought about may be small.
So the question is, Adam did not learn attenuation rate it?
Personally, I would choose to do the learning rate decay. (Only reference to it.) Set in larger when initial learning rate, do not do better than the learning rate decay; and when the initial learning rate is set relatively small, do the learning rate decay seems a bit redundant, but val set effect on the look, made the learning rate decay can still have a little bit of improvement.
ReduceLROnPlateau 在 val_loss 正常下降的时候,对学习率是没有影响的,只有在 patience(默认为 10)个 epoch 内,val_loss 都不下降 1e-4 或者直接上升了,这个时候降低学习率确实是可以很明显提升模型训练效果的,在 val_acc 曲线上看到一个快速上升的过程。对于其它类型的学习率衰减,这里没有过多地介绍。
Adam 衰减的学习率
从上述学习率曲线来看,Adam 做学习率衰减,是对 \(\eta\) 进行,而不是对 \(\frac{\eta}{\sqrt{\hat{v}_{t}}+\epsilon}\) 进行,但有区别吗?
学习率衰减一般如下:
exponential_decay:
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)natural_exp_decay:
decayed_learning_rate = learning_rate * exp(-decay_rate * global_step / decay_steps)ReduceLROnPlateau
如果被监控的值(如‘val_loss’)在 patience 个 epoch 内都没有下降,那么学习率衰减,乘以一个 factor
decayed_learning_rate = learning_rate * factor
这些学习率衰减都是直接在原学习率上乘以一个 factor ,对 \(\eta\) 或对 \(\frac{\eta}{\sqrt{\hat{v}_{t}}+\epsilon}\) 操作,结果都是一样的。
References
An overview of gradient descent optimization algorithms -- Sebastian Ruder
Should we do learning rate decay for adam optimizer - Stack Overflow
Tensorflow中learning rate decay的奇技淫巧 -- Elevanth