A vertical split
Vertical resolution is to the module table are divided into different database tables (or of course, the principle does not destroy the third paradigm)
Second, the level of split
Vertical segmentation module only by the table into different databases, but does not solve the problem of a large amount of a single table of data, and is to bring a level segmentation table according to certain rules to divide the data into different tables or database.
Scale-up and Scale-out difference
Scale Out refers Application can be extended in the horizontal direction. For general data center applications, Scale out means that when you add more machines, applications can still make good use of the resources of these machines to improve their efficiency so as to achieve good scalability.
Scale Up Application means can extend in the vertical direction. General terms of a single machine, Scale Up is worth when a compute node (machine) to add more CPU Cores, storage devices, the use of more memory, applications can take full advantage of these resources to enhance their efficiency so as to achieve good scalability
2.1 How to use a horizontal split database
Horizontal split split the table, according to specific business needs, according to registered some time, take the touch, account rules, year and so on.
Three, MYSQL master-slave replication
3.1, the concept of
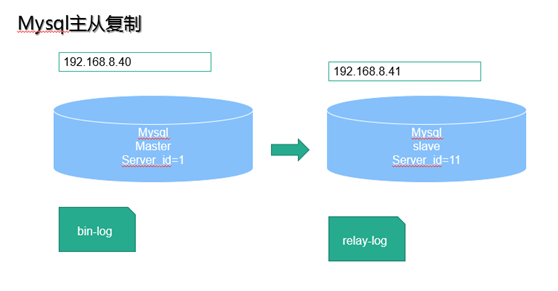
MySQL-A affect the operation of the database, the database in the execution log are written to the local system A. Suppose the event database, the real-time changes in the operation of the system log, the port 3306 MYSQL-A through the network sent MYSQL-B. After receiving MYSQL-B, write local log System B, and then a section of the complete database events in the database. So, change the MYSQL-A, MYSQL-B will change, so the so-called MYSQL replication, ie MYSQL replication.
In the above model, MYSQL-A is the master, i.e. master, MYSQL-B is from the server, i.e. slave.
Log system A, in fact, it is MYSQL log type in the binary log, which is designed to modify the database table to save all actions that bin log. [Note MYSQL will be after the statement is executed before the lock is released, written to the binary log, transaction security]
Log System B, not a binary log, because it is copied from the binary log MYSQL-A's over, is not produced its own database changes, feeling a little relay, called relay logs that relay log.
Can be found by the above mechanism may ensure consistent database data MYSQL-A and MYSQL-B, but certainly a time delay, i.e. the data MYSQL-B is delayed. [Even if the network does not consider what factors, database operations MYSQL-A is performed concurrently, but MYSQL-B can only be read from a relay log in under execution. Thus MYSQL-A write operation is very frequent, MYSQL-B is likely to keep up. ]
3.2 environment to build
1, to prepare the environment: Two windows operating system were ip: 172.27.185.1 (main), 172.27.185.2 (from)
2, connected to the main service (172.27.185.1) server, from the node assigned to the account authority.
GRANT REPLICATION SLAVE ON *.* TO 'root'@'172.27.185.2' IDENTIFIED BY 'root';
3, in the main service my.ini file new
| server-id=200 log-bin=mysql-bin relay-log=relay-bin relay-log-index=relay-bin-index |
Restart mysql service
4, the new service from the my.ini file
| server-id = 210 replicate-do-db = itmayiedu # need to synchronize database |
Restart mysql service
5, the main database synchronization from the service
| # Need to close all connections Multiple connections stop slave; # Establish the main pipeline from change master to master_host='172.27.185.1',master_user='root',master_password='root'; # Start Sync start slave; # Viewing Status, Logs show slave status; |
Four, separate read and write
4.1 What are separate read and write
In the database cluster architecture, so that the main library is responsible for handling transactional queries, and select from a library only handles queries, so that both read and write clear division of labor to improve the overall performance of the database. Of course, the primary database Another feature is responsible for transactional queries to synchronize data changes resulting from the library, which is writing.
4.2, read and write separation benefits
1) sharing server pressure, improve the system processing efficiency of the machine
Read and write separation applies to read than to write a scene, if there is one server, when a lot of time select, update and delete are blocked, waiting for the end of select, high concurrent performance data does not select these visits, while only responsible for master-slave respective write and read, a great degree of ease and S X lock lock contention;
If we have a 3 from the master, without considering the above-mentioned unilateral 1 provided from the library, it is assumed there are 10 writes 1 minute, 150 reading. Then, the main 3 1 Total 40 corresponding to the write, read and the total number has not changed, so on average bear per server 10 reads and writes 50 (library does not bear the main reading operation). Thus, while the write has not changed, but the share is read greatly improve system performance. Further, when the reading is assessed, but also indirectly enhance the performance of writing. So, overall performance improved, in fact, take the machine and change the bandwidth performance;
2) increase redundancy, improve service availability, when a database server downtime can adjust the other one with the fastest speed recovery services from library
Five, MyCat
5.1 What is Mycat
Is an open source distributed database system, but generally because the database has its own database engine, while Mycat unique database engine does not own, said all the strict sense and can not be considered a complete database system, can only be in a role as a bridge between the application and the database middleware.
在Mycat中间件出现之前,MySQL主从复制集群,如果要实现读写分离,一般是在程序段实现,这样就带来了一个问题,即数据段和程序的耦合度太高,如果数据库的地址发生了改变,那么我的程序也要进行相应的修改,如果数据库不小心挂掉了,则同时也意味着程序的不可用,而对于很多应用来说,并不能接受;
引入Mycat中间件能很好地对程序和数据库进行解耦,这样,程序只需关注数据库中间件的地址,而无需知晓底层数据库是如何提供服务的,大量的通用数据聚合、事务、数据源切换等工作都由中间件来处理;
Mycat中间件的原理是对数据进行分片处理,从原有的一个库,被切分为多个分片数据库,所有的分片数据库集群构成完成的数据库存储,有点类似磁盘阵列中的RAID0.
配置server.xml:
<!-- 添加user --> <user name="mycat"> <property name="password">mycat</property> <property name="schemas">mycat</property> </user> <!-- 添加user --> <user name="mycat_red"> <property name="password">mycat_red</property> <property name="schemas">mycat</property> <property name="readOnly">true</property> </user>
配置schema.xml:
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://org.opencloudb/"> <!-- 与server.xml中user的schemas名一致 --> <schema name="mycat" checkSQLschema="true" sqlMaxLimit="100"> <table name="t_users" primaryKey="user_id" dataNode="dn1" rule="rule1"/> <table name="t_message" type="global" primaryKey="messages_id" dataNode="dn1" /> </schema> <dataNode name="dn1" dataHost="jdbchost" database="weibo_simple" /> <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostMaster" url="172.27.185.1:3306" user="root" password="root"> </writeHost> <writeHost host="hostSlave" url="172.27.185.2:3306" user="root" password="root"/> </dataHost> </mycat:schema>