JoinNode distributed in node01, node02, node03
1. Stop before clusters
2. Free secret: node01, node02
node02: cd ~/.ssh ssh-keygen -t dsa -P '' -f ./id_dsa cat id_dsa.pub >> authorized_keys scp ./id_dsa.pub node01:`pwd`/node02.pub node01: cd ~/.ssh cat node02.pub >> authorized_keys
3.zookeeper Cluster Setup java language development (need jdk)
node02: tar xf Zook .... tar.gz mv zoo... /opt/bigdata cd /opt/bigdata/zoo.... cd conf cp zoo_sample.cfg zoo.cfg we zoo.cfg dataDir=/var/bigdata/hadoop/zk server.1=node02:2888:3888 server.2=node03:2888:3888 server.3=node04:2888:3888 mkdir /var/bigdata/hadoop/zk echo 1 > /var/bigdata/hadoop/zk/myid we / etc / profile export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.4.6 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin . /etc/profile cd /opt/bigdata scp -r ./zookeeper-3.4.6 node03:`pwd` scp -r ./zookeeper-3.4.6 node04:`pwd` node03: mkdir /var/bigdata/hadoop/zk echo 2 > / var / with BigData / Hadoop / ZK / MyID * Environment Variables . /etc/profile node04: mkdir /var/bigdata/hadoop/zk echo . 3 > / var / with BigData / Hadoop / ZK / MyID * Environment Variables . /etc/profile node02~node04: zkServer.sh start
And the core 4 disposed hadoop hdfs
core-site.xml <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>node02:2181,node03:2181,node04:2181</value> </property> hdfs-site.xml # Here is renamed <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/ha/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/var/bigdata/hadoop/ha/dfs/data</value> </property> # The following are many, logical to physical mapping node <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node01:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node02:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node01:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node02:50070</value> </property> # The following is the JN start where the data is stored disk <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/var/bigdata/hadoop/ha/dfs/jn</value> </property> Acting classes and implementation #HA role switching, we use the ssh-free secret <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_dsa</value> </property> # Enable automation: Start zkfc <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
5. distribute two profiles
6. Turn journalnode 1,2,3 station
hadoop-daemon.sh start journalnode
7. Select a NN do formatting
hdfs namenode -format
8. Start the NN in namenode
hadoop-daemon.sh start namenode
9. In another synchronization NN
hdfs namenode -bootstrapStandby
10. zk formatted at node01
hdfs zkfc -formatZK
11. Start
start-dfs.sh
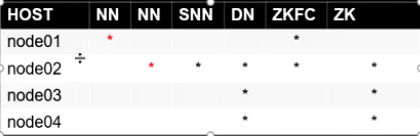
12. Verify
kill -9 xxx a) kill active NN b) kill zkfc active NN around NIC c) shutdown activeNN host: ifconfig eth0 down 2 node has been blocked downgrade If the network card on a recovery ifconfig eth0 up The final 2 becomes active