A presentation, Fork / Join framework
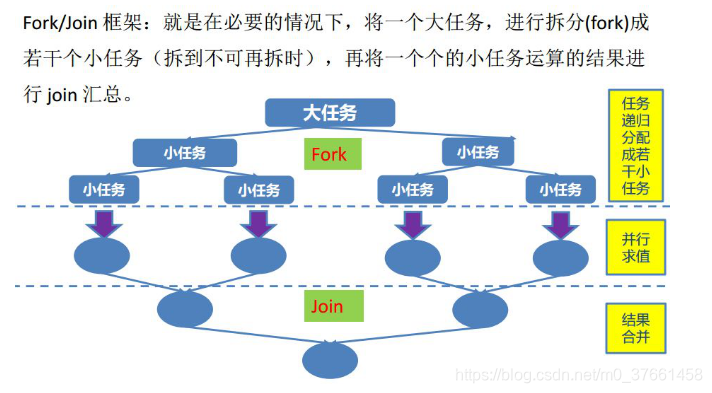
Fork / Join framework Java7 provide a framework for parallel execution of a task is a big task dividing the task into several small, to obtain a large frame final summary results of the task results after each small task. Let us be understood by Fork and Join the two words at Fork / Join framework, Fork is to cut a large task into several sub-tasks in parallel execution, execution Join the merger is the result of these subtasks, and finally got this big task result. Calculation example 1 + 2 +. . +10000, 10 may be divided into sub-tasks, each sub-task separately summing the number of 1000, the final summary of the results of these 10 sub-tasks.
Run flowchart Fork / Join follows:
1, implementation steps:
-
The first step in segmentation tasks. ** First, we need to put a fork like split large tasks into subtasks, there may subtasks is still very large, so it needs to keep the division until the divided sub-tasks small enough.
-
The second step tasks and merging the results. ** split sub-tasks were placed in a double-ended queue, then start several threads are acquired from the double-ended task execution queue. The results of executing the subtasks are united in a queue, start a thread to get data from the queue, and then merge the data.
Fork / Join to use two classes to complete the above two things:
ForkJoinTask: we want to use ForkJoin frame, you must first create a ForkJoin task. It provides a fork in the task () and join () operation mechanism, usually we do not need the direct successor to ForkJoinTask class, but only need to inherit its subclasses, Fork / Join framework provides the following two sub-categories:
RecursiveAction: He did not return for the results of the task.
RecursiveTask: There used to return the results of the task.
ForkJoinPool: ForkJoinTask need to be performed by ForkJoinPool, task segmented sub-tasks will be added to the current worker threads maintained double-ended queue, into the head of the queue. When a worker thread queue currently have no job, it will randomly get a service from the tail of another worker thread queue.
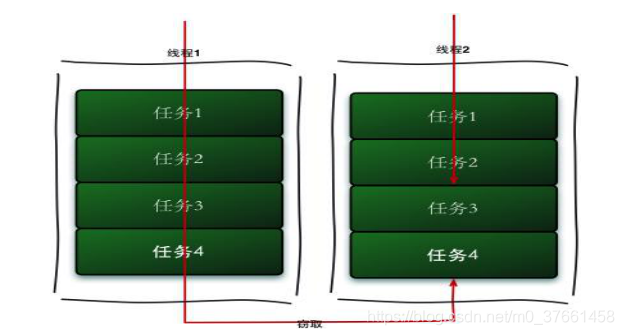
2, work-stealing algorithm
Work stealing (work-stealing) algorithm means a thread queue stolen from other tasks to perform. Operational flowchart showing the operation to steal the following:
Why use work-stealing algorithm it?
- If we have to do a large task, we can put this task into a number of non-dependent sub-tasks, in order to reduce competition among threads, so these subtasks are placed in different queue and for each queue create a separate thread to perform the task queue, the queue threads and correspondence, such as a thread is responsible for handling a queue of tasks.
But some thread will put its own task queue finish, while the other threads as well as the corresponding task queue waiting to be processed. The work was done instead of waiting threads, it is better to help other thread work, then it will go to other threads queue steal a task to perform. And at this time they access the same queue, so in order to reduce theft and stolen the task thread competition between the task threads, often using double-ended queue, the task thread never get stolen from the head deque task execution, the theft task thread never take the task execution from the end of double-ended queue.
Advantages work-stealing algorithm is thread take advantage of parallel computing, and reduce competition between threads, which is a disadvantage in some cases there is still competition, such as the two ends of only one task queue. And consume more system resources, such as creating multiple threads and multiple double-ended queue.
3, divide and rule
Meanwhile fork-join is very useful when dealing with a certain type of problem, what kind of problems? Divide and conquer the problem. Ten classic computer algorithms: quick sort, heap sort, merge sort, binary search, linear search, depth-first, breadth-first, Dijkstra, dynamic programming, naive Bayes classifier, a few belong to divide and conquer? Of which three, quick sort, merge sort, binary search, as well as large data M / R are based on the idea of divide and rule.
Design philosophy of divide and conquer is: a big problem difficult to directly solve, divided into a number of smaller scale the same problems, so that each break, divide and rule.
Divide and conquer strategy is: for a problem of size n, if the problem can be easily solved (such as small-scale n) directly addressed, otherwise it will break down into k smaller sub-problems, each of these sub-problems independent and the same form as the original problem (the link between each sub-problem will become a dynamic algorithm specification), solutions of these sub-problems recursively, and then the solutions were combined to give the sub-problem solution of the original problem. This algorithm design strategy is called divide and conquer.
3.1 merge sort
Merge sort merge operation is based on an efficient sorting algorithm. The algorithm is a very typical application using divide and conquer method. The combined sequence has been ordered, fully ordered sequence; i.e., each first ordered sequence, and then ordered to make inter-segment sequences.
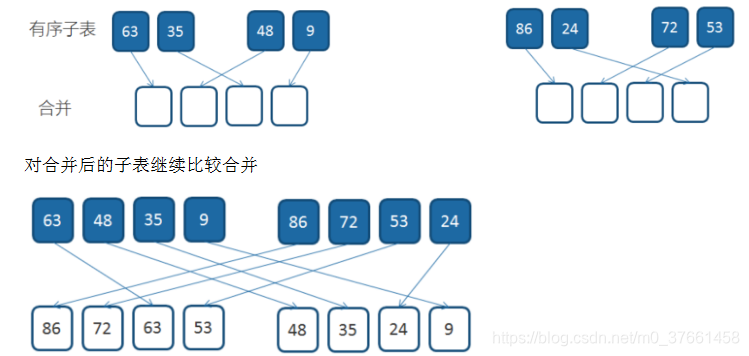
If two merged into a sorted list ordered list, called 2-way merge, as well as the corresponding merge multiplexer. For a given set of data, the partition recursive techniques and data divided into a sequence of increasingly smaller half sub table, were combined in a latter half sub table of sorted, then the method of recursive half sub sorted table becomes more and more of an orderly sequence. To improve the performance, we sometimes less than the number in the case where a half sub-table number (such as 15), sorting the table by other half sub-sort algorithm, such as the insertion sort.
Merge (descending) Examples

of ordered sub-list sorting and comparing combined
4, the standard paradigm Fork / Join used
We want to use the Fork-Join framework, you must first create a Fork-Join Task. It provides execution in the task fork and join operation mechanism, usually we do not inherit directly ForkjoinTask class, just directly following the Cheng Qizi class.
- RecursiveAction, did not return for the results of the task
- RecursiveTask, the task for the return value of
Task to be performed by ForkJoinPool, use or invoke submit submit, the difference is: invoke synchronization is performed after the call to wait for the task to complete to perform later in the code; submit is executed asynchronously .
public static void main(String[] args) { // 创建ForkJoinPool来执行任务 ForkJoinPool pool = new ForkJoinPool(); int[] src = MakeArray.makeArray(); // 创建fork-join任务 SumTask innerTask = new SumTask(src, 0, src.length-1); long start = System.currentTimeMillis(); // invoke是同步执行,调用之后需要等待任务完成,才能执行后面的代码 pool.invoke(innerTask); //使用join方法会等待子任务执行完并得到其结果 result = innerTask.join(); int result = innerTask.join(); System.out.println("The count result is: "+result+" spend time:"+(System.currentTimeMillis()-start)+"ms"); }
join () method and get the return when the task is completed the results.
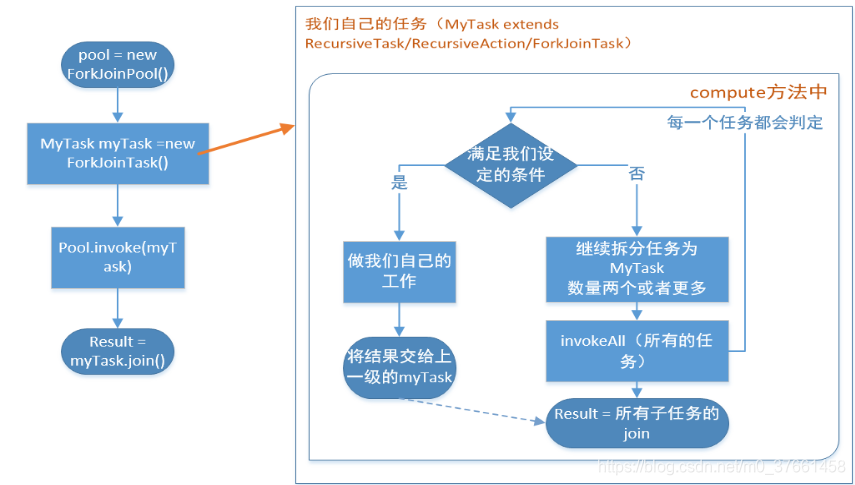
In the compute method implemented in our own, we first need to determine whether the task is small enough, if small enough to directly perform the task. If not small enough, it must be divided into two sub-tasks, each sub-task when calling invokeAll method, will enter compute way to see whether the current sub-task needs to continue into Sun task, if you do not continue to split, then the execution of the current subtasks and returns the result. Use join method waits to perform subtasks finish and get the results.
@Override
protected Integer compute() {
// 首先判断任务是否足够小,如果足够小就直接执行任务
if(toIndex-fromIndex < THRESHOLD) {
// 将任务结果交给上一级
int count = 0;
for(int i = fromIndex; i<= toIndex; i++) {
SleepTools.ms(1);
count = count + src[i];
}
return count;
}else { //
int mid = (fromIndex + toIndex) / 2;
SumTask leftTask = new SumTask(src, fromIndex, mid);
SumTask rightTask = new SumTask(src, mid+1, toIndex);
// 任务拆分完城后调用invokeAll()方法将子任务放进去,继续计算判断是否需要再次拆分,直到拆分达到阈值
invokeAll(leftTask,rightTask);
// 返回计算结果
return leftTask.join() + rightTask.join();
}
}
5, exception handling Fork / Join framework
ForkJoinTask in the course of implementation may throw an exception, but we can not directly catch the exception in the main thread, so ForkJoinTask provides isCompletedAbnormally () method to check whether the task has been thrown or had been canceled, and through the ForkJoinTask getException method to get an exception. Use the following code:
IF (task.isCompletedAbnormally ())
{System.out.println (task.getException ());}
the getException method returns Throwable object, if the task has been canceled CancellationException is returned. If the task is not complete or is not thrown null is returned.
6. The principle Fork / Join Framework
ForkJoinPool by the ForkJoinTask and ForkJoinWorkerThread array of arrays, array ForkJoinTask responsible for storing programs submitted to the ForkJoinPool task, and ForkJoinWorkerThread array responsible for carrying out these tasks. ForkJoinTask way to achieve the fork principle: when we call fork method ForkJoinTask, the program calls the method asynchronously pushTask ForkJoinWorkerThread to perform this task and returns the result immediately.
JDK1.8 code is as follows:
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
push method to put the current task to the task queue inside, then call signalWork method ForkJoinPool wake-up or create a thread to perform tasks
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a; ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {
if ((p = pool) != null)
p.signalWork(p.workQueues, this);
}
else if (n >= m)
growArray();
}
}
JDK1.7 code is as follows:

the Join method ForkJoinTask implementation principle. The main role of the Join method of the current thread is blocked and waiting to acquire the results. Let's look at the implementation method ForkJoinTask join together, as follows:
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
private void reportException(int s) {
if (s == CANCELLED)
throw new CancellationException();
if (s == EXCEPTIONAL)
rethrow(getThrowableException());
}
JDK1.7 implementation:
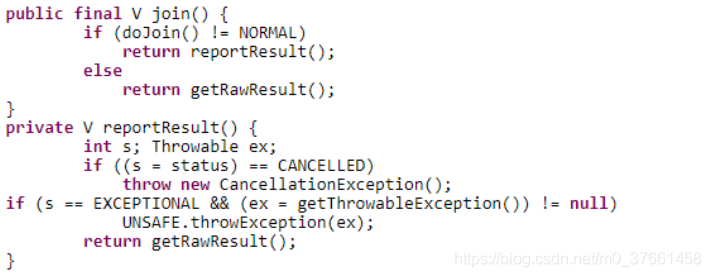
First, it calls doJoin () method () method to get the current task status by doJoin return to judge what the outcome, there are four task status:
Completed (NORMAL), is canceled (CANCELLED), signal (SIGNAL) and abnormal (EXCEPTIONAL).
- If the job status is completed, the result of a direct return to the task.
- If the task status is canceled, direct throw CancellationException.
- If the task status is thrown, then the corresponding direct throw an exception.
Let's analyze the implementation code under doJoin () method JDK1.8:
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
return (s = status) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(w = (wt = (ForkJoinWorkerThread)t).workQueue).
tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0L) :
externalAwaitDone();
}
JDK1.7 to achieve the following:

in doJoin () method, the first by looking at the status of the task, to see whether the task has been carried over, if the execution is over, simply return the task status, if not executed, removed from the task and the task array carried out. If the task is executed successfully completed, then set the task status is NORMAL, if an exception occurs, an exception record, and task status is set to EXCEPTIONAL.
Second, blocking CountDownLatch
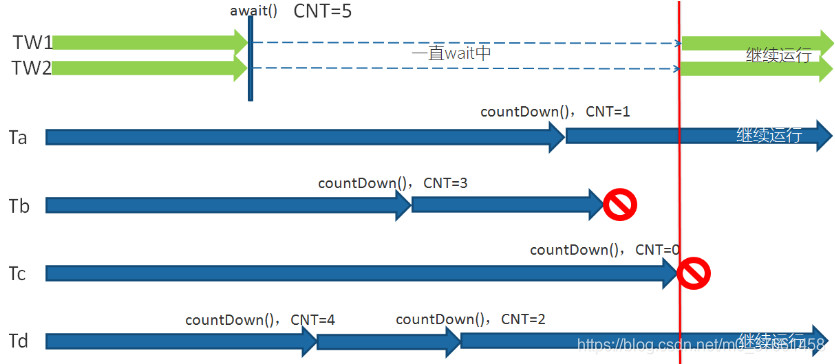
Lockout CountDownLatch This class enables the implementation of a thread waiting for other threads to complete their work before. For example application's main thread of hope again after the thread is responsible for starting the implementation of the framework service has been launched in the framework of all the services.
CountDownLatch, the initial counter value of the number of initial tasks accomplished by a counter. Whenever a task is completed, the counter value will be minus 1 (CountDownLatch.countDown () method). When the counter value reaches zero, it indicates that all tasks have been completed, and then wait CountDownLatch.await on lockout () method of the thread can resume execution tasks.
1, application scenarios
For maximum parallelism: Sometimes we want to start multiple threads to achieve the greatest degree of parallelism. For example, we want to test a singleton class. If we create an initial count of CountDownLatch 1, and to let all threads waiting on the lock, then we can easily complete the test. We just call
once countDown () method can make all the waiting threads resume execution.
N threads waiting to complete their tasks before starting: the application starts, for example, to ensure that the class before processing user requests, all of the N external system has been up and running, for example, process multiple forms in excel.
See the code package cn.enjoyedu.ch2.tools
2、CyclicBarrier
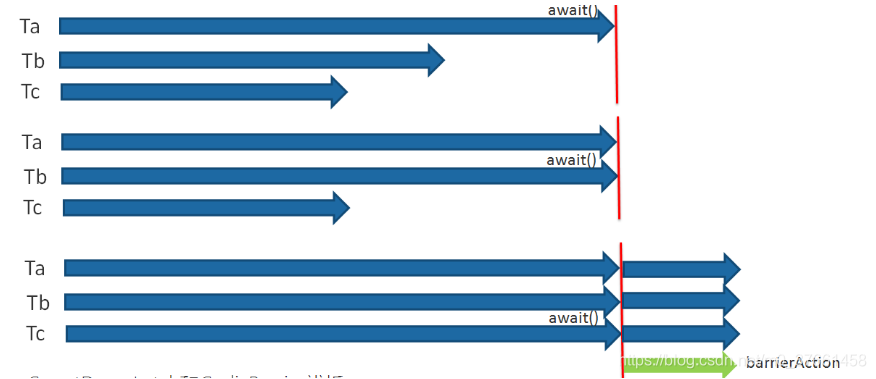
CyclicBarrier literally means can be reused (Cyclic) barrier (Barrier). It needs to be done is to let a group of threads reach a barrier (also called synchronization point) is blocked when it until the last thread reaches the barrier, the barrier will open the door, all barriers blocked thread will continue to run.
CyclicBarrier default constructor is CyclicBarrier (int parties), its parameter indicates the number of threads barrier to intercept each thread calls await method tells CyclicBarrier I have reached the barrier, then the current thread is blocked.
CyclicBarrier also offers a more advanced constructor CyclicBarrier (int parties, Runnable barrierAction) , used in the thread reaches the barrier, take precedence barrierAction, easy to handle more complex business scenarios.
CyclicBarrier can be used for multi-threaded computing data, the combined results of the last scene.
CountDownLatch and CyclicBarrier Analysis:
- CountDownLatch counter can only be used once, and CyclicBarrier counter can be used repeatedly.
- CountDownLatch.await generally blocked worker threads, all threads of execution countDown preparatory work carried out, and thus CyclicBarrier own work by blocking calls await thread until all worker threads reaches the specified barrier, and then we go down together.
- Controlling the plurality of threads running simultaneously, a CountDownLatch may not be limited number of threads, and a fixed number of threads is CyclicBarrier.
- Meanwhile, CyclicBarrier can also provide a barrierAction, merge multi-threaded calculations.
3、Semaphore
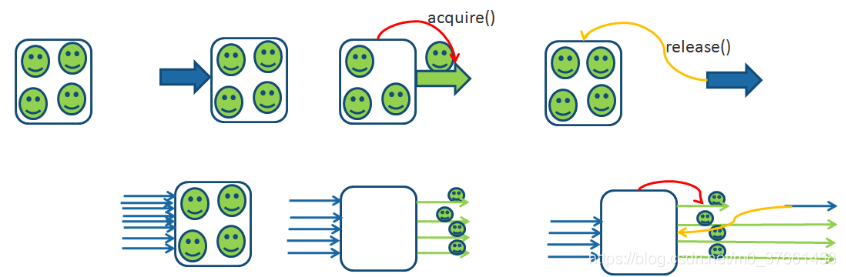
Semaphore (Semaphore) is used to control the number of threads simultaneously access a particular resource, which through the coordination of the various threads, in order to ensure rational use of public resources. Semaphore scenarios can be used to do traffic control, in particular, with limited public resources application scenarios, such as database connection. If there is a need to read tens of thousands of data files, as are the IO-intensive tasks, we can start to read dozens of concurrent threads, but if read into memory, also need to be stored in the database, and the number of connections to the database only 10, then we have to control only 10 threads simultaneously save the database connection data, otherwise it will error unable to get database connection. This time, you can use Semaphore to do flow control.
Semaphore Constructor Semaphore (int permits) accepts an integer number representing the number of licenses available. Semaphore usage is also very simple, first of all threads of Semaphore acquire () method to get a license, call the release () method to return the license after use. You can also use tryAcquire () method attempts to obtain a license.
Semaphore provides other methods, as follows.
- intavailablePermits (): Returns the number of licenses in this semaphore currently available.
- intgetQueueLength (): Returns the number of threads that are waiting to obtain a license.
- booleanhasQueuedThreads (): whether any threads are waiting to acquire a license.
- void reducePermits (int reduction): to reduce the reduction licenses, is a protected method.
- Collection getQueuedThreads (): Returns the collection of all the threads waiting to acquire a license, it is a protected method.
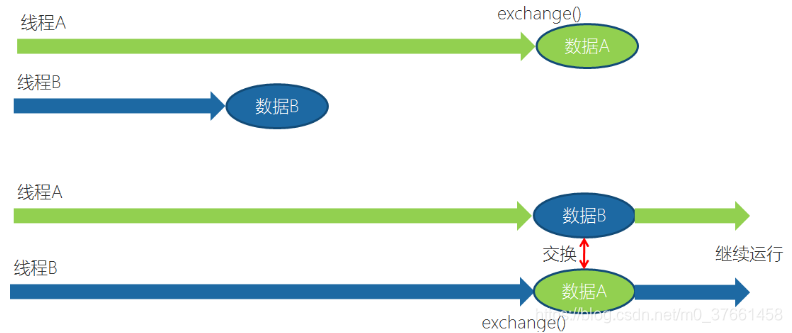
4、Exchange:
Exchanger (exchanger) is a class tool for collaboration between threads. Exchanger for exchanging data between threads. It provides a synchronization point, in this synchronization point, two threads can exchange data with each other. These two threads to exchange data exchange method, if the first thread to execute exchange () method, which has been waiting for a second thread also performs exchange method, when two threads have reached the synchronization point, these two threads data can be exchanged, passing this thread produced data to each other.
5、Callable、Future和FutureTask
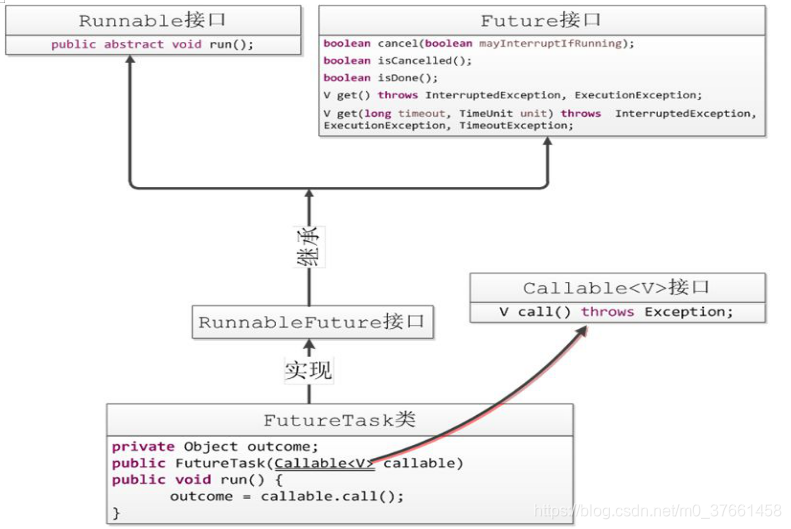
Runnable is an interface, in it only declares a run () method, due to the run () method returns a value of type void, so I can not return any results after performing the task.
Callable located at java.util.concurrent package, it is also an interface in it only declares a method, but this method is called call (), which is a generic interface, call () function returns the type of transfer is come in V type.
Future is for the specific results of the implementation Runnable or Callable task to cancel the query is complete, get results. The results can be obtained by get methods, if necessary, the method blocks until the task returns the result.

FutureTask RunnableFuture class implements an interface, RunnableFuture inherits the Runnable interface and Future interfaces, and FutureTask achieved RunnableFuture interface. It can therefore be executed as a thread Runnable, but also as Future Callable get the return value.
So we Callable by a thread running, but does not support the Thread constructor passed Callable instance, so we need to put a FutureTask Callable packed into Runnable, and then get the return value of the Callable run through this FutureTask. FutureTask to a new instance, there are two methods
Third, the atomic operation CAS (compare atomic swap)
1. What is an atomic operation? How to achieve atomic operation?
Assuming two operations A and B, if A thread of execution from the point of view, when another thread B executed, or after executing all of the B or B is not performed, then A and B are atoms for each other .
Atomic operations can be achieved using the lock, the lock mechanism to meet the basic needs is not a problem, but sometimes we need is not so simple, we need to be more efficient, more flexible mechanism, synchronized keyword lock mechanism is based on blocking, that is when a thread has a lock, other threads access the same resources need to wait until the thread releases the lock.
- There will be some questions:
- First, if the blocked thread a high priority it is important how to do?
- Secondly, if a thread to acquire the lock does not release the lock has been how to do? (This situation is very bad).
- In another case, if a large number of threads to compete for resources, and that the CPU will spend a lot of time and resources to deal with competition, while there are a number of circumstances such as deadlocks and the like may occur.
- Finally, the lock mechanism is in fact a relatively coarse particle size larger mechanism with respect to counter demands like a bit too bulky.
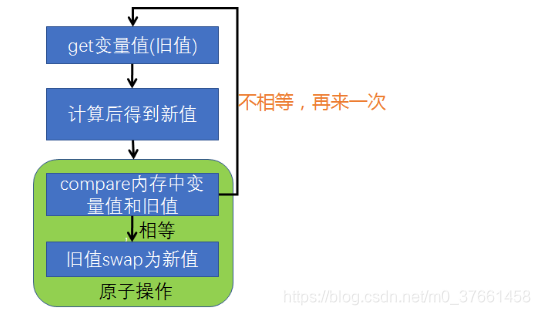
- Atomic instruction operation may also be used to achieve this basic support CAS processor (), except that the algorithm implemented by each manufacturer is not the same, each comprising three operations during CAS operator: a memory address V, a a desired value and when a new value B, if the value stored in the operation of this address is equal to the expected value of a, the value of the address is assigned to the new value B, otherwise it does nothing.
- CAS basic idea is that, if the values and expectations on this address values are equal, to give new value to it, otherwise do not do any thing, but to return to the original value is. CAS is circulating in a loop constantly do cas operation until it succeeds.
- CAS is how to achieve security thread of it? Language level do nothing, we will give it -CPU hardware and memory, using a multi-CPU processing power to achieve blocking hardware level, coupled with volatile variable characteristics can be realized based on atomic thread-safe operations.
2, CAS atomic operation to achieve three major problems
2.1 ABA problem
因为CAS需要在操作值的时候,检查值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。
Solutions ABA problem is to use a version number. In front of the additional variable version number, each time the variable update version number is incremented by 1, then A → B → A becomes 1A → 2B → 3A. For example popular point, you pour a glass of water put on the table, did something else, and then you drink a colleague gave you back a glass of water, you still come back to see the water, get up to drink If you drink water is the middle no matter who only care about the water still, this is the ABA problem.
If you're a hygiene and civilized young man, he is not only concerned with water, but also when you leave the water was moving too did not, because you are a programmer, so I think put a piece of paper next to, write The initial value of 0, drink plenty of water before someone else the trouble to be accumulated in order to drink water.
Long cycle time overhead of large, long spin CAS if successful, will bring a very large CPU execution cost.
A shared variable can only guarantee atomic operations:
When performing operations on a shared variable, we can use the CAS cycle approach to ensure an atomic operation, but when multiple shared variables operating cycle CAS can not guarantee atomic operations, this time you can use the lock.
There is also a tricky way, is to merge multiple shared variables into a shared variable to operate. For example, there are two shared variables i = 2, j = a, merge at ij = 2a, and to operate with CAS ij. Starting from Java 1.5, JDK classes AtomicReference provided to ensure the reference atom between objects can be variable in the plurality of objects in a CAS operation is performed.
2.2 Jdk use atomic operations related classes
AtomicInteger use:
- int addAndGet (int delta): Numerical Example Atomically input value (inside of AtomicInteger value) are added, and returns the result.
- of compareAndSet Boolean (Expect int, int
Update): If the input value is equal to the expected value Atomically set the value of the input value. - int getAndIncrement (): Atomically current value plus 1, note that this is the return value before increment.
- int getAndSet (int newValue): atomically newValue set to a value of, and return the old value. AtomicIntegerArray
The main way to provide atomic update integer array, which is used as follows.
- int addAndGet (int i, int delta): atomically input values to the array element at index i is added.
- boolean compareAndSet (int i, int expect, int update): If the current value is equal to the expected value, the elements of the array Atomically i is set to update the position values.
Note that, by constructing an array of value passed into the method, then AtomicIntegerArray will present a copy of the array, so when AtomicIntegerArray array element internal modifications will not affect the incoming array.
Update reference types: AtomicReference
Atomic update basic types of AtomicInteger, can only update a variable, if you want to update multiple atomic variables, you need to use this class reference type atomic updates provided. Atomic package provides the following three classes.
AtomicStampedReference:
The version number recorded after each change of use version of the stamp of the form, so the problem would not exist ABA. This is AtomicStampedReference solutions.
AtomicMarkableReference with AtomicStampedReference almost, AtomicStampedReference use int stamp pair is used as a counter, AtomicMarkableReference the pair using boolean mark. Or examples of the water, AtomicStampedReference may be concerned that the move several times, AtomicMarkableReference concern is not being moved, methods are relatively simple.
AtomicMarkableReference:
With atomic update reference type flag may be a Boolean type atomic update flag and reference types. Constructor is AtomicMarkableReference (V initialRef, booleaninitialMark).
Atomic update field class:
If the need to update a field of a class of atoms, the atoms need to use field-based update, Atomic package provides the following three classes atoms field update. To update atomically field class requires two steps. The first step, because the atomic update field classes are abstract classes, each time using a static method used must newUpdater () to create an updater, and the need to set up classes and attributes you want to update. The second step, updating the class field (attribute) must use public volatile modifier.
AtomicIntegerFieldUpdater: atomic update updater integer field.
AtomicLongFieldUpdater: atomic update updater long integer field.
AtomicReferenceFieldUpdater: atomic update reference types in the field.