Warmly recommended: Super Multi IT resources, all in 798 Resource Network
Disclaimer: reprint article, do so in order to prevent the loss of this backup.
This article from the public number: Ctrip Technology Center (ID: ctriptech)
Original Address: https://mp.weixin.qq.com/s/F7WTNeC3OUr76sZARtqRjw
First, the background
A distributed architecture, a unique serial number is generated we design a system, especially in sub-library sub-table database use often when the problems encountered. When divided into several sharding tables, how to quickly get a unique serial number, it is frequently encountered problems.
Ctrip account MySql database migration process, we carry out a new program designed to generate user ID, it requires the ability to support existing Ctrip new user registration body mass.
This article achieve Ctrip User ID generator through, hope to have some new ideas for you design unique id sub-library sub-table.
Second, the characteristics of demand
全局唯一
支持高并发
能够体现一定属性
高可靠,容错单点故障
高性能
Third, the industry program
There are many ways to generate the ID, to accommodate different scenarios, requirements and performance requirements.
Common methods are:
1, using the database incrementally, the only full database.
Advantages: clear and controllable.
Cons: single table in one database, database pressure.
2, UUID, generating a string of 32 hexadecimal format length =, if the backoff byte array of 16 byte elements, i.e. UUID is a 128bit long number, typically hexadecimal notation.
Benefits: to reduce the pressure on the database.
Cons: But how do sort?
There are also UUID variant, adding a splice time, but will result in very long id.
3, twitter during the storage systems to migrate from MySQL to Cassandra Cassandra is not in order because the ID generation mechanism, then himself developed a globally unique ID generation service: Snowflake.
141 bit time-series (to the millisecond and 41 bits long may be used 69 years)
2 10-bit machine identification (length 10 up to support the deployment of 1024 nodes)
312-bit count sequence number (12-bit count generating sequence number 4096 per millisecond support ID number) of each node of the highest bit is a sign bit, is always 0.
Advantages: High-performance, low-latency; independent application; chronological order.
Cons: requires a separate development and deployment.
4, Redis generation ID
When the ID is generated when performance is not required to use the database, we can try to use Redis to produce ID. Depending mainly on the Redis is single-threaded, so it can be used to generate a globally unique ID. INCR atomic operation can be realized and INCRBY Redis.
You can use Redis cluster to obtain higher throughput. If a cluster has five Redis. You can initialize each value Redis 1,2,3,4,5 respectively, and then the step is 5. Redis generated ID for the respective:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
More suitable for daily use Redis to generate a serial number starting from 0. Such as order number = Date + day since growth numbers. Key may be generated each day in a Redis using INCR accumulated.
advantage:
It does not depend on a database, flexibility, and superior performance database.
Digital ID natural sorting, pagination or the results need to sort helpful.
Redis cluster using single point of failure can be prevented.
Disadvantages:
If the system does not have the Redis, we need to introduce new components, increasing system complexity.
Require coding and configuration workload is relatively large, multi-environment operation and maintenance is very troublesome,
At the beginning of the program to which the load instance instance redis Once good, the future is difficult to make changes.
5. Flicker solutions
Because MySQL auto_increment operations support itself, naturally, we think take advantage of this feature to achieve this function.
Flicker in solving global ID generation scheme in on the use of self-growth mechanism MySQL ID's (auto_increment + replace into + MyISAM).
6. There are other programs, such as Jingdong Taobao electricity supplier order number generation. Because the order number and user id difference in service, order number as business wants to have more redundant information, such as:
And pieces: the start number + time + license plate number
Taobao Order: timestamp + user ID
Other electricity providers: + timestamp + single-channel user ID, order ID will add some first goods.
The user ID, the required meaning simple, registered channels can contain, as short as possible.
Fourth, the final plan
Ultimately, we chose to flicker to optimize the improvement program is based. Concrete realization, single table increments, memory cache way number segment.
First, the establishment of a table, like this:
SEQUENCE_GENERATOR_TABLE
id stub
1 192.168.1.1
Where id is auto-incremented, stub server ip
Because the new database using mysql, mysql so unique syntax to use to replace to update records to obtain a unique id, such as this:
REPLACE INTO SEQUENCE_GENERATOR_TABLE (stub) VALUES ("192.168.1.1");
And then SELECT id FROM SEQUENCE_GENERATOR_TABLEWHERE stub = "192.168.1.1";get it back.
Until the above, we are only generated on a single database ID, considered from the perspective of high availability, the next step is to solve the single point of failure.
This is why we need this machine ip field it? It is to prevent multiple servers simultaneously update data, questions retrieved id confusion.
So, when multiple servers, this table is as follows:
id stub
5 192.168.1.1
2 192.168.1.2
3 192.168.1.3
4 192.168.1.4
Each piece of the server only update their records to ensure that the single-threaded operating single-line records.
At this time each machine to get are 5,2,3,4 four id.
So far, we seem to solve the problem this server isolation, atomicity get id, but also basically the same program and flicker.
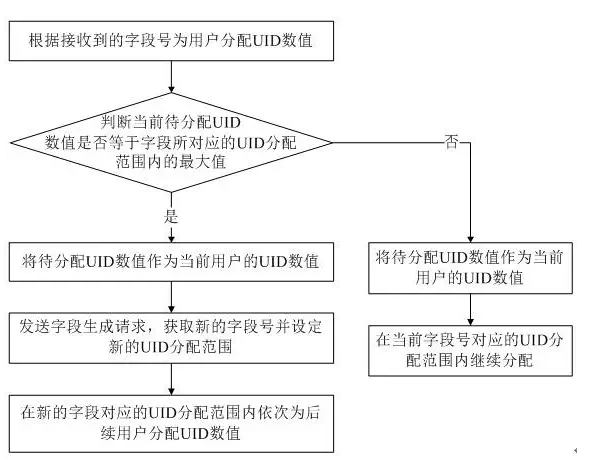
But the root, in principle, programs or rely on characteristics of the database, each request must be generated id db, large overhead. We are yet to optimize this segment id as a number, and not to be issued to the serial number, and this number is configurable segment length, 1000 may be 10000, which is to take back the id enlarge how many times the question.
OK, we operate a query from DB overhead, get back 1000 in memory of the user id.
The problem now is to solve the same server in a high concurrency scenarios, so that we get the order number, repeat not take, do not take a leak.
The question simply, is a problem of maintaining isolation of the target segment number.
AtomicLong is a reliable way.
When the first number back segment id, by 1000, and then assigned to the variable atomic, this is the first number the number of segments.
atomic.set(n * 1000);
And maximum memory to save what id, which is the last segment of this number a number
currentMaxId = (n + 1) * 1000;
A number segment is formed.
At this time, every time there is a request to take a number, a judgment to the last there is no number, not to, took a number, leave.
Long uid = atomic.incrementAndGet();
If you reach the last number, then blocking other requests live thread, the first thread to db that takes a paragraph, and then update the look of two values number segment on it.
The program, core logic less than 20 lines of code to solve the problem of distributed system serial number generated.
There is a small problem, that is, after the server is restarted, because the numbers are cached in memory, wasted part of the user ID is not sent out, so the application may be frequently released, to minimize the number segment amplification step size n, can be reduced waste.
After practice, the performance improvement is far more important than wasting part id.
If we pursue the ultimate, can destroy event listener spring or servlet context, the current saved to the upcoming issue of user ID, the next time you start again when the memory can be salvaged.
Fifth, the effects of line
Run over five months, very stable.
SOA services average response time of 0.59 ms;
The client calls the average response time of 2.52 ms;
Attached Flowchart: