First, the atomic operation CAS - LongAdder
When JDK1.8, java.util.concurrent.atomic package provides a new class of atoms: LongAdder. According to official documents of Oracle, LongAdder in a highly concurrent scenarios than its predecessor --AtomicLong better performance at the expense of consuming more memory space. AtomicLong is the use of the underlying CAS is operable to provide concurrency, called getAndAddLong method Unsafe class, which is a native method, which logic is updated using the target spin way, until the update is successful.
At a lower amount of concurrent environment, the probability of thread conflict is relatively small, the number of spins will not be many. However, a highly concurrent environment, N threads simultaneously spinning operation, the situation is a lot of failure and continue to spin appears, at this time AtomicLong spin will become a bottleneck. This is LongAdder introduced the original intention - to solve the bottleneck problem AtomicLong spin at high concurrency environments.
There are internal variables in AtomicLong value holds the actual value of the long, all operations are carried out for the variable. In other words, a highly concurrent environment, value variable is actually a hot spot, which is a hot competition N threads.
private final long value;
- The basic idea is to disperse LongAdder hot, the dispersion value value into an array, will hit different threads to different slots of the array, each thread only for the value of their own tank CAS operations carried out so hot it was dispersed, conflict the probability is much smaller. If you want to get a real long value, as long as the cumulative value of the variable each tank return. This approach and the ConcurrentHashMap "segment lock" is actually similar lines.
- LongAdder API provided AtomicLong and close, both of which can be increased or decreased in a manner of atoms long variable. But the functionality provided by AtomicLong actually richer, especially addAndGet, decrementAndGet, compareAndSet these methods.
- addAndGet, decrementAndGet addition to simply do increment decrement, you can also get the value immediately after the increase or decrease, and LongAdder synchronization control needed to be done in order to obtain accurate values increase or decrease. Compare count if business needs require precise control of the counting, do, AtomicLong more appropriate. In addition, from space considerations, LongAdder is actually a "space for time" thinking, from this point of view AtomicLong more suitable.
- In short low concurrency, the general business scenario AtomicLong is enough. If a lot of concurrency, the presence of a large number of write once read many small, LongAdder it may be more appropriate. The right is the best, if you really need to consider in the end there was a good AtomicLong or LongAdder business scenarios, then this discussion is pointless, because either a performance test in this case, in order to accurately assess the current business scene under performance of the two, or a change in thinking to seek other solutions.
For LongAdder, the base has an internal variable, the Cell a [] array.
variable base: non-race condition, directly onto the accumulation variable.
Array Cell []: under race conditions, accumulating a groove their respective threads Cell [i] in.
transient volatile Cell[] cells;
transient volatile long base;
So, calculate the final result should be:
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
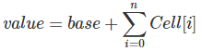
In actual use, when only never had a concurrency violation when, base to base will be used, once there has been complicated by the conflict, after all operations only for Cell [] cell Cell array.
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
The LongAdder final results are summed, and did not use the global lock, return value is not absolutely accurate, because there are other threads call this method may be in progress counts up, we can only give an approximation of a moment in time, which is LongAdder can not completely replace one of the reasons LongAtomic. And from the test situation, the more the number of threads, the greater the number of concurrent operations, the greater the LongAdder advantage, when a small number of threads, AtomicLong performance also exceeded LongAdder.
Second, other new
In addition to the newly introduced LongAdder, there are three brothers introduced its category: LongAccumulator, DoubleAdder, DoubleAccumulator. LongAccumulator LongAdder is an enhanced version. LongAdder only function values for the addition and subtraction, and provides a custom LongAccumulator operation. By LongBinaryOperator, you can customize the operation of any of the parameters, and returns the result (LongBinaryOperator receiving two long as a parameter, and returns a long).
LongAccumulator内部原理和LongAdder几乎完全一样。
DoubleAdder和DoubleAccumulator用于操作double原始类型。
1, Stamp Lock
StampedLock is a new locking mechanism Java8 introduced simply be appreciated that it is an improved version of read-write lock, although separated read and write write lock features so completely between the read and read concurrently, but between reading and writing is still conflicting read lock to write lock will be completely blocked, it still uses pessimistic locking strategy; if there are a large number of read threads, he may also cause hunger to write thread.
The StampedLock provides an optimistic reading strategies, this optimistic locking strategy is very similar to the lock-free operation so optimistic locking thread will not block writers. The idea is not only to read-write lock does not block read, write at the same time should not be blocked.
Read without blocking the realization of ideas to write:
When read if a write occurs, it should re-read rather than reading directly when blocking write! That does not block each other between read and write, write and write but still blocked between the internal StampedLock implementation is based on the CLH.
Reference Code:
public class StampedLockDemo {
// 一个点的x,y坐标
private double x,y;
// Stamped类似一个时间戳的作用,每次写的时候对其+1来改变被操作对象的Stamped值,这样其它线程读的时候发现目标对象的Stamped改变,则执行重读
private final StampedLock slock = new StampedLock();
/**
* 【写锁(排它锁)】
*/
void move (double deltaX, double deltaY) {
//tampedLock调用writeLock和unlockWrite时候都会导致stampedLock的stamp值的变化 即每次+1,直到加到最大值,然后从0重新开始
long stamp = slock.writeLock();
try {
x += deltaX;
y += deltaY;
}finally {
slock.unlockWrite(stamp);
}
}
/**
* 【乐观读锁】
*/
double distanceFromOrigin() {
// tryOptimisticRead是一个乐观的读,使用这种锁的读不阻塞写 , 每次读的时候得到一个当前的stamp值(类似时间戳的作用)
long stamp = slock.tryOptimisticRead();
// 这里就是读操作,读取x和y,因为读取x时,y可能被写了新的值,所以下面需要判断
double currentX = x, currentY = y;
/*
* 如果读取的时候发生了写,则stampedLock的stamp属性值会变化,此时需要重读,
* validate():比较当前stamp和获取乐观锁得到的stamp比较,不一致则失败。
* 再重读的时候需要加读锁(并且重读时使用的应当是悲观的读锁,即阻塞写的读锁)
* 当然重读的时候还可以使用tryOptimisticRead,此时需要结合循环了,即类似CAS方式
* 读锁又重新返回一个stampe值
*/
if(!slock.validate(stamp)) {//如果验证失败(读之前已发生写)
stamp = slock.readLock(); //悲观读锁
try {
currentX = x;
currentY = y;
}finally {
slock.unlockRead(stamp);
}
}
return Math.sqrt(currentX *currentX + currentY *currentY);
}
/**
* 读锁升级为写锁
*/
void moveIfAtOrigin(double newX, double newY) { // upgrade
// 读锁(这里可用乐观锁替代)
long stamp = slock.readLock();
try {
//循环,检查当前状态是否符合
while (x == 0.0 && y == 0.0) {
long ws = slock.tryConvertToWriteLock(stamp);
//如果写锁成功
if (ws != 0L) {
stamp = ws;// 替换stamp为写锁戳
x = newX;//修改数据
y = newY;
break;
}
//转换为写锁失败
else {
slock.unlockRead(stamp); //释放读锁
//获取写锁(必要情况下阻塞一直到获取写锁成功)
stamp = slock.writeLock();
}
}
} finally {
slock.unlock(stamp); //释放锁(可能是读/写锁)
}
}
}
2、CompleteableFuture
Future deficiencies: Future is the Java
. 5 added class used to describe the results of an asynchronous computation. You can use isDone method to check whether the calculation is completed, or live with get blocked calling thread until the calculation is complete return the results, you can also use the cancel method to stop performing a task.
Although the Future and the associated use of asynchronous method provides the ability to perform tasks, but to get results is very convenient, the task can only get the results by polling or blocking the way. Blocking the way is clear and our asynchronous programming contrary to the original intention, by way of polling will consume unnecessary CPU resources, and can not get timely results, why not complete when the results promptly notify the listener with observer design pattern it?
Some Java frameworks, such as Netty, himself extends the Java interface to the Future, a plurality of extension methods addListener etc., Google guava also provides a common extension Future: ListenableFuture, SettableFuture and helper classes Futures etc., to facilitate asynchronous programming. Future interface while difficult to directly express dependencies between the plurality of Future results. The actual development, we often need to achieve the following objectives:
- The two asynchronous computation into one, independently of each other between two asynchronous computation, while the second turn depends on the first result.
- Future collection waiting all tasks are completed.
- Future collection only wait for the fastest end of the task is completed (likely because they are trying different ways to calculate the same value), and returns its result.
- Future respond completion event (that is, when the completion Future events will be notified and can use the results to calculate the Future to the next step, not simply block waiting for the results of the operation).
JDK1.8 only added a new implementation class CompletableFuture, to achieve the Future, CompletionStage two interfaces. To achieve the Future interface means you can get the results as before polling or by blocking the way.
2.1 creates an instance of CompletableFuture
In addition to direct an example of a new CompletableFuture you can also create an instance factory method CompletableFuture by
factory method:
public static CompletableFuture<Void> runAsync(Runnable runnable) {
if (runnable == null) throw new NullPointerException();
CompletableFuture<Void> f = new CompletableFuture<Void>();
execAsync(ForkJoinPool.commonPool(), new AsyncRun(runnable, f));
return f;
}
public static CompletableFuture<Void> runAsync(Runnable runnable,、 Executor executor) {
if (executor == null || runnable == null)
throw new NullPointerException();
CompletableFuture<Void> f = new CompletableFuture<Void>();
execAsync(executor, new AsyncRun(runnable, f));
return f;
}
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) {
if (supplier == null) throw new NullPointerException();
CompletableFuture<U> f = new CompletableFuture<U>();
execAsync(ForkJoinPool.commonPool(), new AsyncSupply<U>(supplier, f));
return f;
}
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor) {
if (executor == null || supplier == null)
throw new NullPointerException();
CompletableFuture<U> f = new CompletableFuture<U>();
execAsync(executor, new AsyncSupply<U>(supplier, f));
return f;
}
Asynsc represent asynchronous, and different supplyAsync and runAsync return a result asynchronously with the former, the latter is the void, the second function of the second parameter is the thread pool to create our own, otherwise use the default ForkJoinPool.commonPool () as it's the thread pool.
2.2 Methods of obtaining results
public T get()
public T get(long timeout, TimeUnit unit)
public T getNow(T valueIfAbsent)
public T join()
getNow bit special, if the result of the calculation has been completed the result is returned or an exception is thrown, otherwise it returns the given valueIfAbsent value.
join returns the result of the calculation or throw an unchecked exceptions (CompletionException), and get it for exception handling thrown some subtle differences. See cn.enjoyedu.cha.cfdemo under CFDemo and JoinAndGet.
2.3 helpers
public static CompletableFuture<Void> allOf(CompletableFuture<?>... cfs)
public static CompletableFuture<Object> anyOf(CompletableFuture<?>... cfs)
allOf method is performed when all CompletableFuture are performed after the calculation.
anyOf method is performed when any CompletableFuture executes after calculation, the same calculation result.
See the code:
public class AllofAnyOf {
public static void main(String[] args) throws Exception {
Random rand = new Random();
CompletableFuture<Integer> future1 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000 + rand.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("future1完成");
return 100;
});
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(2000 + rand.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("future2完成");
return "abc";
});
CompletableFuture<String> future3 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(3000 + rand.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("future3完成");
return "123abc";
});
// allOf 方法是当所有的CompletableFuture都执行完后执行计算。
CompletableFuture.allOf(future1,future2,future3).thenRun(()->{
System.out.println("All done!");
});
//anyOf 方法是当任意一个CompletableFuture执行完后就会执行计算,计算的结果相同。
CompletableFuture<Object> f = CompletableFuture.anyOf(future1,future2,future3);
System.out.println("anyOf==="+f.get());
SleepTools.second(5);
}
}
CompletionStage is an interface, from the point of view that is named a stage of completion, it represents a particular computing stage can be synchronous or asynchronous is completed. You can think of it as a single unit on the assembly line computing, and eventually produce a final result, which means that several CompletionStage can be connected in series, a stage of completion can trigger the execution of the next stage, then trigger the next time, again then the next time ......... trigger.
2.4 summary CompletableFuture several key points:
1) calculated can be represented by Future, Consumer or Runnable interface apply, accept or run like.
2) calculation is performed are the following:
. A default execution.
b. Using the asynchronous execution of the default provider CompletionStage asynchronous execution, these methods were used someActionAsync this format.
c. Using asynchronous execution Executor provider. The method is also someActionAsync this format, but will add a parameter Executor.
2.5 CompletableFuture There are about fifty ways, but can be classified as:
Transform class thenApply:
public <U> CompletableFuture<U> thenApply
(Function<? super T,? extends U> fn) {
return doThenApply(fn, null);
}
public <U> CompletableFuture<U> thenApplyAsync
(Function<? super T,? extends U> fn) {
return doThenApply(fn, ForkJoinPool.commonPool());
}
public <U> CompletableFuture<U> thenApplyAsync
(Function<? super T,? extends U> fn,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doThenApply(fn, executor);
}
The key parameter is a function of the interface Function. Its parameters are the result of a calculation stage, the return value is the result after the conversion.
- Consumer thenAccept:
public CompletableFuture<Void> thenAccept
(Consumer<? super T> action) {
return doThenAccept(action, null);
}
public CompletableFuture<Void> thenAcceptAsync
(Consumer<? super T> action) {
return doThenAccept(action, ForkJoinPool.commonPool());
}
public CompletableFuture<Void> thenAcceptAsync
(Consumer<? super T> action,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doThenAccept(action, executor);
}
The key parameter is a function of the Consumer interface, it is the result of the reference phase on a calculation, no return value.
- Performing the operations based thenRun:
public CompletableFuture<Void> thenRun
(Runnable action) {
return doThenRun(action, null);
}
public CompletableFuture<Void> thenRunAsync
(Runnable action) {
return doThenRun(action, ForkJoinPool.commonPool());
}
public CompletableFuture<Void> thenRunAsync
(Runnable action,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doThenRun(action, executor);
}
The results of the previous step is not concerned, the next action, the reference is an example of a Runnable, showing operation performed after step.
- Conversion binding categories:
public <U,V> CompletableFuture<V> thenCombine
(CompletionStage<? extends U> other,
BiFunction<? super T,? super U,? extends V> fn) {
return doThenCombine(other.toCompletableFuture(), fn, null);
}
public <U,V> CompletableFuture<V> thenCombineAsync
(CompletionStage<? extends U> other,
BiFunction<? super T,? super U,? extends V> fn) {
return doThenCombine(other.toCompletableFuture(), fn,
ForkJoinPool.commonPool());
}
public <U,V> CompletableFuture<V> thenCombineAsync
(CompletionStage<? extends U> other,
BiFunction<? super T,? super U,? extends V> fn,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doThenCombine(other.toCompletableFuture(), fn, executor);
}
Further processing needs return values, and other return values represented CompletionStage Thereafter, the two return value, the return value of the specified type conversion. Two CompletionStage are executed in parallel, between them and has no dependency order, other and not wait for the previous CompletableFuture finished before execution.
- Conversion binding categories:
public <U> CompletableFuture<U> thenCompose
(Function<? super T, ? extends CompletionStage<U>> fn) {
return doThenCompose(fn, null);
}
public <U> CompletableFuture<U> thenComposeAsync
(Function<? super T, ? extends CompletionStage<U>> fn) {
return doThenCompose(fn, ForkJoinPool.commonPool());
}
public <U> CompletableFuture<U> thenComposeAsync
(Function<? super T, ? extends CompletionStage<U>> fn,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doThenCompose(fn, executor);
}
For Compose can connect two CompletableFuture, its internal processing logic when the first process is not completed CompletableFuture merged into a CompletableFuture, if the process is completed, the second one immediately CompletableFuture future will be processed. CompletableFuture a first processing result is the second input parameter future needs.
- Combined with consumer categories:
public <U> CompletableFuture<Void> thenAcceptBoth
(CompletionStage<? extends U> other,
BiConsumer<? super T, ? super U> action) {
return doThenAcceptBoth(other.toCompletableFuture(), action, null);
}
public <U> CompletableFuture<Void> thenAcceptBothAsync
(CompletionStage<? extends U> other,
BiConsumer<? super T, ? super U> action) {
return doThenAcceptBoth(other.toCompletableFuture(), action,
ForkJoinPool.commonPool());
}
public <U> CompletableFuture<Void> thenAcceptBothAsync
(CompletionStage<? extends U> other,
BiConsumer<? super T, ? super U> action,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doThenAcceptBoth(other.toCompletableFuture(), action, executor);
}
We need further processing the return value, and other representatives of CompletionStage return to duty after using both return value to consume.
- Run after execution classes:
public CompletableFuture<Void> runAfterBoth
(CompletionStage<?> other,
Runnable action) {
return doRunAfterBoth(other.toCompletableFuture(), action, null);
}
public CompletableFuture<Void> runAfterBothAsync
(CompletionStage<?> other,
Runnable action) {
return doRunAfterBoth(other.toCompletableFuture(), action,
ForkJoinPool.commonPool());
}
public CompletableFuture<Void> runAfterBothAsync
(CompletionStage<?> other,
Runnable action,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doRunAfterBoth(other.toCompletableFuture(), action, executor);
}
I do not care about these two CompletionStage result, only care about two CompletionStage are finished, then before proceeding Runnable.
- Take the fastest conversion categories:
public <U> CompletableFuture<U> applyToEither
(CompletionStage<? extends T> other,
Function<? super T, U> fn) {
return doApplyToEither(other.toCompletableFuture(), fn, null);
}
public <U> CompletableFuture<U> applyToEitherAsync
(CompletionStage<? extends T> other,
Function<? super T, U> fn) {
return doApplyToEither(other.toCompletableFuture(), fn,
ForkJoinPool.commonPool());
}
public <U> CompletableFuture<U> applyToEitherAsync
(CompletionStage<? extends T> other,
Function<? super T, U> fn,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doApplyToEither(other.toCompletableFuture(), fn, executor);
}
Nearly two CompletionStage who I calculated the next step conversion actions with the result that CompletionStage. Real development scenario, there are two channels always encounter the same thing complete, so we can call this method to find a fastest results are processed.
- Take the fastest consumer:
public CompletableFuture<Void> acceptEither
(CompletionStage<? extends T> other,
Consumer<? super T> action) {
return doAcceptEither(other.toCompletableFuture(), action, null);
}
public CompletableFuture<Void> acceptEitherAsync
(CompletionStage<? extends T> other,
Consumer<? super T> action) {
return doAcceptEither(other.toCompletableFuture(), action,
ForkJoinPool.commonPool());
}
public CompletableFuture<Void> acceptEitherAsync
(CompletionStage<? extends T> other,
Consumer<? super T> action,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doAcceptEither(other.toCompletableFuture(), action, executor);
}
Two CompletionStage, who quickly calculated that I would be spending the next step with the result that the operation of CompletionStage.
- Take the fastest run after the class:
public CompletableFuture<Void> runAfterEither(CompletionStage<?> other,
Runnable action) {
return doRunAfterEither(other.toCompletableFuture(), action, null);
}
public CompletableFuture<Void> runAfterEitherAsync
(CompletionStage<?> other,
Runnable action) {
return doRunAfterEither(other.toCompletableFuture(), action,
ForkJoinPool.commonPool());
}
public CompletableFuture<Void> runAfterEitherAsync
(CompletionStage<?> other,
Runnable action,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doRunAfterEither(other.toCompletableFuture(), action, executor);
}
Two CompletionStage, any next step will be to complete the operation (Runnable).
- Abnormal compensation categories:
public CompletableFuture<T> exceptionally
(Function<Throwable, ? extends T> fn) {
if (fn == null) throw new NullPointerException();
CompletableFuture<T> dst = new CompletableFuture<T>();
ExceptionCompletion<T> d = null;
Object r;
if ((r = result) == null) {
CompletionNode p =
new CompletionNode(d = new ExceptionCompletion<T>
(this, fn, dst));
while ((r = result) == null) {
if (UNSAFE.compareAndSwapObject(this, COMPLETIONS,
p.next = completions, p))
break;
}
}
if (r != null && (d == null || d.compareAndSet(0, 1))) {
T t = null; Throwable ex, dx = null;
if (r instanceof AltResult) {
if ((ex = ((AltResult)r).ex) != null) {
try {
t = fn.apply(ex);
} catch (Throwable rex) {
dx = rex;
}
}
}
else {
@SuppressWarnings("unchecked") T tr = (T) r;
t = tr;
}
dst.internalComplete(t, dx);
}
helpPostComplete();
return dst;
}
Exception occurred when running, it can be compensated by exceptionally.
- After running record results categories:
public CompletableFuture<T> whenComplete
(BiConsumer<? super T, ? super Throwable> action) {
return doWhenComplete(action, null);
}
public CompletableFuture<T> whenCompleteAsync
(BiConsumer<? super T, ? super Throwable> action) {
return doWhenComplete(action, ForkJoinPool.commonPool());
}
public CompletableFuture<T> whenCompleteAsync
(BiConsumer<? super T, ? super Throwable> action,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doWhenComplete(action, executor);
}
After the action is finished the results of its calculation results back to the original return CompletableFuture or abnormal. So it will not have any effect on the outcome.
- Run post-treatment results categories:
public <U> CompletableFuture<U> handle
(BiFunction<? super T, Throwable, ? extends U> fn) {
return doHandle(fn, null);
}
public <U> CompletableFuture<U> handleAsync
(BiFunction<? super T, Throwable, ? extends U> fn) {
return doHandle(fn, ForkJoinPool.commonPool());
}
public <U> CompletableFuture<U> handleAsync
(BiFunction<? super T, Throwable, ? extends U> fn,
Executor executor) {
if (executor == null) throw new NullPointerException();
return doHandle(fn, executor);
}
When the run is completed, the processing of the results. There are two cases when this is completed, a method is normally performed, the return value. Another is a program encounters an exception thrown causing disruption.
Three, Lambda crash
This chapter only supplements the students did not contact Lambda Quick Start and Quick, more specifically Lamba knowledge please refer to their own books and blog. Now we have an entity class, we will have this entity class operation.
1, the first step in business
We want to pick out a circle of radius 2 selected from a group of the Circle, so we wrote a method
// 1、挑选出半径为2的圆
public static List<Circle> getCircles(List<Circle> circles){
List<Circle> circleList = new ArrayList<>();
for(Circle circle :circles){
if(circle.getRadius()==2){
circleList.add(circle);
}
}
return circleList;
}
In this way, no doubt very elegant, if we want to pick a circle of radius 3, is it still possible to write a method? So we will consider parameterized selection criteria, such as a circle or a circle the radius selected by color selection.
// 2.1、选择条件参数化,根据颜色挑选出圆
public static List<Circle> getCircleByColor(List<Circle> circles, String color){
List<Circle> circleList = new ArrayList<>();
for(Circle circle :circles){
if(color.equals(circle.getColor())){
circleList.add(circle);
}
}
return circleList;
}
// 2.2、选择条件参数化,根据半径挑选出圆
public static List<Circle> getCircleByRadius(List<Circle> circles, int radius){
List<Circle> circleList = new ArrayList<>();
for(Circle circle :circles){
if(radius==circle.getRadius()){
circleList.add(circle);
}
}
return circleList;
}
However, to achieve this, there are still problems, 1, change the selection criteria, then the corresponding method should be changed, for example, we want to pick the circle radius greater than 3, how to do? If I have to choose based on multiple criteria, how do? Is all the conditions have passed it? Thus, we consider the definition of an interface selection round, the program evolved to second ho.
2, the second step to improve business
Behavioral parameterized, define an interface ChoiceCircle:
static interface ChoiceCircle{
boolean getCircle(Circle circle);
}
Conducting round selection of the method, we put this interface as a parameter passed
/**
* 行为参数化,根据条件挑选出圆
*/
public static List<Circle> getCircleByChoice(List<Circle> circles, ChoiceCircle choice){
List<Circle> circleList = new ArrayList<>();
for(Circle circle : circles) {
if(choice.getCircle(circle)) {
circleList.add(circle);
}
}
return circleList;
}
Then, according to business needs as long as we implement the interface, and implementation class can be passed instances
/**
* 挑选圆的行为实现之一,选出红色的圆
*/
static class CircleByRed implements ChoiceCircle{
@Override
public boolean getCircle(Circle circle) {
return "Red".equals(circle.getColor());
}
}
/**
* 挑选圆的行为实现之二,选出半径为2的圆
*/
static class CircleByRadiusTwo implements ChoiceCircle{
@Override
public boolean getCircle(Circle circle) {
return circle.getRadius() == 2;
}
}
public static void service(){
List<Circle> src = new ArrayList<>(); // 待处理的圆的集合
List<Circle> result = getCircleByChoice(src, new CircleByRed());
List<Circle> result2 = getCircleByChoice(src, new CircleByRadiusTwo());
}
This approach can improve flexibility, but business picked each additional behavior, we need to explicitly declare an interface ChoiceCircle implementation class, so we can consider the use of anonymous inner classes, to the third step.
3, the third step business optimization
In actual use, we no longer declare an interface ChoiceCircle implementation class:
public static void service() {
List<Circle> src = new ArrayList<>(); // 待处理的圆的集合
// 选出半径为2的圆
List<Circle> radiusTwos = getCircleByChoice(src, new ChoiceCircle() {
@Override
public boolean getCircle(Circle circle) {
return circle.getRadius() == 2;
}
});
// 选出红色的圆
List<Circle> red = getCircleByChoice(src, new ChoiceCircle() {
@Override
public boolean getCircle(Circle circle) {
return "Red".equals(circle.getColor());
}
});
}
Anonymous inner classes take up more code space, and there are templates of code, in this case, Lambda expressions can come in handy
public static void serviceByLambda() {
List<Circle> src = new ArrayList<>(); // 待处理的圆的集合
// 选出半径为2的圆
List<Circle> radiusTwos = getCircleByChoice(src,
(Circle circle) -> circle.getRadius() ==2);
// 选出红色的圆
List<Circle> redCircle = getCircleByChoice(src,
circle -> "Red".equals(circle.getColor()));
}
So Lambda expressions can be written as a simple anonymous inner classes, grammatically Lambda expressions consists of three parts, parameter lists, arrows, body , such as:
(parameters) -> expression或 (parameters) -> {statements;}
Lambda expressions used in the function interface, so-called functional interface that defines an interface is only abstract methods (Interface), if there is a default interface method does not affect.
Notes @FunctionalInterface can help us to prevent errors in the design of functional interface.
We used Runnable, Callable is functional interfaces, JDK8 in several new functional interfaces:
-
Predicate: contains test methods, acceptance of generic T, returns boolean, can be regarded as assertion (check) Interface
-
Consumer: contains accept method to accept generic T, no return, it can be regarded as data consumption Interface
-
Function <T, R>: apply method comprising, receiving generic T, return R, it can be regarded as mapping conversion interface
-
Supplier get method contains no input and returns T, it can be seen as creating a new object interface
-
UnaryOperator extended to Function <T, T>, so this is essentially a conversion interface mapping, mapping type but remains unchanged after conversion
-
BiFunction <T, U, R> apply method comprising, receiving generic T, U, return R, can be considered as complex mapping conversion interface
-
BinaryOperator extended to Function
BiFunction <T, T, T>, so this is essentially a complex map conversion interface, but the conversion map type remains unchanged -
BiPredicate <T, U> test method comprising, receiving generic T, U, return boolean, can be considered as complex assertion (check) interface
-
BiConsumer <T, U>:
comprising accept method, accepts generic T, U, no return, consumption data can be regarded as complex interfaces also provide some mechanism to prevent automatic packing, and the original type expressly stated specializations interface function, for example, in the sense, the interface and the corresponding Predicate no difference.

4, the function descriptor
signature abstract interface method is basically a function of Lambda expression signature. We call this function is called abstract method descriptor. Runnable interface can be seen as a return to what neither accept nor (void) the signature of the function, because it has only one abstract method called run, this method does nothing to accept, nothing is returned (void).
We can use () -> void represents the parameter list is empty and void of return function. This is the Runnable interface represents. So we can say () -> void is a function descriptor Runnable interface.

Reexamination Callable Supplier interfaces and interfaces

from a function descriptor view, and Supplier interfaces Callable interfaces are the same, are() -> X
Therefore, the same can be used simultaneously in Lambda these two interface functions, such as:
Callable<Integer> = () -> 33;
Supplier<><Integer> = () -> 33;
四、扩充知识点- Disruptor
1、应用背景和介绍
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内部的内存队列的延迟问题,而不是分布式队列。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。
据目前资料显示:应用Disruptor的知名项目有如下的一些:Storm, Camel,
Log4j2,还有目前的美团点评技术团队也有很多不少的应用,或者说有一些借鉴了它的设计机制。
Disruptor是一个高性能的线程间异步通信的框架,即在同一个JVM进程中的多线程间消息传递。
2、传统队列问题
在JDK中,Java内部的队列BlockQueue的各种实现,仔细分析可以得知,队列的底层数据结构一般分成三种:数组、链表和堆,堆这里是为了实现带有优先级特性的队列暂且不考虑。
在稳定性和性能要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列;同时,为了减少Java的垃圾回收对系统性能的影响,会尽量选择 Array格式的数据结构。这样筛选下来,符合条件的队列就只有ArrayBlockingQueue。但是ArrayBlockingQueue是通过加锁的方式保证线程安全,而且ArrayBlockingQueue还存在伪共享问题,这两个问题严重影响了性能。
ArrayBlockingQueue的这个伪共享问题存在于哪里呢,分析下核心的部分源码,其中最核心的三个成员变量为:
/** items index for next take, poll, peek or remove */
int takeIndex;
/** items index for next put, offer, or add */
int putIndex;
/** Number of elements in the queue */
int count;
是在ArrayBlockingQueue的核心enqueue和dequeue方法中经常会用到的,这三个变量很容易放到同一个缓存行中,进而产生伪共享问题。
3、高性能的原理
- 引入环形的数组结构:数组元素不会被回收,避免频繁的GC。
- 无锁的设计:采用CAS无锁方式,保证线程的安全性
- 属性填充:通过添加额外的无用信息,避免伪共享问题
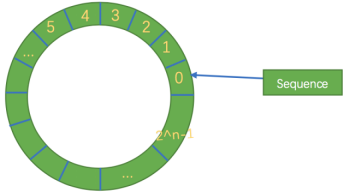
环形数组结构是整个Disruptor的核心所在。
- First, because it is an array, so fast than the list, and according to our interpretation of the above cache line know, a load element in the array, the array elements adjacent also be pre-loaded, so that in such a structure, cpu do not need main memory from time to time to load the next element in the array. And, you can pre-allocate memory for an array such that array object persist (unless the program is terminated). This means do not need to spend a lot of time for garbage collection. Further, unlike the above list, it is necessary to add to each object thereon node object creation - corresponding to the deleted node when the need to perform the corresponding memory cleaning operation. The annular array elements using cover, avoiding the jvm GC.
- Secondly, as a ring structure, the array size is 2 ^ n, so that the positioning element can be higher operational efficiency by bit, with consistent hashing in this strategy a bit like a ring. In disruptor in this magnificent ring structure is RingBuffer, since it is an array, then there is size, and this size must be 2 ^ n.
- Its essence is just an ordinary array, when data is placed just filling up the queue (i.e. reaches 2 ^ n-1 position), the refill data will start from 0, overwriting the previous data, then the equivalent of a ring.
- Each producer is first obtained by CAS competitive space can be written, and then to slowly put inside the data, if consumers have to happen this time consumption data, each consumer will need to get the maximum consumption index.
- Meanwhile Disruptor
Unlike traditional queue, into a queue head pointer and a tail pointer team, but only one corner (superscript FIG SEQ), which belongs to a volatile variable, but also we are able to operate the lock can be achieved without Disruptor one of the reasons, but also through the cache line to add, to avoid false sharing problem. This pointer is the self-energizing has been acquired by way of a writable or readable data.