
Hello everyone, I am Wang Chunxiao from the Shandong Provincial Computing Center (National Supercomputing Jinan Center). I have participated in supercomputing Internet projects since 2022. I am mainly responsible for the research and development of a unified storage platform for computing networks, and I have also done some work on storage bases. After a lot of research, I finally chose the Alluxio platform. After more than a year of hard work, I have made some progress. I am very grateful to Alluxio for its support and help.
Next, we will focus on the theme of supercomputing Internet and share with you from three aspects:
(1) Problems and challenges existing in the construction of supercomputing Internet;
(2) Research on key technologies of supercomputing Internet unified storage platform;
(3) Application and future development of supercomputing Internet
1. Problems and challenges in the construction of supercomputing Internet

First of all, let me briefly introduce the National Supercomputing Jinan Center. It was founded in 2011 and is the birthplace of my country’s domestic server "Sunway Blu-ray". Of course, the scale of Sunway Blu-ray has now increased from petaflops to exascale. Starting in 2019, we have begun to develop and build a universal platform based on the domestic platform. That is, the Sunward Supercomputing Platform, whose CPU, GPU, and storage bandwidth have reached a considerable scale, plays an important supporting role in many industries in Shandong Province.
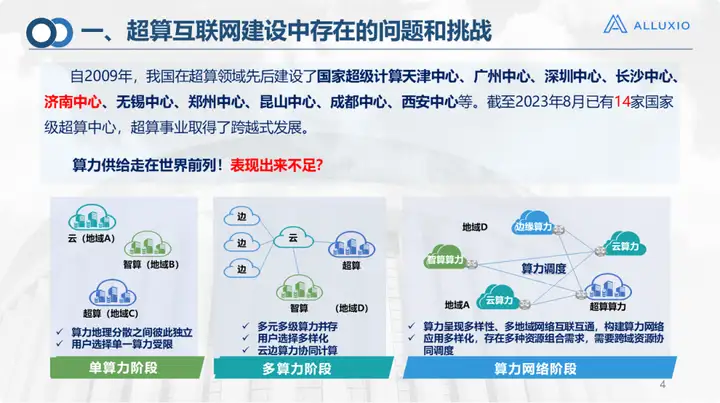
Since 2009, our country has successively established many supercomputing centers. By August 2023, our country will have 14 national-level supercomputing centers, more than 30 intelligent computing centers, and more than 500 large cloud data centers. . With such a size, it is also at the forefront of global computing power supply.
Nowadays, with the surge in demand for large models and many other things, some deficiencies in computing power have also been exposed. This is inseparable from the complexity of our application development: today's applications can no longer be solved by computing power alone. In the past, you might just take some data and a model and run it on a certain resource. . Now is the stage of multi-computing power. In some relatively large-scale application scenarios, there are demands for the scale and type of computing power and storage. For example, converged computing such as cloud computing, high-performance computing, and AI computing, as well as the scenario of computing in the east and in the west proposed by our country, it is actually difficult to solve the problem if we just simply increase the computing power or storage in a certain area. Of course, there are regional differences in my country's demand for computing power and the distribution of resources. This is also the original intention of my country's proposal to build a supercomputing Internet.

In April 2023, the Ministry of Science and Technology launched the work of building a national supercomputing Internet to build an integrated supercomputing power network and service platform. The National Supercomputing Jinan Center is also one of the supercomputing Internet units. What it is currently doing is to conduct unified resource management, control and coordination of wide-area computing power storage and networks to achieve optimal resource layout.
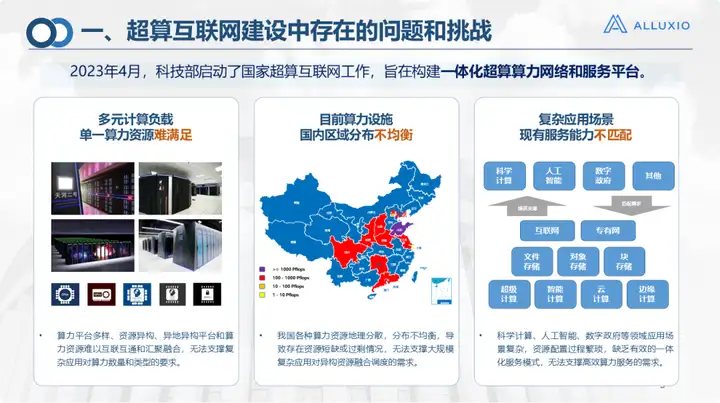
The National Supercomputing Center in Jinan has been planning and building a supercomputing Internet since 2016, and has done work at all levels. Of course, there are also many problems encountered in the construction and application of computing power networks.
1. The first one is the issue of diversified computing power platforms, including the endless emergence of various cloud platforms, AI platforms, and storage platforms;
2. The second is the problem of heterogeneous resources, including domestic group chip standards, which are very different, and storage systems also have various interfaces, which are very scattered, have complex structures, and have many protocols, which makes it difficult to achieve interconnection and interoperability. , a unified platform needs to be built;
3. The third one is the uneven distribution of computing power, which is a common problem in our country. Taking Shandong Province as an example, computing is in Jinan and storage is in Zibo. If there is a bottleneck in the intermediate network, it is basically difficult to achieve remote mounting, calling or even transmission.
There are also some complex application scenarios, such as the fields of marine meteorological remote sensing, whose operating procedures are relatively complex. The data may be stored in one place and needs to be transferred to another place for data preprocessing, simulation, model training and other operations. , but these operations may have to be carried out on different platforms, or even in different regions. Without an integrated service platform, it is difficult to work, and it is difficult to be proficient in the use of all platforms. These problems and challenges This is also what we need to solve when building the core of the supercomputing Internet.
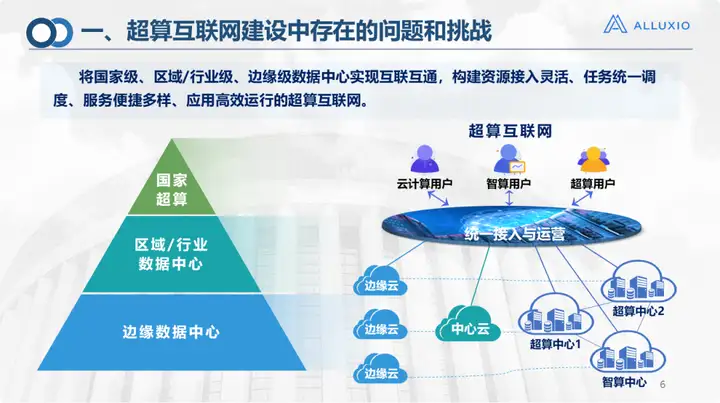
This is the framework of the supercomputing Internet - allowing national, enterprise/regional-level, and edge-level data centers to achieve interconnection and hierarchical classification. Interoperability is to enable relatively easy and unified access and operation of computing power, storage, and networks. It can flow like water and electricity and be provided to the upper levels for use by various users. Some are even mixed users: for example, an algorithm must use both high performance and AI. This is also our construction goal.
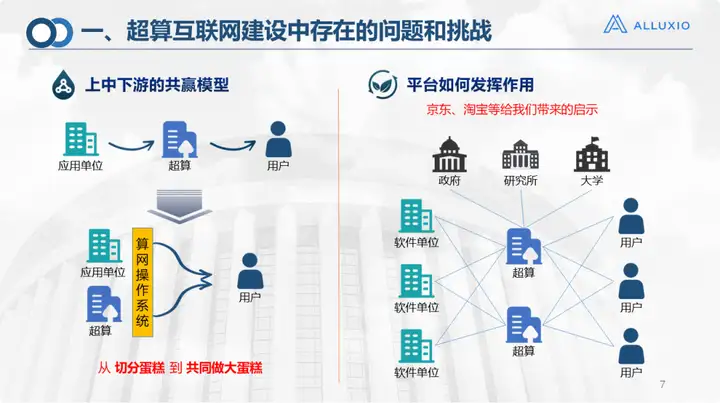
This was the industry chain for the development of supercomputing Internet at that time. In the past, users used computing power, storage, and software through supercomputing or data centers, and there was a third-party application unit. Now we have added a layer in the middle, with three layers of upper, middle and downstream definitions: the application units and supercomputers on the first layer serve as providers of parallel resources, and the supercomputing network operating system serves as the middle layer to provide corresponding computing power and Storage network. The operating model can refer to platforms such as JD.com and Taobao, which can be used as an intermediate platform. Like JD.com and Taobao, they sell goods, but what we operate is a resource, which is a model that changes from cutting the cake to making the cake together.
2. Research on key technologies of supercomputing Internet unified storage platform
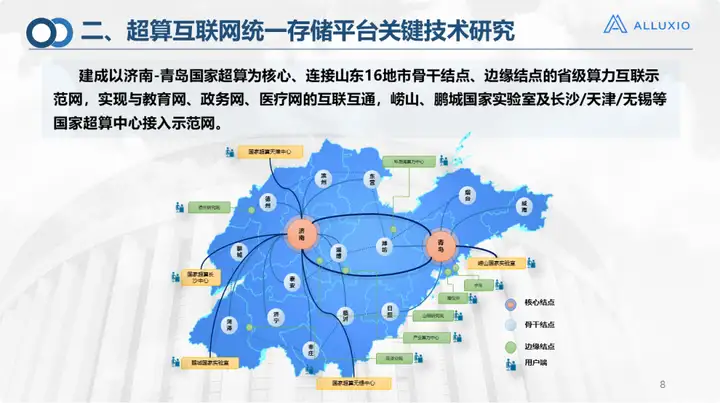
This is the current construction situation of the supercomputing Internet. It was first piloted in Shandong, covering 16 cities in Shandong Province, including the two core nodes of Jinan and Qingdao. Now Jinan and Qingdao operate through high-speed interconnection, and the remaining cities are Use dedicated lines. There are also 30 edge nodes that can be connected using sdone or the Internet. At the same time, we have also connected to 28 computing clusters and 45 storage systems of 7 types. The unified platform of the storage system is built with Alluxio. This is the scale of our first version of the supercomputing network operating system. Currently, the upper layer supports three types of services: cloud computing, HPC and AI. It mainly provides resources in three aspects:
1. Computing resources;
2. Storage resources;
3. Network resources.
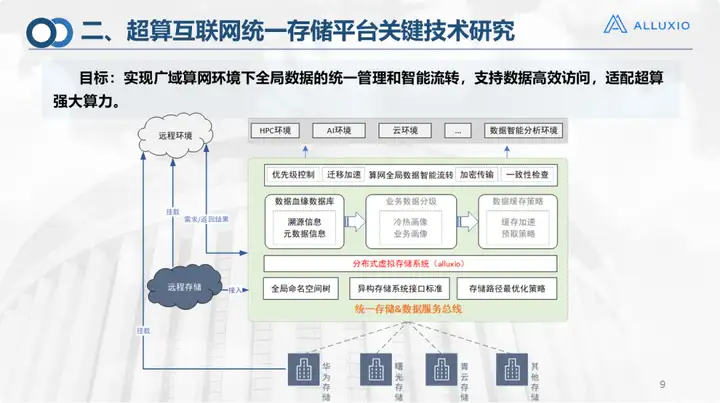
Because I am mainly responsible for the unified storage platform, I will focus on introducing the unified storage platform. This is the design framework diagram at that time. You can see the goal of the unified storage platform. In fact, it does not matter whether it is any kind of storage at the bottom or on the cloud. We all need to manage storage. The layer that deals with the storage system uses Alluxio as the storage base. On this basis, we have also done some optimization work, including path optimization, data migration strategy, encrypted transmission, consistency check, etc. Some of them are still in the verification process and have not been added to the first version. This is our overall plan.
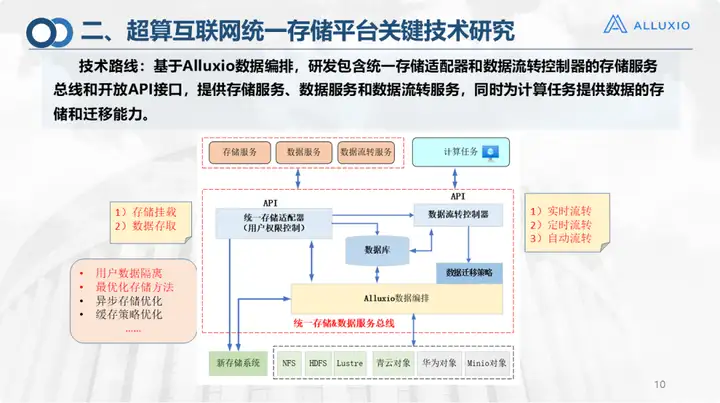
This picture shows that the core technology of the unified storage platform is the design of the service bus. I took it out separately because we developed a unified storage adapter and data flow controller on the upper layer based on Alluxio, and embedded Three circulation strategies: real-time circulation, scheduled circulation, and automatic circulation. It also provides storage, data and data transfer services for this code calculation portal (the main portal above), and can provide interface and mounting functions. Like the unified storage adapter, currently we can do:
1. Automatic storage mounting;
2. Multiple ways of accessing data, including interface, client, and command line, are all supported.
Of course, we have also done research on user data isolation and optimal storage methods, which have already been embedded. The data flow controller does a lot of work and has three flow strategies:
1. Real-time transfer is mainly for users, because users apply for a piece of storage in Jinan and a piece of storage in Qingdao on our platform. If they want to migrate the data in real-time, the user specifies the original address and target of the migration. Address, select the transfer speed, and automatically match the migration strategy. We have also done some research on intelligent models to calculate the running time of tasks in different states and select the optimal strategy.
2. Scheduled transfer. Scheduled transfer is currently targeted at ocean and campus scenarios. For example, on-site data in schools or on the ocean is on the edge, because some of it is video data and the data scale is particularly large. If you want to do research and need to save, there is actually no such storage device at the edge. Without such a large amount of storage devices, you may need to do scheduled data migration every week. Configure the specified migration source address and target address within a defined time. We also use the intelligent model to select the optimal strategy based on task time and deadline. You can choose to do it at night or when the network traffic is relatively low.
3. Automatic transfer is also a feature, which is to intelligently select the data and location to be migrated based on the rules engine. There may be many such scenarios. We have customized several such scenarios, and there is an introduction to automatic flow scenarios later. It is judged based on whether the data is stored and calculated separately. For example, if it is stored in Zibo and I want to calculate it in Jinan, if the network conditions do not allow the user to agree, we can automatically migrate it to him. Of course, you can determine whether the data is prefetched by combining the mode access of the metadata database and the access frequency of hotspot data.
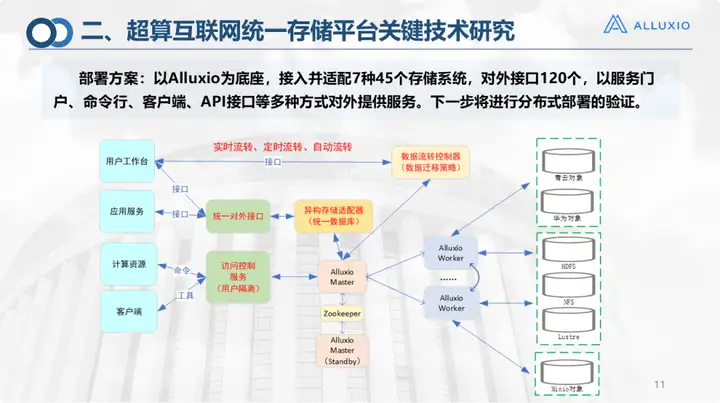
This is our deployment plan, which is currently connected to the storage systems listed in the figure, including Alibaba Cloud. There are about 130 external interfaces, which can provide external services through service portal command line, client, API, etc. We still follow the classic deployment of Alluxio for the current deployment. In the later stage, we hope to achieve distributed deployment: currently, due to network restrictions, all exports are concentrated in Jinan. Although 16 cities have already established China Unicom, exports have not yet been liberalized. For example, the connection between Qingdao and Zibo has not been fully tested. Under such circumstances, there is no problem with this layout. All storage must be deployed and called by the Alluxio Master Jinan general platform when used. If other networks are liberalized, I hope that if the computing is in Qingdao, the storage will also be in Qingdao. , can realize local mounting without having to notify the Master in Jinan to let it do the allocation. This actually adds one more step, so we are now also doing testing and verification of distributed deployment.
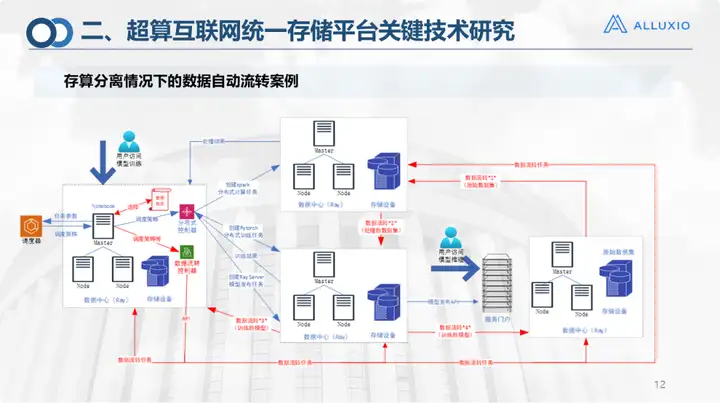
This is a case of automatic transfer of storage and calculation separation. Of course, this is also the actual scenario of the current smart campus.
Our storage devices and computing resources have all been managed on a unified storage platform and cloud platform, called a multi-cloud management platform. In this case, our computing network operating system will have an overall schedule. In this environment, all data currently exists in the rightmost data center. Assume that this data center is in Zibo, and the user is in Jinan, or submits training tasks on the main platform. , after submission, there will be a general schedule to determine where the computing resources, pre-training environment, and training environment are to delineate locations and generate resources, because this container needs to be automatically generated based on demand, and will be generated based on the data view (ours in Alluxio A layer of data view is made above). According to the data view and data flow controller, the data is migrated from the original address to the target address for training. For this scenario, four flows are actually required:
√ Flow from the original data set to training in the pre-training pre-processing environment;
√ After processing, you need to go to the training environment for training;
√ Finally, the model needs to be fed back to the user;
√ If the user configures it, it must be fed back to the final scene (like a campus) before performing inference operations.
Therefore, we have specified the circulation process in several specific industry scenarios.
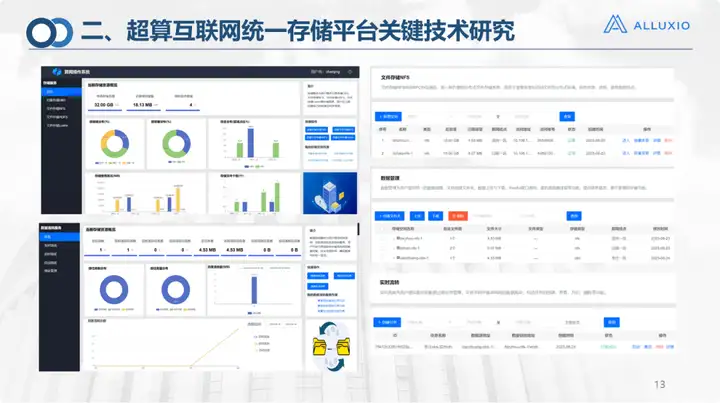
This is the current interface of our unified storage platform V1.0. It has been released on the main portal, including the service portal and the management portal. The service portal has a total of 6 modules and more than 20 sub-modules.
For the unified storage platform, we still have follow-up work to continue: including distributed deployment of Alluxio Master nodes and unified scheduling management on its upper layer. Then there is the prefetching of data, which is the optimization of the data caching mechanism, including the design of prefetching, association rules, and more importantly, we want to do tiered storage, which is what we need to do later.
3. Application and future development of supercomputing Internet

The following introduces the current applications of supercomputing Internet in various industries:
We will focus on developing the supercomputing Internet in the second half of 2022, but in fact we have been laying out the layout since 2016, so we already have some applications in many industries: including oceans, materials, meteorology, and environmental protection. , ecology, industrial simulation, education and other aspects.
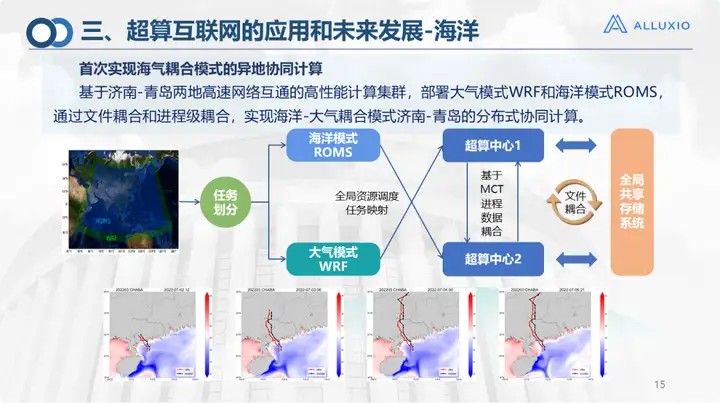
This is the ocean coupling model, which is an interconnected network that we jointly built with the Laoshan Laboratory. As you can see, calculations in the ocean may be relatively complicated. Ocean model calculations and atmospheric model calculations are required. The current atmospheric model is performed on the Qingdao supercomputer, and the ocean model is performed on the Jinan supercomputer, and then file coupling is performed. This is the first time we have implemented remote collaborative computing in 2023, and has achieved good results.

In the field of remote sensing, we also have a relatively complete data flow scenario. This is the data from the National Earth Observation Scientific Data Center: first it is transmitted to Jinan Supercomputer through a dedicated line, and then it is stored in block files through some sorting and storage operations. In storage such as objects, data products are produced and shared after processing. This is also our first system for data collection and processing that separates cross-domain storage and calculation. We also applied to establish the National Earth Observation Depository and Computing Center.
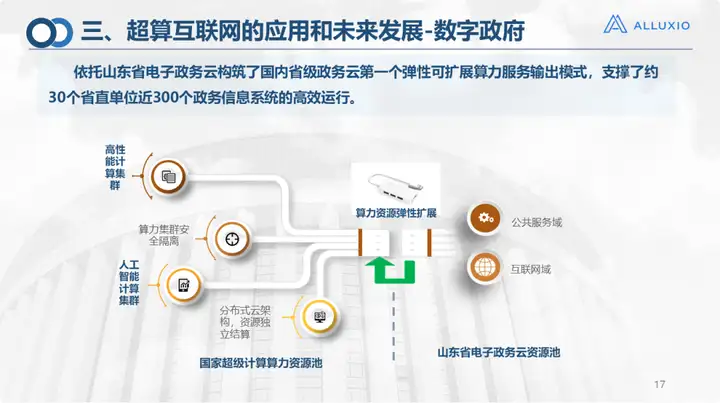
In the field of digital government, because e-government itself is in our unit, we currently support the efficient operation of 30 provincial units and 300 government systems in Shandong Province. Of course, this is mainly operations on the cloud, which is to make resources Elastic expansion.
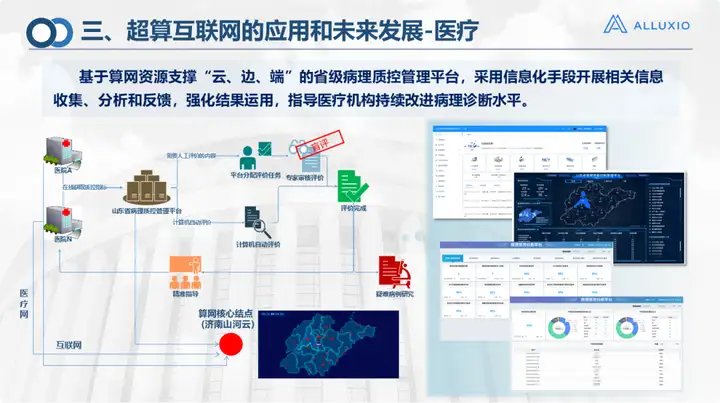
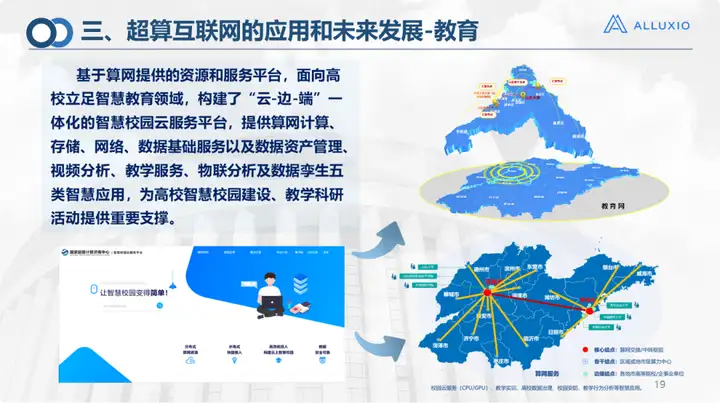
In fields such as medical care and education, cloud and edge work is mainly done. It is the computing and storage network provided by Suanwang, including the scheduled transfer mentioned above. In the smart campus scenario, we have done the project of Qilu University of Technology, and we have done more in campus application scenarios.
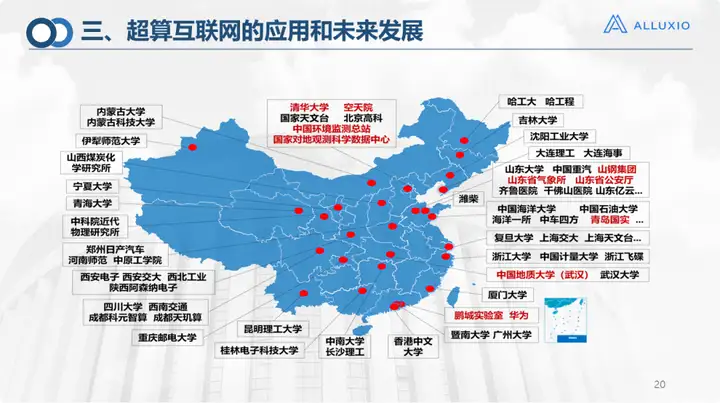
Finally, let me introduce the company. Our applications cover more than 2,000 enterprises/universities/institutions across the country, and have also received wide recognition at home and abroad. I think it is actually necessary to build a computing power network, which will help revitalize our current stock of computing power resources. If we have a supercomputing Internet, we should improve the utilization of computing resources, enable computing power to be monetized, and allow computing power centers, supercomputing centers and other data centers to operate sustainably and healthily, and in some supercomputing ecosystems, It has better applications in the fields of environmental protection, oceans, and remote sensing, and I believe there will be broader application scenarios in the future.
