For real-time data synchronization, the core of which is based on the log need to achieve, can achieve near real-time data synchronization, log-based implementation does not require a database itself result in any additional constraints in design and implementation.
Copy the main primary synchronization scheme is based on the native MySQL
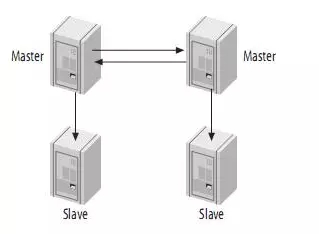
This is a common scenario, in general, small and medium scale when using this architecture is the most convenient.
Two nodes may be employed simple two main mode, and a dedicated line, after master_A node fails, the application is connected to master_B fast switching node, and vice versa. There are several caveats, the case of split brain, two nodes writing the same data lead to conflict, while the auto_increment_increment two nodes (step increment) and auto_increment_offset (self-energizing start value) set to different values . Its purpose is to avoid unplanned downtime, may be some binlog failed to replicate the master in time to be applied on the slave node, which will lead to a new slave write conflicts from value-added data and the original master, so start making its stagger; of course, if the right mechanism to solve the fault-tolerant master-slave increment ID conflict, he can not do this, use the updated version 5.7+ data, you can use multiple threads replication replication latency can be reduced to a large extent Meanwhile, replication latency are particularly sensitive to another alternative, a semi-sync semi-synchronous replication, basically no delay, but the transaction concurrency will be no small degree of damage, especially in two-way time of writing, a comprehensive evaluate and then decide.
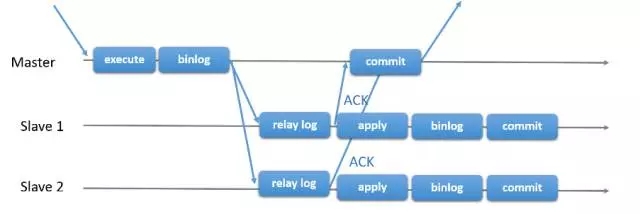
Based Galera replication scheme
Galera is a multi-master data Codership provide synchronous replication mechanism to achieve data synchronization between multiple nodes as well as read and write copy, and can guarantee high availability database services and data consistency, there MariaDB Galera Cluster is based on high availability solutions Galera and Percona XtraDB Cluster (referred to as the PXC).
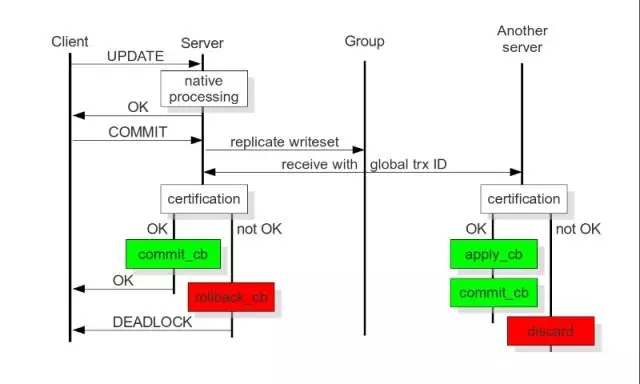
PXC currently used would be more certain, strict data consistency, especially for the electric business class applications, but also has its limitations PXC, if the transaction amount of concurrent large, I suggest using an InfiniBand network, reducing network latency, because there is PXC write to expand and short-board effect, concurrent efficiency have a greater loss, similar to the semi-sync semi-synchronous replication, Gelera actually only use three nodes, the performance and stability of the habitual problems caused by the network jitter
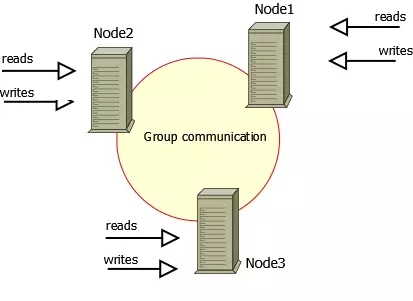
Group Replication-based program
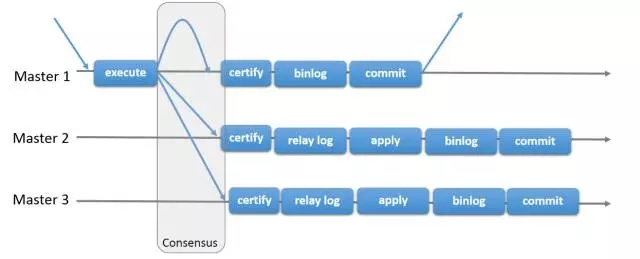
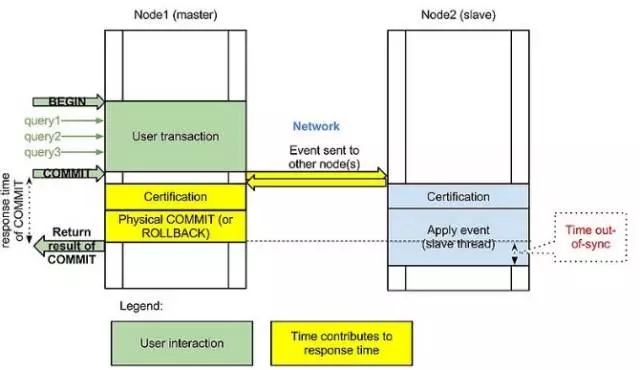
Data provided by the database cluster nodes to ensure consistent strong Paxos protocol, MGR accurate is the official launch of the MySQL high availability solutions, based on the native replication technology, and a plug-in offers, and between all nodes in the cluster can be written to solve a single write performance cluster, and all nodes can read and write, to solve the problem of split brain caused by network partitions to improve the reliability of replicated data, but the reality was a bit cruel, currently not many early adopters, while only supports InnoDB tables, and each tables must have a primary key, do write set for collision detection, to be opened GTID characteristics, must be set to binary format log the ROW, and for selecting the primary write set
COMMIT may lead to failure, similar to the snapshot transaction isolation level of failure scenarios, currently supports nine node cluster up to a MGR, does not support foreign keys to the save point characteristics, do not lock detection section between the global and partial rollback, the binary log does not support binlog event checksum
Based on canal plan
For real-time database synchronization, Alibaba has created a specialized open source project, otter to achieve synchronous replication distributed database, the core idea is still to be quasi-real-time synchronous replication by acquiring incremental data logging database. So otter itself dependent on another open source project that is canal, the project is focused on acquiring incremental database synchronization log information.
The current focus is to implement a database otter between the mysql synchronous replication, namely the use of similar basic technology to achieve bi-directional synchronization database replication between the two mysql database. Note that this means itself may be a two-way A-> B, may be from B-> A, at some node itself is unidirectional.
From the master copy is divided into three steps:
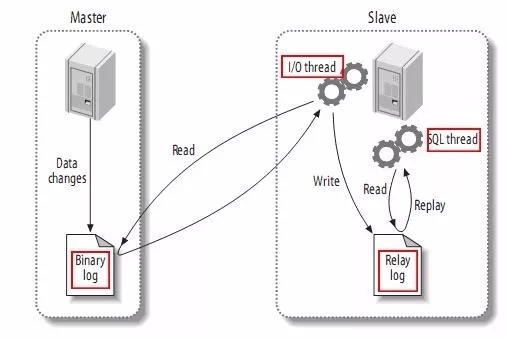
The change to the master record binary log (binary log) in (these records is called binary log events, binary log events, can be viewed by show binlog events);
The master slave copy of the binary log events to its relay log (relay log);
slave relay redo log events, will change to reflect its own data.
canal principle is relatively simple:
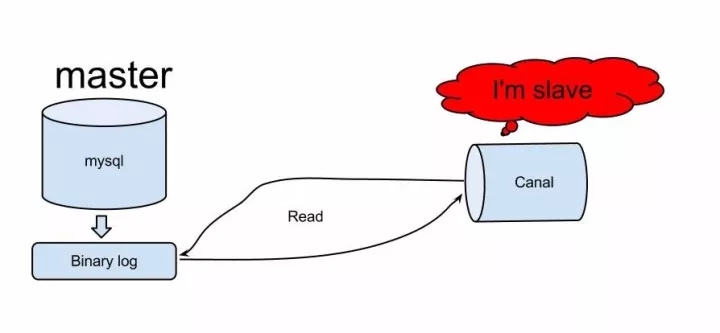
canal interactive simulation mysql slave protocol, disguised himself as mysql slave, to send dump to mysql master agreement
mysql master dump request is received, starting a push to Slave binary log (i.e. Canal)
Canal Analytical binary log object (for the original byte stream)
More reference https://github.com/alibaba/canal
to sum up
The above is a double live MySQL Xiaobian to introduce synchronous replication four solutions, we want to help, if you have any questions please give me a message, Xiao Bian will promptly reply to everyone. In this I am also very grateful for the support of the home-site scripting!