concept
Feature
In order to describe B-Tree, first define a data record to a tuple [key, Data], the key for the key recording, different data records, the key is different from each other; data is recorded in addition to the data of the key . Then the B-Tree is a data structure that satisfies the following conditions:
d is a positive integer greater than 1, referred to as the degree of B-Tree.
- h is a positive integer, called the height of the B-Tree.
- Each non-leaf node of the n-1 key and n pointers, where d <= n <= 2d.
- Each leaf node contains a key and a minimum of two pointers, one containing up key 2d-1 and 2d pointers, pointers to leaf nodes are null.
- All leaf nodes have the same depth, height h is equal to the tree.
- key and a pointer spaced from one another, both ends of the node pointers.
- A node key non-descending from left to right.
- All the nodes in the tree structure.
- Or each pointer is null, either point to another node.
- If a pointer is in the left most node node is not null, all key points to the node which is less than V ( K E Y . 1 ) v (key1), where V ( K E Y . 1 ) of v (key1) of the node a key value.
- If a pointer is in the rightmost node node is not null, all key points to the node which is greater than V ( K E Y m ) V (KeyM), where V ( K E Y m ) V (KeyM) of the last node a key value.
- If a pointer to adjacent nodes around node are key K E Y I KEYI and K E Y I + . 1 KEYI +. 1 is not null, all key points to the node which is less than V ( K E Y I + . 1 ) V (+ KEYI. 1) and greater than V ( K E Y I ) V (KEYI).
FIG 2 is a schematic diagram d = B-Tree 2.
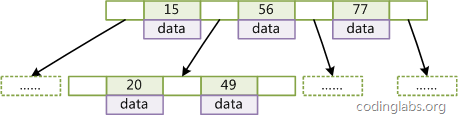
figure 2
Since the characteristics of B-Tree in B-Tree Press algorithm key for retrieving data very intuitive: first binary search from the root node, if the found data corresponding to the node is returned, otherwise the pointer corresponding sections node pointed recursive lookup until you find the node or find a null pointer, the former to find success, the latter lookup fails. Search algorithm pseudocode on B-Tree as follows:
BTree_Search(node, key) { if(node == null) return null; foreach(node.key) { if(node.key[i] == key) return node.data[i]; if(node.key[i] > key) return BTree_Search(point[i]->node); } return BTree_Search(point[i+1]->node); } data = BTree_Search(root, my_key);
关于B-Tree有一系列有趣的性质,例如一个度为d的B-Tree,设其索引N个key,则其树高h的上限为logd((N+1)/2)logd((N+1)/2),检索一个key,其查找节点个数的渐进复杂度为O(logdN)O(logdN)。从这点可以看出,B-Tree是一个非常有效率的索引数据结构。
另外,由于插入删除新的数据记录会破坏B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质,本文不打算完整讨论B-Tree这些内容,因为已经有许多资料详细说明了B-Tree的数学性质及插入删除算法,有兴趣的朋友可以在本文末的参考文献一栏找到相应的资料进行阅读。