
Recently wrote notes [Sklearn source study notes] (including net sample official interpretation) unsupervised Gaussian learning mixed model procedure, the official Sklearn source useful BIC to estimate the score in the variance matrix and the components of different co-Gaussian mixture model, BIC and AIC ordered to summarize the knowledge records.
More about my study notes, welcome your interest in " Wuhan AI algorithm study " Public number, author micro letter comrliuyu.
This article is divided into three parts " [BIC] ", " [AIC] ", " [Sklearn in bic] formula " to expand the total reading time of about 8 minutes.
Likelihood function we are not familiar with the statistical likelihood function is the kind that contains statistical model parameter function, parameter θ about the likelihood function L (θ | x) ( in value ) is equal to the given parameter θ variable X probability: L (θ | x) = P (X = x | θ), the likelihood function plays an important role in the parameter estimation. The actual process is assumed to obey a variable in a distribution, this distribution with unknown parameters necessary to determine the parameters of the final model, we can get by maximum likelihood estimation, this completes the training probability model (in fact, the training process probability model that is, parameter estimation).
Then in fact we will still get a more reasonable model for a number of training data, such as Gaussian mixture model in different covariance matrix and a different number of components may produce different results, how to choose the best model in these models too ?
Model selection is the need to find a balance capability data set descriptor (i.e., likelihood function) between the model and the complexity of the model, the model selection method is commonly used AIC and BIC, the model selection AIC and BIC values are smaller the better. AIC and BIC in the description, when the training data is sufficiently large, the accuracy of the model can continue to improve, that is, the likelihood function, the stronger the description ability of the dataset, and complexity often reflected in the number of parameters, i.e., parameters as possible, by the following formula can be understood principles of AIC and BIC formula, the actual application of more use in the BIC.

【BIC:Bayesian Information Criterion 】
BIC (Bayesian Information Criterion) is used to select the best model in practice, the formula k is the number of parameters of the model, n- sample number, L is the likelihood function . k LN ( the n- ) penalty term in the dimension is too large and relatively small training sample data, the curse of dimensionality can effectively avoid the phenomenon. BIC for punishment in terms of the number of model parameters due to the additional ln (n) consider the sample size, larger than the AIC, when the excessive number of samples, the accuracy of the model can be avoided caused by excessive model complexity is too high .
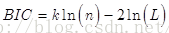
【AIC:Akaike Information Criterion】
The AIC (Akaike Information Criterion) based on the information entropy, a measure of the statistical model fit is an indicator of good, the calculation formula below, where K is the number of model parameters, L is the likelihood function, Theory the AIC , the better the smaller the value of the model . We choose the actual model, when the likelihood function two models were not significant, wherein the number of the first model parameters play a decisive role, that is, the smaller the optimal model complexity model .
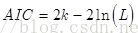
[Official bic in Sklearn]
X is the code input samples, wherein self.score (x) is calculated to obtain the average value of maximum likelihood function, X.shaper [0] table the number of samples.
def bic(self, X):
return (-2 * self.score(X) * X.shape[0] +
self._n_parameters() * np.log(X.shape[0]))