
Author: Mu Yan
Do you encounter the following problems when configuring the YAML pipeline?
- When similar task scenarios are executed in batches in a single pipeline, multiple jobs with similar logic need to be defined in YAML. The more jobs there are, the longer the pipeline YAML configuration is, the more repeated code in YAML is, the code reusability is low, and the readability is poor;
- Administrators manage multiple pipelines in a unified manner. The multi-application technology architecture is similar to the R&D process. When only a few construction and deployment parameters are inconsistent, each pipeline needs to modify the differentiated parameters independently, resulting in high configuration costs. When each pipeline is configured independently, unified management and control cannot be achieved. , poor maintainability;
- The pipeline YAML is a static file, and the task execution logic is fixed when the pipeline is saved. However, the pipeline execution process of some R&D scenarios needs to be clarified at runtime and cannot be configured in advance. Ordinary pipeline YAML cannot satisfy this scenario.
In this regard, Yunxiao Flow pipeline YAML introduces template syntax, which supports the use of template languages to dynamically render pipeline YAML, which can meet the batch configuration scenarios of multiple jobs with the same or similar logic, meet the dynamic generation scenarios of multiple jobs on demand, and help reduce the duplication of pipeline YAML. Code, flexibly orchestrate multitasking.
What is template syntax
Template is a template language used to define and render text. It can be combined with variables, conditional statements, loop structures, etc., so that YAML files can generate diverse configuration output based on context or external data sources. Dynamic rendering generates pipeline YAML at runtime. .
The Cloud Effect Pipeline introduces the template engine, and template=truespecifies the template mode through the first line of YAML comments in the pipeline. It supports the use of {{ }}defined template language and follows go templatethe native syntax; it supports the use of variablesvariables defined as parameters for the rendering pipeline. Typical applicable scenarios are as follows.
Template syntax core usage scenarios
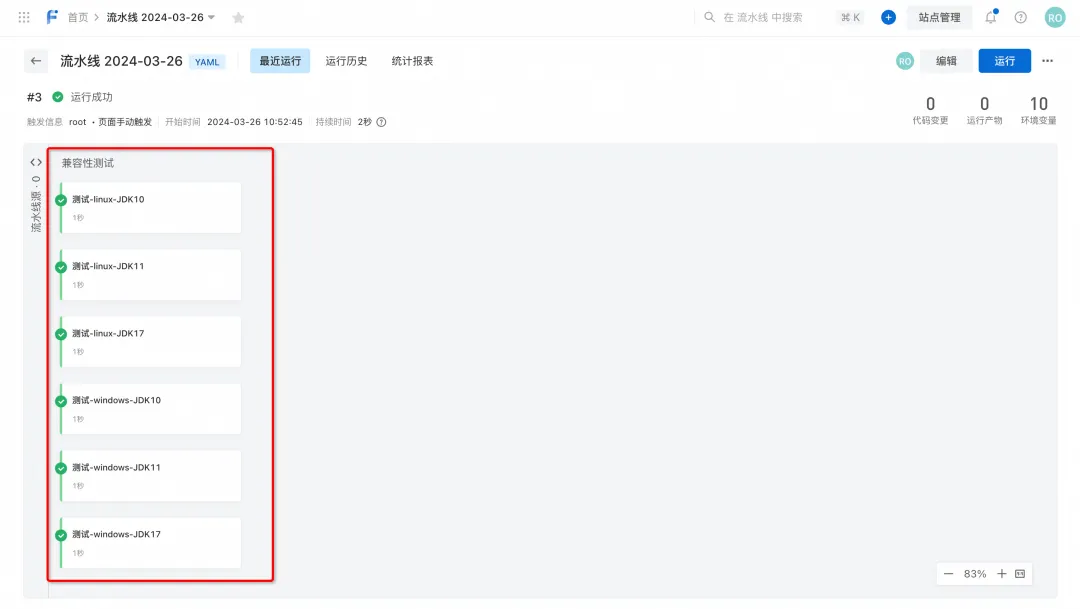
Scenario 1: Multi-operating system, multi-SDK version compatibility test scenario
In some compatibility testing scenarios, if you need to test your code on n different operating systems and m different SDK versions, then you need to define n * m jobs in your pipeline. The execution logic of each job is actually the same. In this scenario, when there are many scenarios that require compatibility testing, the pipeline YAML will be very long, with a lot of repeated code, making it difficult to maintain; and when the Job execution logic is modified, it will need to be modified n * m times.
After the template syntax is introduced, compatibility scenarios can be extracted into variables, and the range syntax can be used to loop through the scenarios and generate multiple jobs in batches, greatly reducing the amount of YAML code; when the job execution logic is modified, only one modification is needed.
For example, in the following code, we traverse 2 operating systems ["linux", "windows"] and 3 JDK versions ["10", "11", "17"], using the range loop of template, it is very Conveniently, 6 jobs with the same logic are generated.
# template=true
variables:
- key: osList
type: Object
value: ["linux", "windows"]
- key: jdkVersionList
type: Object
value: ["10", "11", "17"]
stages:
build_stage:
name: 兼容性测试
jobs: # 双层循环,生成 2*3 个Job
{{ range $os := .osList}}
{{ range $jdk := $.jdkVersionList}}
{{ $os }}_JDK{{ $jdk }}_job:
name: 测试-{{ $os }}-JDK{{ $jdk }}
my_step:
name: 执行命令
step: Command
with:
run: |
echo 'test on {{ $os }}-JDK{{ $jdk }}"
{{ end }}
{{ end }}
The running effect of the pipeline is as follows:
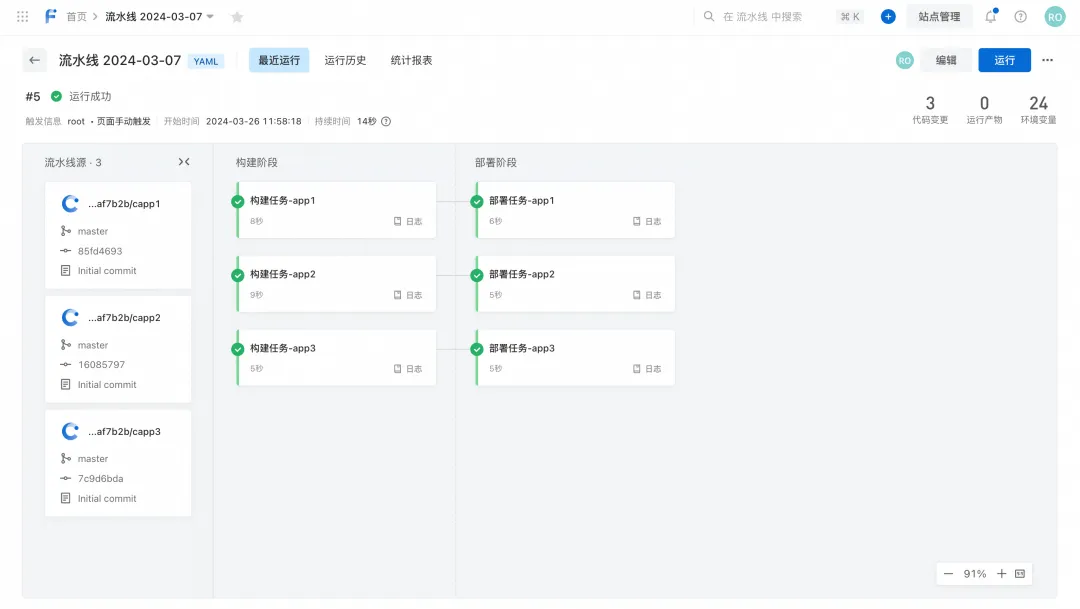
Scenario 2: Dynamically build and deploy multiple applications on demand
In the scenario of joint release of multiple applications under one system, a modification of business requirements will only involve some applications under the system, and each release only triggers the construction and deployment of some applications. In this case, the use of static YAML file configuration cannot meet the dynamic generation of application construction and deployment job scenarios.
After the template syntax is introduced, the application can be extracted into variables, and the range syntax can be used to loop through the configuration. According to the application list input during the pipeline runtime, multiple application construction and deployment tasks can be dynamically generated on demand.
As shown in the following example, we have configured multiple application code sources, multiple application building tasks, and multiple application deployment tasks according to the application. Several applications can be dynamically determined to be deployed based on the runtime input environment variable appnames.
# template=true
variables:
- key: appnames
type: Object
value: ["app1", "app2", "app3"]
sources:
{{ range $app := .appnames }}
repo_{{ $app }}:
type: codeup
name: 代码源名称-{{ $app }}
endpoint: https://yunxiao-test.devops.aliyun.com/codeup/07880db8-fd8d-4769-81e5-04093aaf7b2b/c{{ $app }}.git
branch: master
certificate:
type: serviceConnection
serviceConnection: wwnbrqpihykbiko4
{{ end }}
defaultWorkspace: repo_app1
stages:
build_stage:
name: 构建阶段
jobs:
{{ range $app := .appnames }}
build_job_{{ $app }}:
name: 构建任务-{{ $app }}
sourceOption: ['repo_{{ $app }}']
steps:
build_{{ $app }}:
step: Command
name: 构建-{{ $app }}
with:
run: "echo start build {{ $app }}\n"
{{ end }}
deploy_stage:
name: 部署阶段
jobs:
{{ range $app := .appnames }}
deploy_job_{{ $app }}:
name: 部署任务-{{ $app }}
needs: build_stage.build_job_{{ $app }}
steps:
build_{{ $app }}:
step: Command
name: 部署-{{ $app }}
with:
run: "echo start deploy {{ $app }}\n"
{{ end }}
The running effect of the pipeline is as follows:
How to use template syntax in Yunxiao
1) Enter the pipeline YAML editing page and switch to template mode by commenting #template=true on the first line.
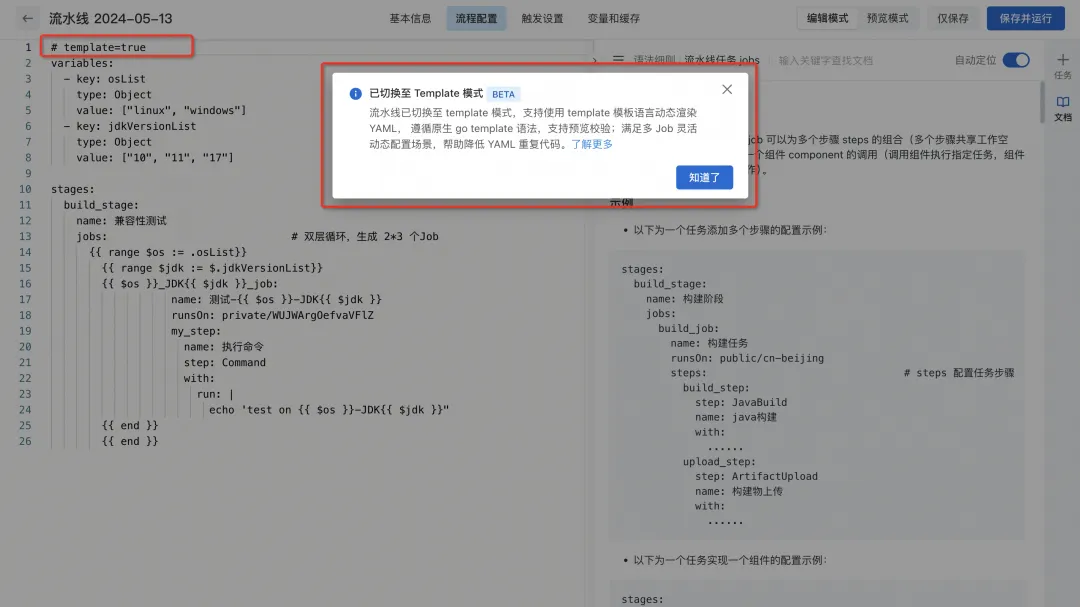
2) After switching to template mode, {{ }} template language definition pipeline is supported.
-
Use environment variables defined by variables as rendering parameters: Use environment variables defined by variables as template rendering parameters, supporting String, Number, Boolean, and Object multiple environment variable types. Supports overwriting environment variables with the same name at runtime.
-
Follow the native go template syntax: Yunxiao Flow pipeline template mode follows the native go template syntax. For details, see: https://pkg.go.dev/text/template. Commonly used syntax is as follows:
{{/* a comment */}} // 注释
{{pipeline}} // 引用
{{if pipeline}} T1 {{end}} // 条件判断
{{if pipeline}} T1 {{else}} T0 {{end}}
{{if pipeline}} T1 {{else if pipeline}} T0 {{end}}
{{range pipeline}} T1 {{end}} // 循环
{{range pipeline}} T1 {{else}} T0 {{end}}
{{break}}
{{continue}}
- In addition, the Yunxiao Flow pipeline template syntax supports the following extension functions to meet more flexible orchestration scenarios.
# add:整数相加函数,参数接收两个及两个以上 Integer
{{ add 1 2 }} // 示例返回:3
{{ add 1 2 2 }} // 示例返回:5
# addf:浮点数相加函数,参数接收两个及两个以上 Number
{{ add 1.2 2.3 }} // 示例返回:3.5
{{ add 1.2 2.3 5 }} // 示例返回:8.5
# replace:字符串替换函数,接收三个参数:源字符串、待替换字符串、替换为字符串
{{ "Hallo World" | replace "a" "e" }} // 示例返回:Hello World
{{ "I Am Henry VIII" | replace " " "-" }} // 示例返回:I-Am-Henry-VIII
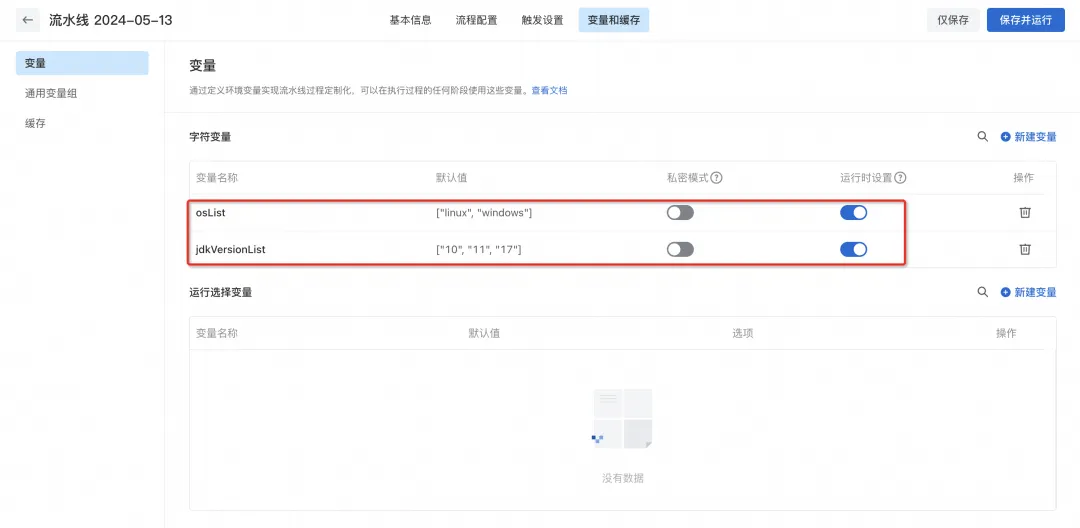
3) Configure environment variables when the pipeline is running, which is used to dynamically render YAML before the pipeline runs.
4) Click "Preview Mode" to support using variables for pre-rendering to verify whether the pipeline meets expectations.
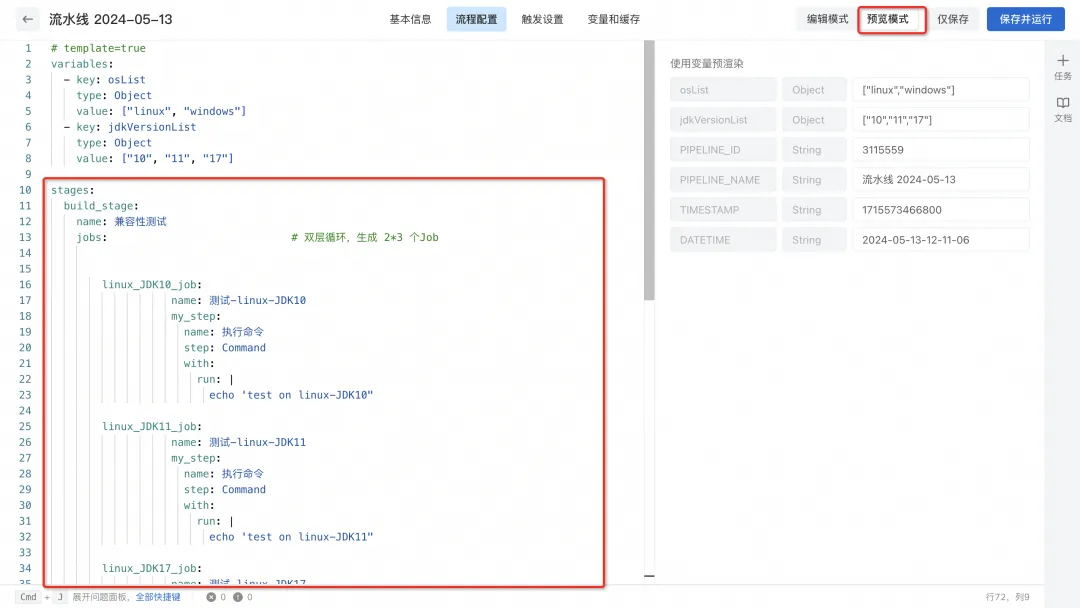
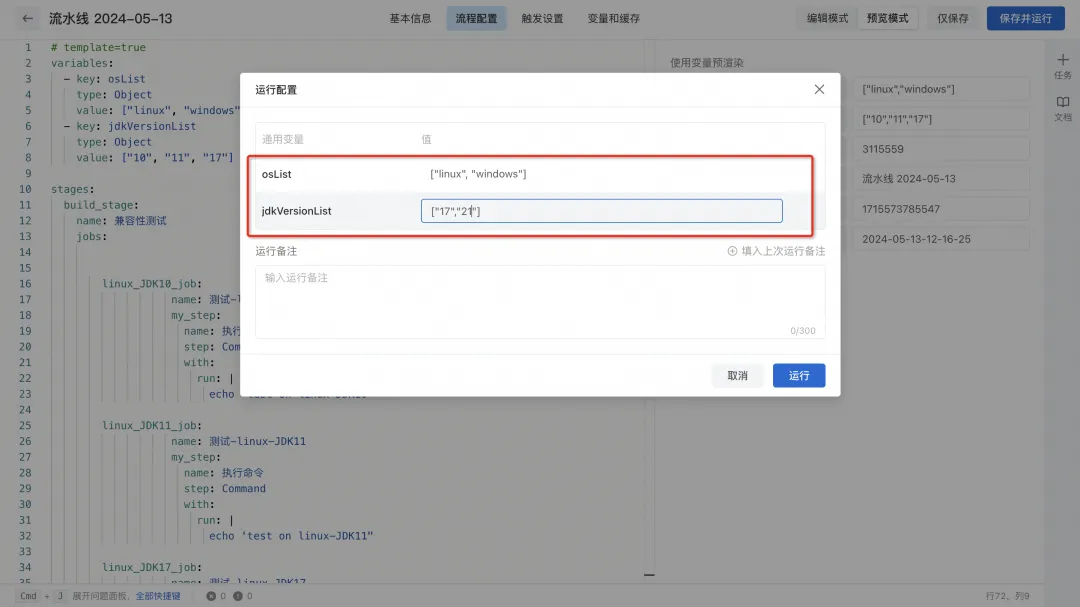
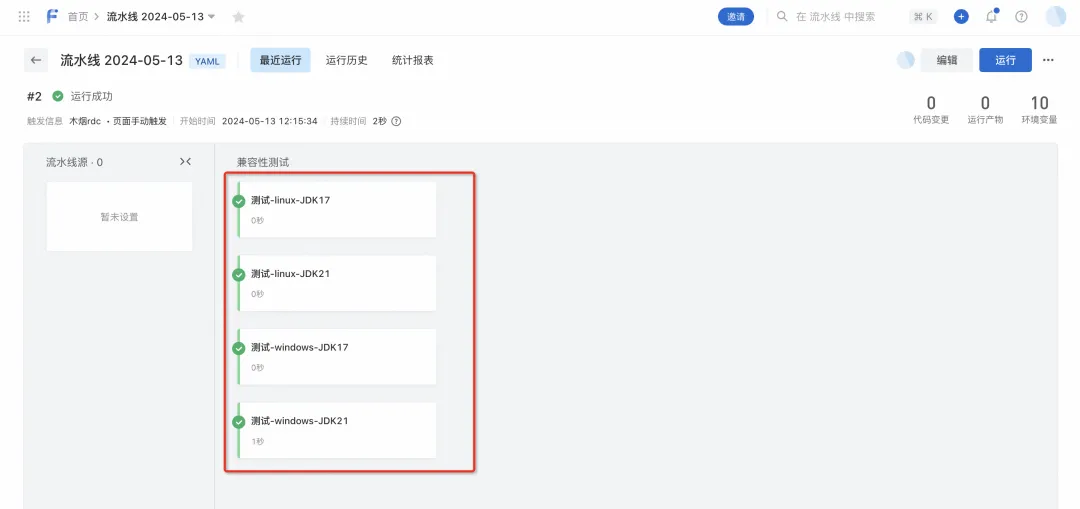
5) After confirming that it is correct, save and trigger the pipeline run. You can modify runtime variables as needed, dynamically render pipeline YAML based on runtime environment variables, and dynamically generate jobs. If the JDK version is modified to ["17", "21"] and the operating system remains ["linux", "windows"], 4 jobs will be dynamically generated.
Click here to use Cloud Effect Pipeline Flow for free or learn more.
Microsoft's China AI team collectively packed up and went to the United States, involving hundreds of people. How much revenue can an unknown open source project bring? Huawei officially announced that Yu Chengdong's position was adjusted. Huazhong University of Science and Technology's open source mirror station officially opened external network access. Fraudsters used TeamViewer to transfer 3.98 million! What should remote desktop vendors do? The first front-end visualization library and founder of Baidu's well-known open source project ECharts - a former employee of a well-known open source company that "went to the sea" broke the news: After being challenged by his subordinates, the technical leader became furious and rude, and fired the pregnant female employee. OpenAI considered allowing AI to generate pornographic content. Microsoft reported to The Rust Foundation donated 1 million US dollars. Please tell me, what is the role of time.sleep(6) here?