Redis replication (replica)
foreword
What is redis replication?
It is master-slave replication. The master is mainly for writing, and the slave is mainly for reading. When the master data changes, it will automatically synchronize the new data to other slave databases asynchronously.

What can redis replication do?
- read-write separation
- Disaster Recovery
- data backup
- Horizontal expansion supports high concurrency
configuration
With slave library, not with master library
If the master configures the requirepass parameter and requires a password to log in, then the slave must configure masterauth to set the verification password, otherwise the master will reject the slave's access request.
Basic Operation Command
-
View the master-slave relationship and configuration information of the replication node
info replicaiton -
master-slave replication
# 配从库不配主库 replicaof masteIp masterPort -
Change door
slaveof newMasterIp newMasterPort -
self-made king
slaveof no one
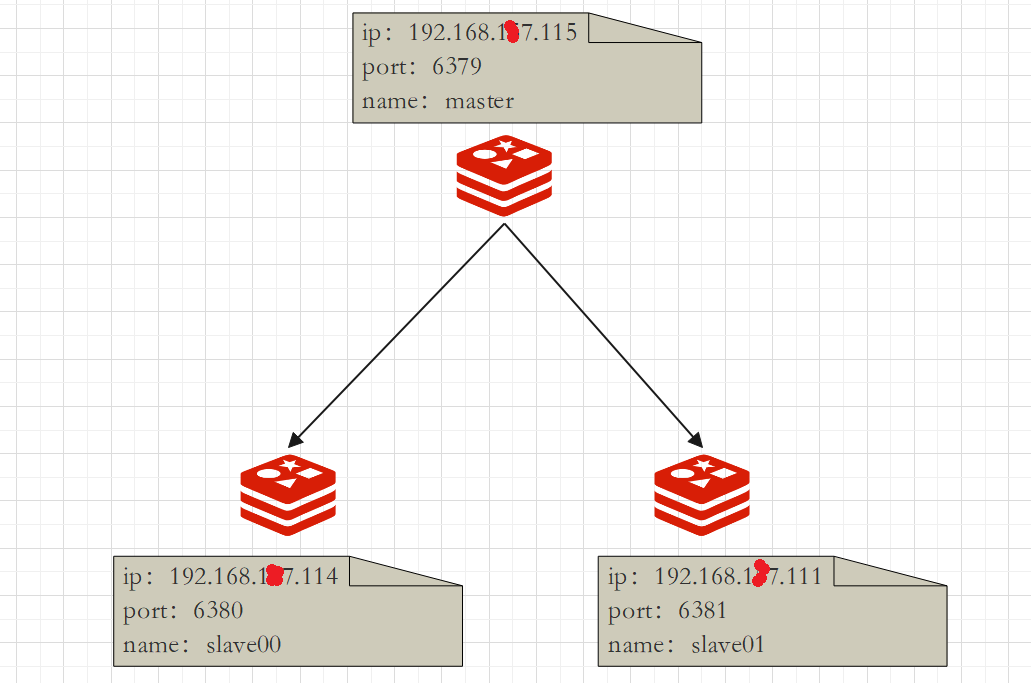
Build redis one master and two slaves
One Master and two Slaves. For the detailed construction process, refer to the Redis cluster construction process
"Redis One Master Two Slave Construction"
**Precautions:** The three hosts need to ensure that they can ping each other.
Case presentation
One master and two slaves
Can the slave execute write commands?
Slave cannot perform write operations

Slave entry point problem
Does the slave replicate from scratch or from the entry point?
Start master, slave00, do not start slave01 first , start slave01 after writing data successfully , the previous data can still be copied .
For the first time, it is done in one pot, followed by the follow-up, the master writes, and the slave follows.
After the host is shut down, will the slaves take over?
The slave machine does not move, it is on standby, and the data of the slave machine can be used normally; wait for the host machine to restart and return
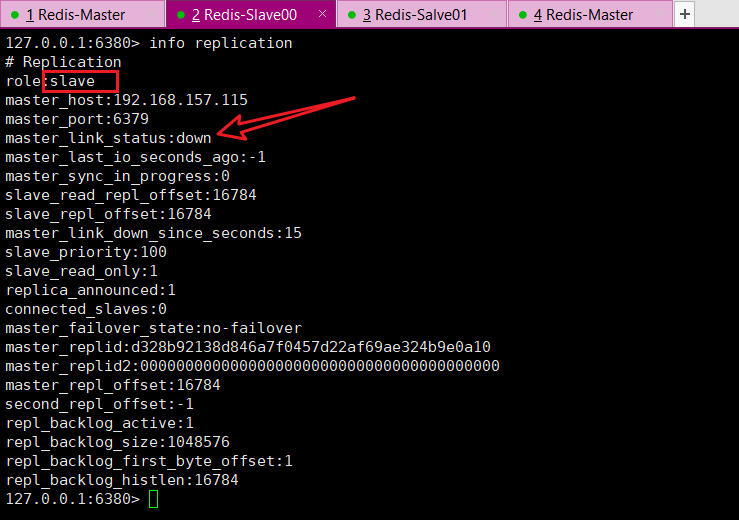
After the host is shut down, is the master-slave relationship still there after restarting? Can the slave machine still copy smoothly?
The relationship is still there and will not change
Can copy smoothly
After a certain host goes down, the master continues. Can the slave keep up with the big team after restarting?
Can
One master and two slaves manually specify the operation command
delete configuration file entry
The master-slave relationship in the above configuration file is fixed and written in the configuration file.
Next, we will delete the configuration items in the configuration file from the host, and the 3 hosts are in the status of the host, and each is not subordinate .
# 注释掉 slave00、slave01中的下面内容 replication 192.168.157.115 6379That is three masters
specify affiliation
slave00 slave
slaveof 192.168.157.115 6379
slave01 slave
slaveof 192.168.157.115 6379
Configure VS commands
configuration file, persistent
Manual command, effective at the time
Matryoshka
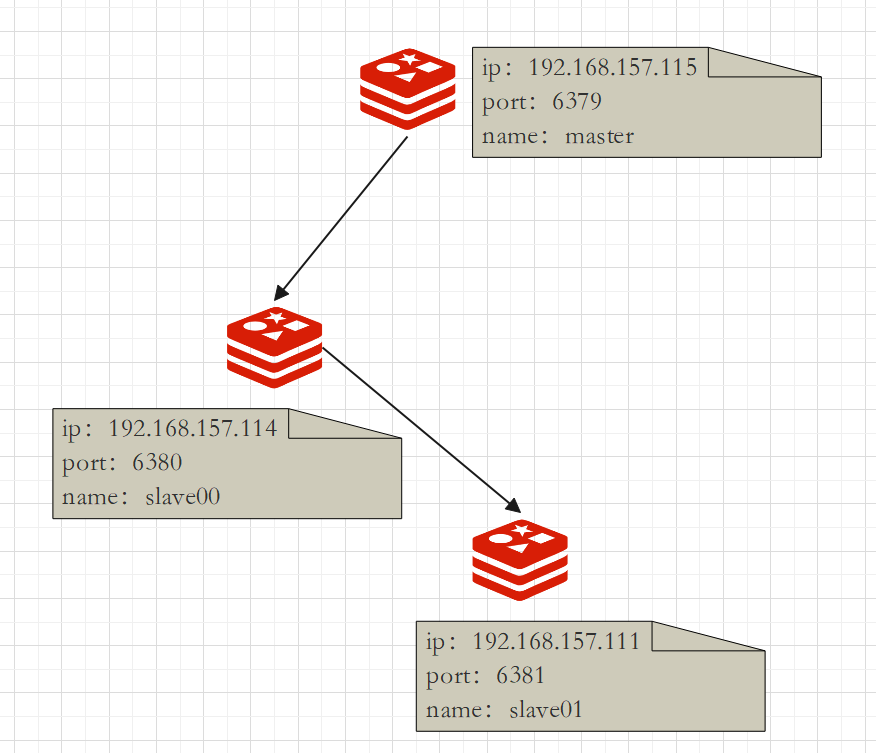
Purpose: Effectively reduce the write pressure of the main master
The midway change will clear the previous data and recreate and copy the latest one.
Order:
slaveof newMasterIp nenwMasterPort
still not capable of writing
anti-client
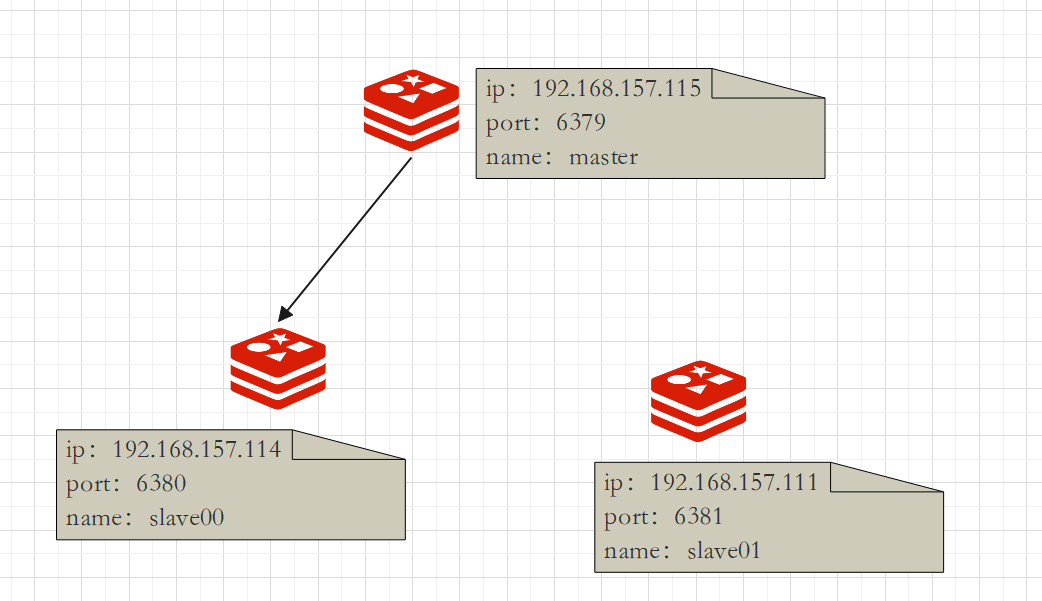
The current database stops synchronizing with other databases and becomes the master database.
There is no master-slave system, and you are the master.
Order:
slaveof no one
Principle and Workflow of Replication
- After the slave successfully connects to the master, it will send a sync command. When the slave connects to the master for the first time, a complete synchronization (full copy) will be automatically executed, and the original data of the slave itself will be overwritten by the master data.
- After receiving the sync command, the master node will start to save snapshots in the background (that is, RDB persistence, RDB will be triggered during master-slave replication), and at the same time collect all received commands for modifying the data set and cache them. The master node executes RDB persistence After the transformation is completed, the master sends the RDB snapshot file and all cached commands to all slaves to complete a synchronization, and the slave service saves and loads the database file data into the memory after receiving the database file data, thus completing the replication initialization.
- repl-ping-replica-period 10 (default 10 seconds), keep in touch every ten seconds to prevent communication failure.
- The master continues to automatically pass the newly collected modification commands to the slave one by one to complete the synchronization.
- The master will check the offset in the backlog. Both the master and the slave will save a copied offset and a masterId. The offset is saved in the backlog. The master will only copy the data after the copied offset to the slave, which is similar to a breakpoint resume.
downside of copying
-
Replication Delay, Signal Attenuation
Since all write operations are performed on the Master first, and then updated to the Slave synchronously, there is a certain delay in synchronizing from the Master to the Slave machine. When the system is very busy, the delay problem will be more serious, and the number of Slave machines will increase. It will also make this problem worse.
-
The master hangs, there is no new master
By default, a master will not be automatically reselected in the slave node, requiring manual intervention.