introduction
For a large-scale Internet applications, to store and access massive amounts of data has become the bottleneck of the system design, the stability and scalability of the system caused great problems. By segmentation data to improve site performance, scale-out data layer architecture has become the preferred way of R & D personnel.
• level of segmentation database: you can reduce the load on a single machine, while maximizing reducing downtime caused by the loss;
• Load balancing strategy: You can reduce the access load on a single machine, reducing the likelihood of downtime;
• clustering solutions: to solve the problem of database downtime caused by a single point database can not be accessed;
• separate read and write strategy: the maximum speed and increase the amount of concurrent data reads applications;
Problem Description
1, the larger the amount of a single table of data, read-write locks, the insertion operation to re-index the lower the efficiency.
2, a single library data is too big (1T-2T is a limit to the amount of data to database)
3, a single database server too much pressure
4, bottleneck write speed (several hundreds of concurrency)
Ideas to solve the problem: according to their actual situation, when a single large table when the table is divided, the database is too large when the library is divided, consider the case of high concurrency separate read and write and clusters.
Data splitting methods are: the partition, sub-table, the sub-library
• Partition
• a data table is divided into N blocks, in the end only logically a table, but the underlying physical block is composed of N
• sub-table
• is to a table according to certain rules decomposed into N independent entity table with storage space. The system needs to read and write in accordance with defined rules indicate corresponding word, then operate it.
• sub-libraries
Once the points table, a library table will be more and more
Compared to the entire database library, a table is a book. When looking to find something in a book, regardless of if the chapters, look for efficiency will decline. And the same token, in the database is partitioned.
Partition
When considering the use of zoning?
• A query speed table has been slow to affect the use of time.
• sql optimized
•Big amount of data
• The data in the table is segmented
• operations on the data often involves only part of the data, but not all of the data
Partition problem
• Key can improve query efficiency
Points table
When considering sub-table?
• A query speed table has been slow to affect the use of time.
• sql optimized
•Big amount of data
• When frequently inserted or joint inquiry, slows down
Sub-table to solve the problem
• The sub-table, single table to improve concurrency, and disk I / O performance improves, the write operation efficiency is improved
• Query a short time
• data distributed in different files, disk I / O performance improvement
• the impact of data read-write lock becomes smaller
• Insert database to rebuild index data reduction
Differences and relations between the partition and sub-tables
• Table partitions and sub-purpose is to reduce the burden of the database to improve the efficiency of CRUD table.
• partition where data is stored only in a table changes, sub-table is a table into multiple tables.
• When Sheremetyevo, and the table data is relatively large, two methods can be used in conjunction with each other.
• When lightly loaded, but the table data relatively long time, can be partitioned only.
Common sub-district list of policy rules (similar)
• Range (range)
• Hash (hash)
• Split by time
After • Hash table modulo the number of points in accordance with
• Save the configuration database in the authentication library is to create a DB, the DB saved separately user_id mapping to the DB
Sub-libraries
When considering the use of sub-libraries?
• A single DB storage space is not enough
• With the increase in query volume single database server has no way to support
Sub-library solve the problem
• Its main purpose is to break through single-node database server I / O capacity constraints, database scalability to address the problem.
Vertical Split
• The need to join tables or relationship does not exist can be placed on different servers in different database systems.
• divided according to business vertical. For example: as the business is divided into funds, membership, order three databases.
• issues need to be addressed: Cross-transaction database, jion inquiries and other issues.
Split Horizontal
• For example, most of the sites. And user data are relevant, the user can, in accordance with the data into the user levels.
• divided according to the rules, the general level of the library is divided after the vertical sub-library. For example, the number of orders processed daily is massive, the level can be divided according to certain rules. Issues to be addressed: data routing and assembly.
Separate read and write
• For the timeliness of data is not high, it can ease the pressure through the database to read and write separation. Problems to be solved: the distinction between what the business is allowed a certain time lag in business, as well as data synchronization problems.
Ideas:
Vertical Library -> sub-library levels -> separate read and write
After the data split issue facing
problem
• support the transaction, sub-library sub-table, it becomes a distributed transaction,
After the sub-library sub-table, it becomes a distributed transaction. If you rely on the database itself distributed transaction management capabilities to execute the transaction, it will pay a high performance costs; if by the application program to help control the formation transactions on program logic, would burden programming.
When cross-database • join, cross-table problems
• sub-library sub-table, separate read and write using a distributed, distributed in order to ensure strong consistency, will inevitably bring about delays, resulting in reduced performance, system complexity increases.
After the sub-library sub-table operation between the association table will be limited, we can not join tables located in different sub-library can not join a different sub-table size table, the results of a query to complete the original business, you may need multiple queries to carry out. Rough Solution: Global Table: basic data, all libraries have a copy. Redundant fields: some fields such queries do not have to join a. System layer assembly: all inquiries are then assembled, is more complex.
Common solution:
• For between no strict boundaries in different ways, different characteristics, different emphases. According to the actual situation, the characteristics of each mode to perform processing.
• Use a third-party database middleware (Atlas, Mycat, TDDL, DRDS), while business with the need to upgrade the system stored data.
Evolution of data storage
Single table in one database
• Single-library is the most common single-table database design, for example, there is a user (user) table in the database db, all users can be found in the db library user table.
Single Kudrow table
• As the number of users increases, the amount of data the user table will be larger when the data reaches a certain degree of time table for user queries will gradually slow down, thus affecting the performance of the entire DB. If you are using mysql, there is a more serious problem is that when you need to add a time, all read and write operations will lock mysql table, only waiting period.
• can be cut user level will be divided in some way, the table structure to produce two identical user_0000, user_0001 such as tables, user_0000 + user_0001 + ... data happens to be a complete data.
Multi-table multi-database
As the amount of data storage space of a single DB perhaps not enough, as the amount of increase in a single query the database server has no way to support. This time can then split the database level.
to sum up
Overall, the priority partition. When the partition can not meet the demand, we began to consider the points table, a reasonable score sheet for improved efficiency will be better than partition.
Vertical Library -> sub-library levels -> separate read and write
Practical operation
1, a single multi-table library
Single Library of multi-table is a horizontal split data, the same as the structure of the table of multiple tables, split the data according to different rules, for the data stored in the table.

This is the year I installed a data table split the data, stored data when stored according to the year of the data for the table, our business inquiries are also carried out by year, generally do not have the data query across the year, so avoid merging multi-table queries after the data.
2, more than a single database table
Exactly the same database, install different rules to store their data, the following is my spring boot multi data source configuration:
# More data sources
custom.datasource.names = jiangsu, anhui, shandong, hubei, hunan, fujian
custom.datasource.jiangsu.type=com.zaxxer.hikari.HikariDataSource
custom.datasource.jiangsu.driverClassName=com.mysql.jdbc.Driver
custom.datasource.jiangsu.url=jdbc:mysql://127.0.0.1:3306/nda_jiangsu?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.jiangsu.username=root
custom.datasource.jiangsu.password=
custom.datasource.anhui.type = com.zaxxer.hikari.HikariDataSource
custom.datasource.anhui.driverClassName=com.mysql.jdbc.Driver
custom.datasource.anhui.url=jdbc:mysql://127.0.0.1:3306/nda_anhui?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.anhui.username=root
custom.datasource.anhui.password=
custom.datasource.shandong.type=com.zaxxer.hikari.HikariDataSource
custom.datasource.shandong.driverClassName=com.mysql.jdbc.Driver
custom.datasource.shandong.url=jdbc:mysql://127.0.0.1:3306/nda_shandong?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.shandong.username=root
custom.datasource.shandong.password=
custom.datasource.hubei.type = com.zaxxer.hikari.HikariDataSource
custom.datasource.hubei.driverClassName=com.mysql.jdbc.Driver
custom.datasource.hubei.url=jdbc:mysql://127.0.0.1:3306/nda_hubei?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.hubei.username=root
custom.datasource.hubei.password=
custom.datasource.hunan.type = com.zaxxer.hikari.HikariDataSource
custom.datasource.hunan.driverClassName=com.mysql.jdbc.Driver
custom.datasource.hunan.url=jdbc:mysql://127.0.0.1:3306/nda_hunan?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.hunan.username=root
custom.datasource.hunan.password=
custom.datasource.fujian.type = com.zaxxer.hikari.HikariDataSource
custom.datasource.fujian.driverClassName=com.mysql.jdbc.Driver
custom.datasource.fujian.url=jdbc:mysql://127.0.0.1:3306/nda_fujian?useUnicode=yes&characterEncoding=UTF-8
custom.datasource.fujian.username=root
custom.datasource.fujian.password=
This data is split according to the province to ensure the data integrity of each province
In a related business operations when, according to the province where the user queries the corresponding database:
DynamicDataSourceContextHolder.setDataSourceType(provincename);
3, multi-table multi-library
When introduction of multi-table multi-database, to introduce a lightweight sub-library sub-table tool, sharding-jdbc, which is Dangdang own implementation of basic JDBC database of multi-table multi-database solutions. Lets you completely according to a single database single table in time to write business code, the problem of multi-table multi-library has sharding-jdbc to help you solve, they need to realize their sub-library sub-table rules interfaces, configure the sub-library sub-table rules.
pom.xml configuration

Interface library to achieve sub-rule
public class DemoDatabaseShardingAlgorithm implements PreciseShardingAlgorithm{ @Override
public String doSharding(Collectioncollection, PreciseShardingValue preciseShardingValue) {
for (String each : collection) {
System.out.println(each+"=="+preciseShardingValue.getValue());
if (each.endsWith(Long.parseLong(preciseShardingValue.getValue().toString()) % 2+"")) {
return each;
}
}
throw new IllegalArgumentException();
}
}
To achieve sub-meter rule Interface
public class DemoTableShardingAlgorithm implements PreciseShardingAlgorithm{
@Override
public String doSharding(Collectioncollection, PreciseShardingValue preciseShardingValue) {
for (String each : collection) {
System.out.println(each+"=2="+preciseShardingValue.getValue());
if (each.endsWith(Long.parseLong(preciseShardingValue.getValue().toString()) % 2+"")) {
return each;
}
}
throw new IllegalArgumentException();
}
}
Call rules
@Bean(name = "shardingDataSource")
DataSource getShardingDataSource() throws SQLException {
ShardingRuleConfiguration shardingRuleConfig;
shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(getUserTableRuleConfiguration());
shardingRuleConfig.getBindingTableGroups().add("user_info");
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_id", DemoDatabaseShardingAlgorithm.class.getName()));
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_id", DemoTableShardingAlgorithm.class.getName()));
return new ShardingDataSource(shardingRuleConfig.build(createDataSourceMap()));
}
After this is completed, the business will be in full accordance with the code on the line to write a single table, Sharding-JDBC will automatically help you achieve sub-library sub-table database inserts, as well as multi-table query when the data consolidation.
Sharding-JDBC using JDBC protocol layer expansion in sub-library sub-table is a lightweight component that provides services to jar form, the core idea is small but beautiful complete the core of things.
Sharding-JDBC also provides the ability to read and write separation, to reduce the pressure for writing library.
Further, Sharding-JDBC JPA may be used in the scene, as JPA, Hibernate, Mybatis, Spring JDBC Template like any Java ORM framework.
But now Sharding-JDBC only supports mysql database
And then there's a third-party plug-ins can also be achieved mycat insert and query data sub-library sub-table, but mycat is based on the Proxy, which MySQL replication of the agreement, the Mycat Server disguised as a MySQL database, and Sharding-JDBC is JDBC-based interfaces the extension, in the form of a lightweight jar package of services provided.
mycat inquiry started in the use of its own has become a virtual database, and business processes is a virtual database mycat connection, and then connect the actual database implementation mycat sub-library sub-table data.
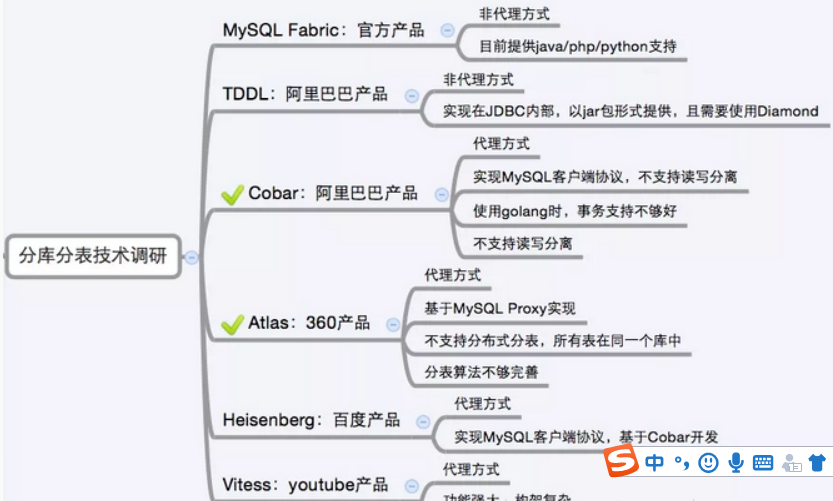
Sub-library sub-table program Products
currently on the market of sub-library sub-table middleware relatively large, agent-based approach in which there is MySQL Proxy and Amoeba, Hibernate framework is based on Hibernate Shards, based jdbc there Dangdang sharding-jdbc, based on similar maven plug-in mybatis of mushroom Street mushroom Street TSharding, by rewriting the spring of Cobar ibatis template class Client.
There are some big companies open source products: