Machine learning is popular AI technology in a very important direction, either supervised or unsupervised learning are learning to use a variety of "metrics" to get different degrees of similarity difference sample data or different sample data. Good "metrics" can significantly improve the classification or prediction algorithm accuracy, will be described herein in a variety of machine learning "measure", "metric" is mainly composed of two, is a distance, similarity and correlation coefficients from the studies generally linear body points in space; the similarity research body linear vector space; correlation coefficient distributed data mainly research subject. This paper describes the similarity.
1 Jaccard similarity - the magical effect of set theory
Jaccard similarity, or called and cross-ratios. It is the statistic similarity and diversity for comparative sample set. Jacquard coefficient can be a measure of similarity limited sample set, which is defined as the intersection of the two sets of size and the ratio between the size of the set:
Let A and B are two sets, the Jaccard similarity A and B is:
\[ sim_{Jaccard}(A,B) = sim_{Jaccard}(B,A)=\frac{{\left| {A \cap B} \right|}}{{\left| {A \cup B} \right|}} = \frac{{\left| {A \cap B} \right|}}{{\left| A \right| + \left| B \right| - \left| {A \cap B} \right|}} \]
若集合A和B完全一样则定义J(A,B)=1,显示0<=J(A,B)<=1
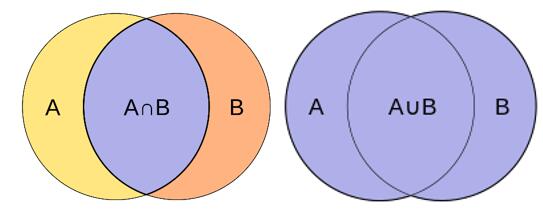
FIG 1 A and set B set intersection and union
The following simple example to illustrate how Jaccard similarity calculation, setting
set A = { "A", " B", "C", "D"}
set B = { "A", " B", "E", F. "," G "}
a and B and set = {A∪B" a "," B "," C "," D "," E "," F. "," G "}
a and B intersection A∩B = { "a", " B"}
so | A∪B | = 7, | A∩B | = 2
so Jaccard similarity a and B 2/7
2 cosine similarity --NLP art big kill
Cosine similarity to a measure of similarity between them by measuring the angle between the vector product of two cosine space. Cosine of 0 degrees is 1, and any other cosine of the angle is not greater than 1. With the cosine of the angle between two vectors as a measure of vector space between the two individual differences in the size of the measure, i.e. a measure of the difference in the two direction vectors.
If the vector a = (a1, a2, ... , an) and the vector b = (b1, b2, ... , bn) are two points Euclidean space, the dot product of two vectors is a⋅b = | a | ⋅ | b | ⋅cos⟨a, b⟩ , is directed, the amount of vector, cos⟨a, b⟩ a and b is the cosine of the angle, the two vectors a and b cosine similarity calculated The formula is:
\ [\ the begin {Array} {L} Si {m_Low {Cos}} \ left ({{\ BF {A}}, {\ BF {B}}} \ right) {\ RM {=}} si {m_ {Cos}} \ left ({{\ bf {a}}, {\ bf {b}}} \ right) = \ frac {{{\ bf {a}} \ cdot {\ bf {b} }}} {{{{\ left \ | {\ bf {a}} \ right \ |} _2} {{\ left \ | {\ bf {b}} \ right \ |} _2}}} \\ \ quad \ quad \ quad \ quad \ quad \ quad \ quad \ quad \ quad \; = \ frac {{{a_1} {b_1} + {a_2} {b_2} + \ cdots + {a_n} {b_n}}} { {\ sqrt {a_1 ^ 2 + a_2 ^ 2 + \ cdots + a_n ^ 2} \ sqrt {b_1 ^ 2 + b_2 ^ 2 + \ cdots + b_n ^ 2}}} \\ \ end {array} \]
For example the vector x = (0,1,2) and y = (1,0,2), then they cosine distance
\[\cos \left( {x,y} \right) = \frac{{0 \times 1 + 1 \times 0 + 2 \times 2}}{{\sqrt {{0^2} + {1^2} + {2^2}} \cdot \sqrt {{1^2} + {0^2} + 2} }} = \frac{4}{5}\]
Cosine similarity is typically used in information retrieval. In the field of information retrieval, each term has a different level, a document is calculated depending on the weights of terms appearing in the document represented by a frequency of the right eigenvector value. Cosine similarity can therefore be given the similarity of its two themes of the document. In addition, it is usually used for file text mining in comparison. Further, in the field of data mining, it is used to measure the cohesion within the cluster.