Here is a tool I use python anaconda.
1. First create a scrapy project:
Open anaconda promt command line ( note this is not to use cmd to open the windows command line ), to the next need to create a directory of the project, the implementation of "scrapy startproject dmoz" "Create Project

Note that project into the directory that was created when, not directly "cd d: \ python \ workspace", you need to return the original directory to the root directory, it can be switched disk.
After creating the project, go to the project directory, you can see the directory structure as follows:

Tuturial into the directory:

2. Define the variables need to use the file in items.py
import scrapy class DmozItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title=scrapy.Field() link=scrapy.Field() # desc=scrapy.Filed()
3. Go to the next spider folder, create a file dmoz_spider.py for crawling data
First determine the climb to take the address of the website, where we crawl dmoz site of the news media and the dictionary catalog page:
http://dmoztools.net/Computers/Software/Shareware/News_and_Media/
http://dmoztools.net/Computers/Software/Shareware/Directories/
Reptile crawling need to limit the scope of, or after the end of the crawl to work, it might be crawling unknown URL information, reptiles limited range of code:
allowed_domains=['dmoztools.net']
To "" http://dmoztools.net/Computers/Software/Shareware/Directories/ an example to show information web page ":
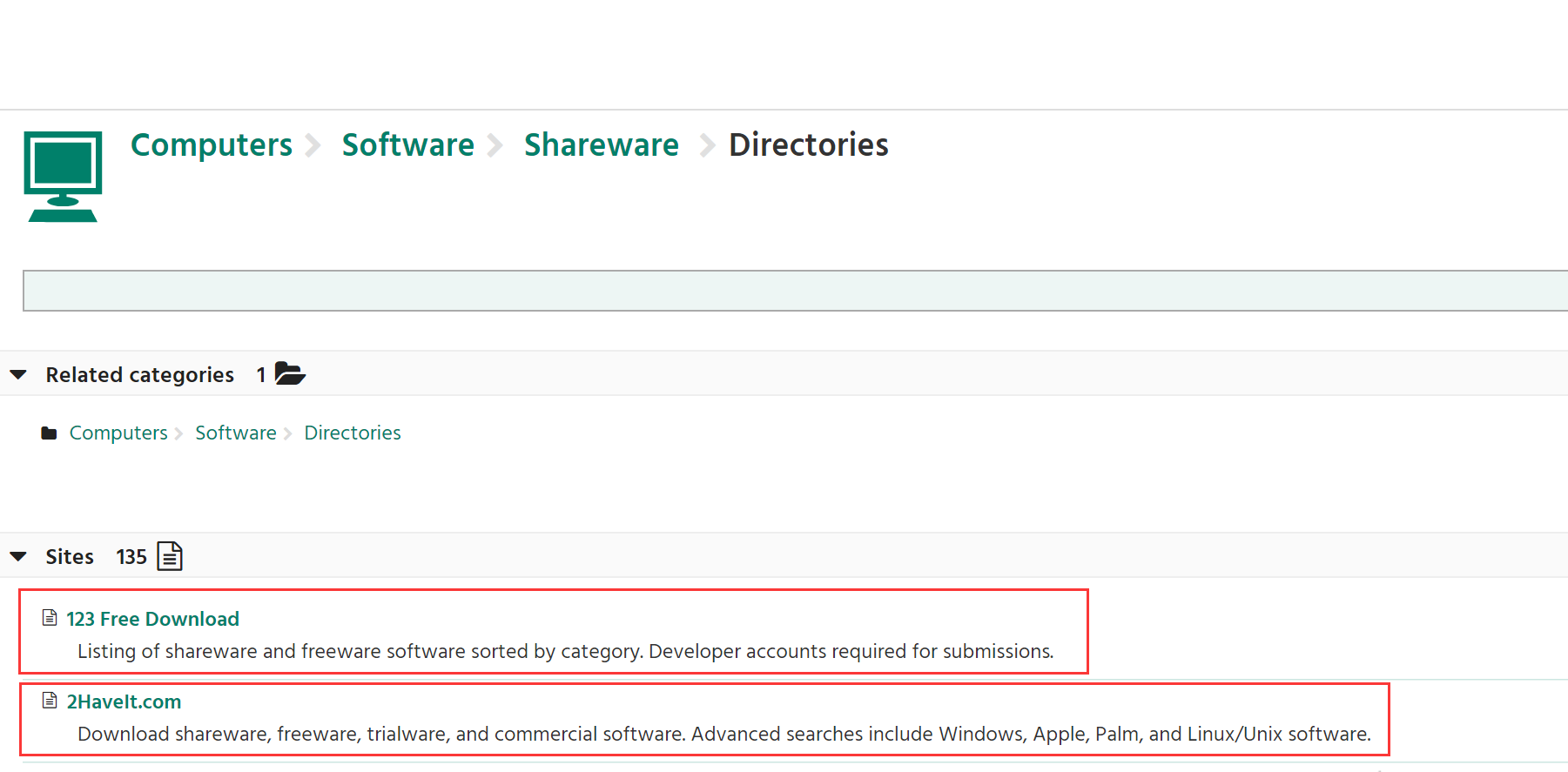
Here URL will show a lot of information corresponding to the classification, we need to take is to climb out of the red box marked URL name and the corresponding link.
See red frame requires a corresponding position in the code:
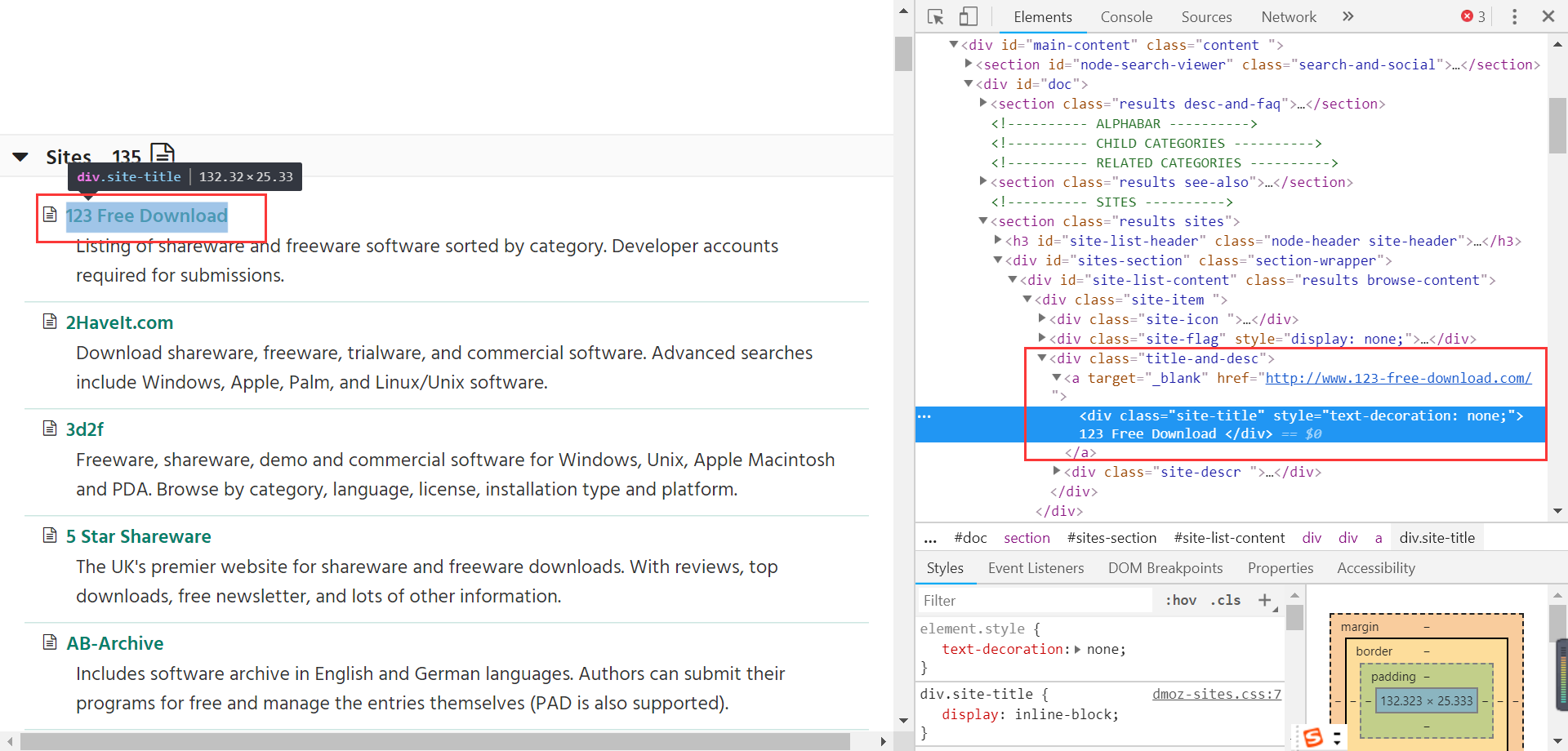
You can see the page corresponding to the link source location: a label under the div tag. But there are many div tags, and how to locate the div tag a label where it? Positioned by the corresponding tag css style.
As used herein, the crawling xpath function specified tag data.
sites=sel.xpath('//div[@class="title-and-desc"]')
[@ Class = "title-and-desc"] used to designate corresponding div style.
import scrapy from tuturial.items import DmozItem class DmozSpider(scrapy.Spider): name="dmoz" allowed_domains=['dmoztools.net']#爬取范围,防止爬虫在爬取完指定网页之后去爬取未知的网页 #爬取的初始地址 start_urls=[ 'http://dmoztools.net/Computers/Software/Shareware/News_and_Media/', 'http://dmoztools.net/Computers/Software/Shareware/Directories/' ] #当根据爬取地址下载完内容后,会返回一个response,调用parse函数 def parse(self,response): # filename=response.url.split('/')[-2] # with open(filename,'wb') as f: # f.write(response.body) sel=scrapy.selector.Selector(response) #查看网页中的审查元素,确定需要爬取的数据在网页中的位置,根据所在的标签进行爬取 #在我们需要爬取的这两个网页中,列出的目录网址都在div标签中,但是网页中有很多div标签,需要根据div标签的css #样式进行进一步确定,使用[@class=""]来指定对应的css样式 sites=sel.xpath('//div[@class="title-and-desc"]') items=[] #对div中的每一条记录进行处理 for site in sites: #实例化items.py指定的类,用于存储爬取到的数据 item=DmozItem() #刚刚查询到的div下的a标签下的div标签下存储着对应的链接的名称 item['title']=site.xpath('a/div/text()').extract() #刚刚查询到的div下的a标签下的href属性下存储着对应的链接 item['link']=site.xpath('a/@href').extract() # desc=site.xpath('text()').extract() #将爬取出来的数据存储到items中 items.append(item) # print(title,link) return items
注意需要引入到items文件:
from tuturial.items import DmozItem
该文件的name指定爬虫的名称,所以该名称必须是唯一的,这样才可以根据爬虫的名称找到对应的执行代码。
在anaconda prompt进入到爬虫工程下执行爬虫文件,并将爬取到的数据存储到json文件中
![]()
-o指定存储的文件,-t指定存储的格式。
在工程目录下就可以看到item.json文件了。
items.json文件的内容为:

对应的链接名称和网址就存储到文件中了。