A algorithm: quicksort algorithm
Quick sort is a sorting algorithm developed by the Tony Hoare's. Under average conditions, to sort n items to Ο (n log n) comparison of times. In the worst situation you need to Ο (n2) comparisons, but this situation is not uncommon. In fact, quick sort is usually significantly higher than other Ο (n log n) algorithm is faster because its inner loop (inner loop) can be implemented very efficiently out on most of the architecture.
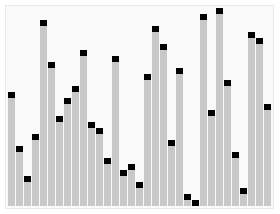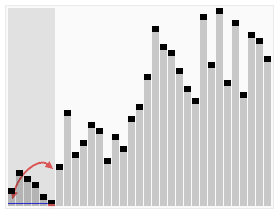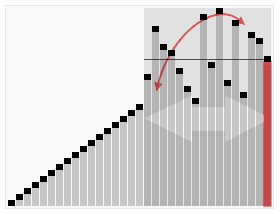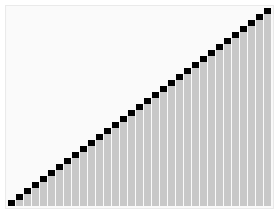
Quick sort using a divide and conquer (Divide and conquer) strategy to put a serial (list) is divided into two sub-serial (sub-lists).
Algorithm steps:
1 pick from a number of column elements, called "reference" (Pivot),
2 reordering columns, all of the elements placed in front of the reference small than the reference value, all the elements of the reference value larger than the reference posing later (number may be either the same side). After the partition exit, on the basis of the number of columns in the middle position. This is called the partition (partition) operation.
3 the number of sub recursively (recursive This) than the reference value the number of columns and the sub-element is greater than the reference value of the element column.
The bottom case of recursion, the size is the number of columns is zero or one, that is, always has been sorted well. While it has been recursion, but this algorithm always quit, because in each iteration (iteration), which will at least one element placed in its final position to go.
Algorithms II: heap sort algorithm
Heap sort (Heapsort) refers to a sorting algorithm such a data structure designed for use heap. Accumulation is a complete binary tree structure of approximation, while meeting the bulk properties: i.e. the key or index sub-node is always less than (or greater than) its parent node.
Heap sort average time complexity is Ο (nlogn).
Algorithm steps:
Create a heap H [0 ... n-1]
to the first stack (maximum) tail and interchangeable stack
3. The stack 1 of downsizing, and call shift_down (0), the aim of the new data to the top of the array adjusted to the corresponding position
4. repeat step 2 until the heap size of 1
Algorithms III: merge sort
Merge sort (Merge sort, Taiwan translation: merge sort) is based on an efficient merge operations sorting algorithm. The algorithm is very typical application uses a divide and conquer (Divide and Conquer) a.
Algorithm steps:
-
Space applications, so that the size of the sum of two sorted sequences, the sequence storage space for merged
-
Setting two pointers, initially sorted into two positions, respectively a starting position of the sequence
-
Comparison of two pointer points to an element, the selected element into a relatively small space to merge, and move the pointer to the next position
-
Repeat step 3 until the pointer reaches one end of the sequence
-
All remaining elements of another sequence directly copied to the end of the sequence were combined

Algorithms Four: binary search algorithm
Binary search algorithm is a search algorithm to find a particular element in an ordered array. Search elements from the middle of the process element in the array, if the intermediate element the element is just looking for, the search process ends element; if a particular element is greater than or less than the intermediate element in the array is greater or less than half of the intermediate element that find and start comparing with the same start in the middle element. If the array is empty at some stage, it represents not found. This search algorithm so that each comparison search reduced by half. The binary search for each search area is reduced by half, the time complexity is Ο (logn).
Algorithms five: BFPRT (linear search algorithm)
BFPRT algorithm to solve the problem is very classic, that is selected k-th largest element (k th small) from a sequence of n elements by clever analysis, BFPRT can guarantee that complexity remains linear time in the worst case. Similar thoughts and ideas of the quick sort algorithm, of course, so the algorithm in the worst case, can still reach o (n) time complexity, the five authors made a sophisticated algorithm processing.
Algorithm steps:
-
The n elements of each group 5, is divided into n / 5 (upper bound) group.
-
The median for each group removed, any sorting method, such as insertion sort.
-
Recursive call selection algorithm to find the median of median of all the previous step, set x, the even lower median number of cases is set to select a smaller middle.
-
Divided by the number of the array to x, x is set equal to less than k, is the number is greater than the x nk.
-
If i == k, to return x; if i <k, of x in the element is smaller than the i-th recursive lookup small elements; if i> k, is greater than the element x ik of a recursive lookup of smaller elements.
Termination condition: n = 1, the return element, i.e. a small i.
Six algorithms: DFS (depth-first search)
Depth-first search algorithm (Depth-First-Search), is a search algorithm. Traversing the tree node depth along its tree branch as deep as possible in the search tree. When all sides are node v has been to explore, the search will find back to the originating node of the edge piece of node v. This process continues until all the nodes have been found so far reachable from the source node. If there is a node undetected, one is selected as the source node and the process is repeated, the whole process is repeated until all nodes have been visited so far. DFS belong blind search.
Depth-first search is a classic graph theory algorithms using depth-first search algorithm can generate the appropriate target topology map sorting table, the use of topological sorting table can easily solve many problems related to graph theory, such as the maximum path problems, etc. Usually heap data structure used to assist in achieving DFS algorithm.
FIG depth-first traversal algorithm steps:
-
Access vertices v;
-
Sequentially from the adjacent node is not accessible v, and depth-first traversal of FIG.; And v have the figures until the communication path vertices have been visited;
-
If the figure at this time there have not been accessed vertex, it has not been accessed from a vertex of view, re-depth-first traversal, until figures all vertices are visited so far.
The above description may be more abstract, for instance:
the DFS after accessing a start vertex v in FIG, starting from v, to access any of its adjacent vertices w1; then from w1, w1 accessing adjacent but has not visited vertex w2; then from w2, a similar visit, ... so go on, until it reaches all vertices u adjacent vertices have been visited.
Then, step back, retreated before the apex visited just once, to see if there are other adjacent vertices have not been accessed. If so, then access this vertex, then after starting from the apex, with previous similar access; if not, then step back and search. Repeat the process until all vertices communicating FIG been visited so far.
Algorithm seven: BFS (BFS)
Breadth-first search algorithm (Breadth-First-Search), is a graphical search algorithm. Simply put, the BFS is starting from the root, traversing node tree (FIG) along the width of the tree (graph). If all nodes are accessed, the algorithm is aborted. BFS also belong to the blind search. Usually queue data structure used to assist in achieving BFS algorithm.
Algorithm steps:
-
First, the root node into the queue.
-
Take the first node from the queue, and checks whether it is the goal.
If the target is found, the end of the search and return the results.
Otherwise it will be all direct child node has not been inspected to join the queue. -
If the queue is empty, showing the entire FIG have checked - FIG i.e. not want the search target. The end of the search and return "not find the target."
-
Repeat Step 2.
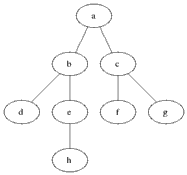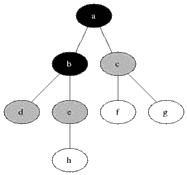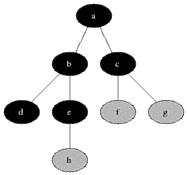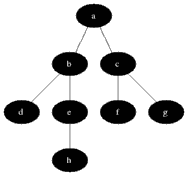
Eight algorithm: Dijkstra algorithm
Dijkstra's algorithm (Dijkstra's algorithm) was proposed by the Dutch computer scientist Edsger W. Dijkstra. Dijkstra's algorithm uses breadth-first search to solve the non-negative weighted directed graph shortest path problem single-source, shortest-path algorithm end up with a tree. The algorithm used in routing algorithms as a sub-module or other graph algorithms.
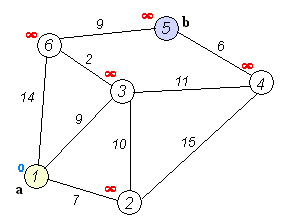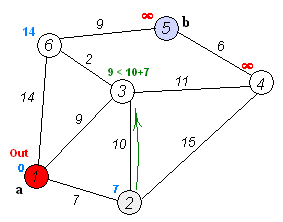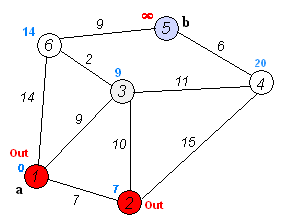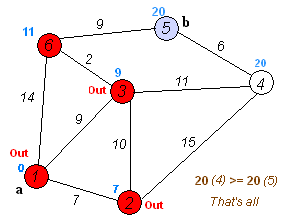
该算法的输入包含了一个有权重的有向图 G,以及G中的一个来源顶点 S。我们以 V 表示 G 中所有顶点的集合。每一个图中的边,都是两个顶点所形成的有序元素对。(u, v) 表示从顶点 u 到 v 有路径相连。我们以 E 表示G中所有边的集合,而边的权重则由权重函数 w: E [0, ∞] 定义。因此,w(u, v) 就是从顶点 u 到顶点 v 的非负权重(weight)。边的权重可以想像成两个顶点之间的距离。任两点间路径的权重,就是该路径上所有边的权重总和。已知有 V 中有顶点 s 及 t,Dijkstra 算法可以找到 s 到 t的最低权重路径(例如,最短路径)。这个算法也可以在一个图中,找到从一个顶点 s 到任何其他顶点的最短路径。对于不含负权的有向图,Dijkstra算法是目前已知的最快的单源最短路径算法。
算法步骤:
-
初始时令 S={V0},T={其余顶点},T中顶点对应的距离值
若存在<v0,vi>,d(V0,Vi)为<v0,vi>弧上的权值
若不存在<v0,vi>,d(V0,Vi)为∞ -
从T中选取一个其距离值为最小的顶点W且不在S中,加入S
-
对其余T中顶点的距离值进行修改:若加进W作中间顶点,从V0到Vi的距离值缩短,则修改此距离值
重复上述步骤2、3,直到S中包含所有顶点,即W=Vi为止
算法九:动态规划算法
动态规划(Dynamic programming)是一种在数学、计算机科学和经济学中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。 动态规划常常适用于有重叠子问题和最优子结构性质的问题,动态规划方法所耗时间往往远少于朴素解法。
动态规划背后的基本思想非常简单。大致上,若要解一个给定问题,我们需要解其不同部分(即子问题),再合并子问题的解以得出原问题的解。 通常许多 子问题非常相似,为此动态规划法试图仅仅解决每个子问题一次,从而减少计算量: 一旦某个给定子问题的解已经算出,则将其记忆化存储,以便下次需要同一个 子问题解之时直接查表。 这种做法在重复子问题的数目关于输入的规模呈指数增长时特别有用。
关于动态规划最经典的问题当属背包问题。
算法步骤:
-
最优子结构性质。如果问题的最优解所包含的子问题的解也是最优的,我们就称该问题具有最优子结构性质(即满足最优化原理)。最优子结构性质为动态规划算法解决问题提供了重要线索。
-
子问题重叠性质。子问题重叠性质是指在用递归算法自顶向下对问题进行求解时,每次产生的子问题并不总是新问题,有些子问题会被重复计算多次。 动态规划算法正是利用了这种子问题的重叠性质,对每一个子问题只计算一次,然后将其计算结果保存在一个表格中,当再次需要计算已经计算过的子问题时,只是 在表格中简单地查看一下结果,从而获得较高的效率。
算法十:朴素贝叶斯分类算法
朴素贝叶斯分类算法是一种基于贝叶斯定理的简单概率分类算法。贝叶斯分类的基础是概率推理,就是在各种条件的存在不确定,仅知其出现概率的情况下, 如何完成推理和决策任务。概率推理是与确定性推理相对应的。而朴素贝叶斯分类器是基于独立假设的,即假设样本每个特征与其他特征都不相关。
朴素贝叶斯分类器依靠精确的自然概率模型,在有监督学习的样本集中能获取得非常好的分类效果。在许多实际应用中,朴素贝叶斯模型参数估计使用最大似然估计方法,换言之朴素贝叶斯模型能工作并没有用到贝叶斯概率或者任何贝叶斯模型。