

▐ URL Blacklist (Bloom Filter)
10 billion blacklist URLs, each 64B, how to save this blacklist? Determine whether a URL is in the blacklist
Hash table:
If we regard the blacklist as a set and store it in a hashmap, it seems to be too large, requiring 640G, which is obviously unscientific.
Bloom filter:
It's actually a long binary vector and a series of random mapping functions.
It can be used to determine whether an element is in a set . Its advantage is that it only takes up a small amount of memory space and has high query efficiency. For a Bloom filter, its essence is a bit array : a bit array means that each element of the array only occupies 1 bit, and each element can only be 0 or 1.
Each bit in the array is a binary bit. In addition to a bit array, the Bloom filter also has K hash functions. When an element is added to the Bloom filter, the following operations will be performed:
Use K hash functions to perform K calculations on the element value to obtain K hash values.
According to the obtained hash value, the corresponding subscript value is set to 1 in the bit array.
▐Word frequency statistics (divided into files)
2GB memory to find the most frequent number among 2 billion integers
The usual approach is to use a hash table to make word frequency statistics for each number that appears. The key of the hash table is an integer, and the value records the number of times the integer appears. The amount of data in this question is 2 billion. It is possible that a number may appear 2 billion times. In order to avoid overflow, the key of the hash table is 32 bits (4B) and the value is also 32 bits (4B). Then a record of a hash table is Need to occupy 8B.
When the number of hash table records is 200 million, 1.6 billion bytes are required (8*200 million), and at least 1.6GB of memory is required (1.6 billion/2^30,1GB==2^30 bytes== 1000000000). Then 2 billion records require at least 16GB of memory, which does not meet the question requirements.
The solution is to use the hash function to divide the large file with 2 billion numbers into 16 small files. According to the hash function, the 2 billion pieces of data can be evenly distributed to the 16 files. The same number cannot be divided by the hash function. On different small files, assuming the hash function is good enough. Then use a hash function for each small file to count the number of occurrences of each number, so that we get the number with the most occurrences among the 16 files, and then select the key with the highest occurrence from the 16 numbers.
▐Number that does not appear (bit array)
Find the number that does not appear among 4 billion non-negative integers
For the original problem, if a hash table is used to save the numbers that have appeared, then in the worst case 4 billion numbers are different, then the hash table needs to save 4 billion pieces of data, and a 32-bit integer requires 4B, then 4 billion * 4B = 16 billion bytes. Generally, about 1 billion bytes of data requires 1G of space, so it requires about 16G of space, which does not meet the requirements.
Let's change the way and apply for a bit array. The array size is 4294967295, which is about 4 billion bits. 4 billion/8=500 million bytes, so 0.5G space is needed. Each position of the bit array has two states: 0 and 1. So how to use this bit array? Haha, the length of the array just meets the number range of our integers, then each subscript value of the array corresponds to a number in 4294967295, and traverses 4 billion unsigned numbers one by one. For example, if 20 is encountered, then bitArray[20]= 1; when 666 is encountered, bitArray[666]=1, after traversing all the numbers, change the corresponding position of the array to 1.
Find a number that does not appear among 4 billion non-negative integers. The memory limit is 10MB.
One billion bytes of data requires about 1GB of space to process, so 10MB of memory can process 10 million bytes of data, which is 80 million bits. For 4 billion non-negative integers, if you apply for a bit array, 4 billion bit/080 million bit=50, then this will cost at least 50 blocks to process. Let’s analyze and answer using 64 blocks.
Summarize the advanced solutions
According to the 10MB memory limit, determine the size of the statistical interval, which is the bitArr size during the second traversal.
Use interval counting to find the interval with insufficient counts. There must be numbers in this interval that do not appear.
Do a bit map mapping of the numbers in this interval, and then traverse the bit map to find a number that does not appear.
My own opinion
If you are just looking for a number, you can perform high-bit modulus operations, write it to 64 different files, and then process it all at once through bitArray in the smallest file.
4 billion unsigned integers, 1GB memory, find all numbers that appear twice
For the original problem, bit map can be used to represent the occurrence of numbers. Specifically, it is to apply for a bit type array bitArr with a length of 4294967295×2. Two positions are used to represent the word frequency of a number. 1B occupies 8 bits, so the bit type array with a length of 4294967295×2 occupies 1GB of space. . How to use this bitArr array? Traverse these 4 billion unsigned numbers. If num is encountered for the first time, set bitArr[num 2+1] and bitArr[num 2] to 01. If num is encountered for the second time, set bitArr[num 2+1 ] and bitArr[num 2] are set to 10. If num is encountered for the third time, bitArr[num 2+1] and bitArr[num 2] are set to 11. When I encounter num again in the future, I find that bitArr[num 2+1] and bitArr[num 2] have been set to 11 at this time, so no further settings are made. After the traversal is completed, traverse bitArr in sequence. If it is found that bitArr[i 2+1] and bitArr[i 2] are set to 10, then i is the number that appears twice.
▐Duplicate URL (by machine)
Find duplicate URLs among 10 billion URLs
The solution to the original problem uses a conventional method for solving big data problems: assigning large files to machines through a hash function, or splitting large files into small files through a hash function. This division is performed until the result of the division meets the resource constraints. First, you need to ask the interviewer what the resource constraints are, including requirements for memory, computing time, etc. After clarifying the restriction requirements, each URL can be allocated to several machines through a hash function or split into several small files. The exact number of "several" here is calculated based on specific resource restrictions.
For example, a large file of 10 billion bytes is distributed to 100 machines through a hash function, and then each machine counts whether there are duplicate URLs in the URLs assigned to it. At the same time, the nature of the hash function determines whether the same URL is It is impossible to distribute the URL to different machines; or split the large file into 1000 small files through the hash function on a single machine, and then use the hash table traversal for each small file to find duplicate URLs; or distribute it to the machine Or after splitting the files, sort them, and then check whether there are duplicate URLs after sorting. In short, keep in mind that many big data problems are inseparable from offloading. Either the hash function distributes the contents of the large file to different machines, or the hash function splits the large file into small files and then processes each small number. collection.
▐ TOPK search (small root pile)
Search a large number of words and find the most popular TOP100 words.
At the beginning, we used the idea of hash shunting to shunt vocabulary files containing tens of billions of data to different machines. The specific number of machines was determined by the interviewer or more restrictions. For each machine, if the amount of distributed data is still large, for example, due to insufficient memory or other problems, the hash function can be used to split the distributed files of each machine into smaller files for processing.
When processing each small file, the hash table counts each word and its word frequency. After the hash table record is established, the hash table is traversed. During the hash table traversal, a small root heap of size 100 is used to select Get the top100 of each small file (the overall unsorted top100). Each small file has its own small root heap of word frequency (the overall unsorted top100). By sorting the words in the small root heap according to word frequency, the sorted top100 of each small file is obtained. Then sort the top100 of each small file externally or continue to use the small root heap to select the top100 on each machine. The top100 between different machines are then sorted externally or continue to use the small root heap, and finally the top100 of the entire tens of billions of data are obtained. For the top K problem, in addition to hash function diversion and word frequency statistics using hash tables, heap structures and external sorting are often used to deal with it.
▐Median (one-way binary search)
10MB memory, find the median of 10 billion integers
Enough memory: If you have enough memory, why worry? Just sort all 10 billion items. You can use bubbling... and then just find the one in the middle. But do you think the interviewer will give you memory? ?
Insufficient memory: The question says it is an integer, but we think it is a signed int, so it is 4 bytes and occupies 32 bits.
Assume that 10 billion numbers are stored in a large file, read part of the file into memory in sequence (not exceeding the memory limit), represent each number in binary, and compare the highest bit of the binary (bit 32, sign bit, 0 is positive, 1 is negative), if the highest bit of the number is 0, the number is written to the file_0 file; if the highest bit is 1, the number is written to the file_1 file.
Thus, 10 billion numbers are divided into two files. Assume that there are 6 billion numbers in the file_0 file and 4 billion numbers in the file_1 file. Then the median is in the file_0 file and is the billionth number after sorting all the numbers in the file_0 file. (The numbers in file_1 are all negative numbers, and the numbers in file_0 are all positive numbers. That is, there are only 4 billion negative numbers in total, so the 5 billionth number after sorting must be located in file_0)
Now, we only need to process the file_0 file (no need to consider the file_1 file anymore). For the file_0 file, take the same measures as above: read part of the file_0 file into memory in sequence (not exceeding the memory limit), represent each number in binary, compare the second highest bit of the binary (the 31st bit), if the second highest bit of the number If it is 0, write it to the file_0_0 file; if the second highest bit is 1, write it to the file_0_1 file.
Now assuming that there are 3 billion numbers in file_0_0 and 3 billion numbers in file_0_1, the median is: the billionth number after the numbers in file_0_0 are sorted from small to large.
Abandon the file_0_1 file and continue to divide the file_0_0 file according to the next highest digit (the 30th position). Assume that the two files divided this time are: there are 500 million numbers in file_0_0_0 and 2.5 billion numbers in file_0_0_1. Then the median is The 500 millionth number after sorting all the numbers in the file_0_0_1 file.
According to the above idea, until the divided file can be directly loaded into the memory, the numbers can be quickly sorted directly to find the median.
▐Short Domain Name System (caching)
Design a short domain name system to convert long URLs into short URLs.
Using the number assigner, the initial value is 0. For each short link generation request, the value of the number assigner is incremented, and then this value is converted into 62 hexadecimal (a-zA-Z0-9), such as the first request At the time of the request, the value of the number assigner is 0, corresponding to hexadecimal a. At the second request, the value of the number assigner is 1, corresponding to hexadecimal b. At the 10001st request, the value of the number assigner is 10000, corresponding to The hexadecimal notation is sBc.
Concatenate the short link server domain name with the 62 hexadecimal value of the assigner as a string, which is the URL of the short link, for example: t.cn/sBc.
Redirection process: After generating a short link, you need to store the mapping relationship between the short link and the long link, that is, sBc -> URL. When the browser accesses the short link server, it gets the original link according to the URL Path, and then performs a 302 redirect. Mapping relationships can be stored using KV, such as Redis or Memcache.
▐Massive comments storage (message queue)
Suppose there is such a scenario. There is a piece of news. The number of comments on the news may be large. How to design the reading and writing of comments?
The front-end page is displayed directly to the user and stored in the database asynchronously through the message queue.
▐Number of online/concurrent users (Redis)
-
Solution ideas for displaying the number of online users on a website
-
Maintain online user table -
Using Redis statistics
-
Display the number of concurrent users of the website
-
Whenever a user accesses the service, the user's ID is written into the ZSORT queue, and the weight is the current time; -
Calculate the number of users of the organization Zrange within one minute based on the weight (i.e. time); -
Delete users Zrem who have expired for more than one minute;
▐Popular Strings (Prefix Tree)
HashMap method
Although the total number of strings is relatively large, it does not exceed 300w after deduplication. Therefore, you can consider saving all strings and their occurrence times in a HashMap. The space occupied is 300w*(255+4)≈777M (of which 4 Represents the 4 bytes occupied by the integer). It can be seen that 1G of memory space is completely sufficient.
The idea is as follows
First, traverse the string. If it is not in the map, store it directly in the map, and the value is recorded as 1; if it is in the map, add 1 to the corresponding value. This step has time complexity O(N).
Then traverse the map to build a small top heap of 10 elements. If the number of occurrences of the traversed string is greater than the number of occurrences of the string at the top of the heap, replace it and adjust the heap to a small top heap.
After the traversal is completed, the 10 strings in the heap are the strings that appear the most. The time complexity of this step O(Nlog10).
prefix tree method
When these strings have a large number of the same prefixes, you can consider using a prefix tree to count the number of occurrences of the string. The nodes of the tree save the number of occurrences of the string, and 0 means no occurrence.
The idea is as follows
When traversing the string, search in the prefix tree. If found, add 1 to the number of strings stored in the node. Otherwise, build a new node for this string. After the construction is completed, add the occurrence of the string in the leaf node. The number of times is set to 1.
Finally, the small top heap is still used to sort the number of occurrences of the string.
▐Red envelope algorithm
Linear cutting method, cutting N-1 knives in one interval. The sooner the better
Double mean method, random in [0~remaining amount/remaining number of people*2], relatively uniform

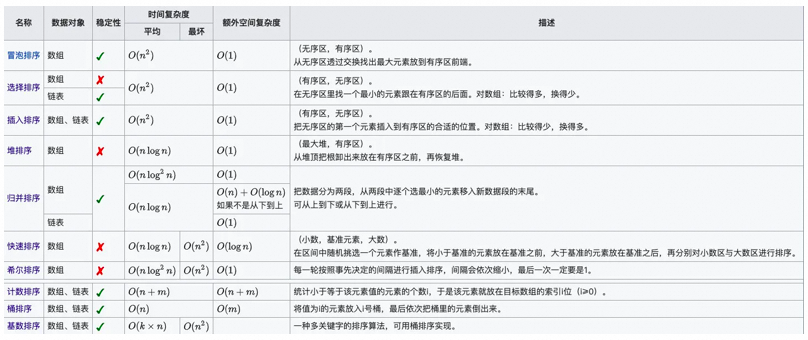
▐Handwriting quick sorting
public class QuickSort {public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}/* 常规快排 */public static void quickSort1(int[] arr, int L , int R) {if (L > R) return;int M = partition(arr, L, R);quickSort1(arr, L, M - 1);quickSort1(arr, M + 1, R);}public static int partition(int[] arr, int L, int R) {if (L > R) return -1;if (L == R) return L;int lessEqual = L - 1;int index = L;while (index < R) {if (arr[index] <= arr[R])swap(arr, index, ++lessEqual);index++;}swap(arr, ++lessEqual, R);return lessEqual;}/* 荷兰国旗 */public static void quickSort2(int[] arr, int L, int R) {if (L > R) return;int[] equalArea = netherlandsFlag(arr, L, R);quickSort2(arr, L, equalArea[0] - 1);quickSort2(arr, equalArea[1] + 1, R);}public static int[] netherlandsFlag(int[] arr, int L, int R) {if (L > R) return new int[] { -1, -1 };if (L == R) return new int[] { L, R };int less = L - 1;int more = R;int index = L;while (index < more) {if (arr[index] == arr[R]) {index++;} else if (arr[index] < arr[R]) {swap(arr, index++, ++less);} else {swap(arr, index, --more);}}swap(arr, more, R);return new int[] { less + 1, more };}// for testpublic static void main(String[] args) {int testTime = 1;int maxSize = 10000000;int maxValue = 100000;boolean succeed = true;long T1=0,T2=0;for (int i = 0; i < testTime; i++) {int[] arr1 = generateRandomArray(maxSize, maxValue);int[] arr2 = copyArray(arr1);int[] arr3 = copyArray(arr1);// int[] arr1 = {9,8,7,6,5,4,3,2,1};long t1 = System.currentTimeMillis();quickSort1(arr1,0,arr1.length-1);long t2 = System.currentTimeMillis();quickSort2(arr2,0,arr2.length-1);long t3 = System.currentTimeMillis();T1 += (t2-t1);T2 += (t3-t2);if (!isEqual(arr1, arr2) || !isEqual(arr2, arr3)) {succeed = false;break;}}System.out.println(T1+" "+T2);// System.out.println(succeed ? "Nice!" : "Oops!");}private static int[] generateRandomArray(int maxSize, int maxValue) {int[] arr = new int[(int) ((maxSize + 1) * Math.random())];for (int i = 0; i < arr.length; i++) {arr[i] = (int) ((maxValue + 1) * Math.random())- (int) (maxValue * Math.random());}return arr;}private static int[] copyArray(int[] arr) {if (arr == null) return null;int[] res = new int[arr.length];for (int i = 0; i < arr.length; i++) {res[i] = arr[i];}return res;}private static boolean isEqual(int[] arr1, int[] arr2) {if ((arr1 == null && arr2 != null) || (arr1 != null && arr2 == null))return false;if (arr1 == null && arr2 == null)return true;if (arr1.length != arr2.length)return false;for (int i = 0; i < arr1.length; i++)if (arr1[i] != arr2[i])return false;return true;}private static void printArray(int[] arr) {if (arr == null)return;for (int i = 0; i < arr.length; i++)System.out.print(arr[i] + " ");System.out.println();}}
▐Handwriting merge
public static void merge(int[] arr, int L, int M, int R) {int[] help = new int[R - L + 1];int i = 0;int p1 = L;int p2 = M + 1;while (p1 <= M && p2 <= R)help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];while (p1 <= M)help[i++] = arr[p1++];while (p2 <= R)help[i++] = arr[p2++];for (i = 0; i < help.length; i++)arr[L + i] = help[i];}public static void mergeSort(int[] arr, int L, int R) {if (L == R)return;int mid = L + ((R - L) >> 1);process(arr, L, mid);process(arr, mid + 1, R);merge(arr, L, mid, R);}public static void main(String[] args) {int[] arr1 = {9,8,7,6,5,4,3,2,1};mergeSort(arr, 0, arr.length - 1);printArray(arr);}
▐Handwritten stacks
// 堆排序额外空间复杂度O(1)public static void heapSort(int[] arr) {if (arr == null || arr.length < 2)return;for (int i = arr.length - 1; i >= 0; i--)heapify(arr, i, arr.length);int heapSize = arr.length;swap(arr, 0, --heapSize);// O(N*logN)while (heapSize > 0) { // O(N)heapify(arr, 0, heapSize); // O(logN)swap(arr, 0, --heapSize); // O(1)}}// arr[index]刚来的数,往上public static void heapInsert(int[] arr, int index) {while (arr[index] > arr[(index - 1) / 2]) {swap(arr, index, (index - 1) / 2);index = (index - 1) / 2;}}// arr[index]位置的数,能否往下移动public static void heapify(int[] arr, int index, int heapSize) {int left = index * 2 + 1; // 左孩子的下标while (left < heapSize) { // 下方还有孩子的时候// 两个孩子中,谁的值大,把下标给largest// 1)只有左孩子,left -> largest// 2) 同时有左孩子和右孩子,右孩子的值<= 左孩子的值,left -> largest// 3) 同时有左孩子和右孩子并且右孩子的值> 左孩子的值, right -> largestint largest = left+1 < heapSize && arr[left+1]> arr[left] ? left+1 : left;// 父和较大的孩子之间,谁的值大,把下标给largestlargest = arr[largest] > arr[index] ? largest : index;if (largest == index)break;swap(arr, largest, index);index = largest;left = index * 2 + 1;}}public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}public static void main(String[] args) {int[] arr1 = {9,8,7,6,5,4,3,2,1};heapSort(arr1);printArray(arr1);}
▐Handwritten singleton
public class Singleton {private volatile static Singleton singleton;private Singleton() {}public static Singleton getSingleton() {if (singleton == null) {synchronized (Singleton.class) {if (singleton == null) {singleton = new Singleton();}}}return singleton;}}
▐Handwritten LRUcache
// 基于linkedHashMappublic class LRUCache {private LinkedHashMap<Integer,Integer> cache;private int capacity; //容量大小public LRUCache(int capacity) {cache = new LinkedHashMap<>(capacity);this.capacity = capacity;}public int get(int key) {//缓存中不存在此key,直接返回if(!cache.containsKey(key)) {return -1;}int res = cache.get(key);cache.remove(key); //先从链表中删除cache.put(key,res); //再把该节点放到链表末尾处return res;}public void put(int key,int value) {if(cache.containsKey(key)) {cache.remove(key); //已经存在,在当前链表移除}if(capacity == cache.size()) {//cache已满,删除链表头位置Set<Integer> keySet = cache.keySet();Iterator<Integer> iterator = keySet.iterator();cache.remove(iterator.next());}cache.put(key,value); //插入到链表末尾}}
//手写双向链表class LRUCache {class DNode {DNode prev;DNode next;int val;int key;}Map<Integer, DNode> map = new HashMap<>();DNode head, tail;int cap;public LRUCache(int capacity) {head = new DNode();tail = new DNode();head.next = tail;tail.prev = head;cap = capacity;}public int get(int key) {if (map.containsKey(key)) {DNode node = map.get(key);removeNode(node);addToHead(node);return node.val;} else {return -1;}}public void put(int key, int value) {if (map.containsKey(key)) {DNode node = map.get(key);node.val = value;removeNode(node);addToHead(node);} else {DNode newNode = new DNode();newNode.val = value;newNode.key = key;addToHead(newNode);map.put(key, newNode);if (map.size() > cap) {map.remove(tail.prev.key);removeNode(tail.prev);}}}public void removeNode(DNode node) {DNode prevNode = node.prev;DNode nextNode = node.next;prevNode.next = nextNode;nextNode.prev = prevNode;}public void addToHead(DNode node) {DNode firstNode = head.next;head.next = node;node.prev = head;node.next = firstNode;firstNode.prev = node;}}
▐Handwriting thread pool
package com.concurrent.pool;import java.util.HashSet;import java.util.Set;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.BlockingQueue;public class MySelfThreadPool {//默认线程池中的线程的数量private static final int WORK_NUM = 5;//默认处理任务的数量private static final int TASK_NUM = 100;private int workNum;//线程数量private int taskNum;//任务数量private final Set<WorkThread> workThreads;//保存线程的集合private final BlockingQueue<Runnable> taskQueue;//阻塞有序队列存放任务public MySelfThreadPool() {this(WORK_NUM, TASK_NUM);}public MySelfThreadPool(int workNum, int taskNum) {if (workNum <= 0) workNum = WORK_NUM;if (taskNum <= 0) taskNum = TASK_NUM;taskQueue = new ArrayBlockingQueue<>(taskNum);this.workNum = workNum;this.taskNum = taskNum;workThreads = new HashSet<>();//启动一定数量的线程数,从队列中获取任务处理for (int i=0;i<workNum;i++) {WorkThread workThread = new WorkThread("thead_"+i);workThread.start();workThreads.add(workThread);}}public void execute(Runnable task) {try {taskQueue.put(task);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}public void destroy() {System.out.println("ready close thread pool...");if (workThreads == null || workThreads.isEmpty()) return ;for (WorkThread workThread : workThreads) {workThread.stopWork();workThread = null;//help gc}workThreads.clear();}private class WorkThread extends Thread{public WorkThread(String name) {super();setName(name);}@Overridepublic void run() {while (!interrupted()) {try {Runnable runnable = taskQueue.take();//获取任务if (runnable !=null) {System.out.println(getName()+" readyexecute:"+runnable.toString());runnable.run();//执行任务}runnable = null;//help gc} catch (Exception e) {interrupt();e.printStackTrace();}}}public void stopWork() {interrupt();}}}package com.concurrent.pool;public class TestMySelfThreadPool {private static final int TASK_NUM = 50;//任务的个数public static void main(String[] args) {MySelfThreadPool myPool = new MySelfThreadPool(3,50);for (int i=0;i<TASK_NUM;i++) {myPool.execute(new MyTask("task_"+i));}}static class MyTask implements Runnable{private String name;public MyTask(String name) {this.name = name;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic void run() {try {Thread.sleep(1000);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}System.out.println("task :"+name+" end...");}@Overridepublic String toString() {// TODO Auto-generated method stubreturn "name = "+name;}}}
▐Handwritten consumer producer pattern
public class Storage {private static int MAX_VALUE = 100;private List<Object> list = new ArrayList<>();public void produce(int num) {synchronized (list) {while (list.size() + num > MAX_VALUE) {System.out.println("暂时不能执行生产任务");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}for (int i = 0; i < num; i++) {list.add(new Object());}System.out.println("已生产产品数"+num+" 仓库容量"+list.size());list.notifyAll();}}public void consume(int num) {synchronized (list) {while (list.size() < num) {System.out.println("暂时不能执行消费任务");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}for (int i = 0; i < num; i++) {list.remove(0);}System.out.println("已消费产品数"+num+" 仓库容量" + list.size());list.notifyAll();}}}public class Producer extends Thread {private int num;private Storage storage;public Producer(Storage storage) {this.storage = storage;}public void setNum(int num) {this.num = num;}public void run() {storage.produce(this.num);}}public class Customer extends Thread {private int num;private Storage storage;public Customer(Storage storage) {this.storage = storage;}public void setNum(int num) {this.num = num;}public void run() {storage.consume(this.num);}}public class Test {public static void main(String[] args) {Storage storage = new Storage();Producer p1 = new Producer(storage);Producer p2 = new Producer(storage);Producer p3 = new Producer(storage);Producer p4 = new Producer(storage);Customer c1 = new Customer(storage);Customer c2 = new Customer(storage);Customer c3 = new Customer(storage);p1.setNum(10);p2.setNum(20);p3.setNum(80);c1.setNum(50);c2.setNum(20);c3.setNum(20);c1.start();c2.start();c3.start();p1.start();p2.start();p3.start();}}
▐Handwriting blocking queue
public class blockQueue {private List<Integer> container = new ArrayList<>();private volatile int size;private volatile int capacity;private Lock lock = new ReentrantLock();private final Condition isNull = lock.newCondition();private final Condition isFull = lock.newCondition();blockQueue(int capacity) {this.capacity = capacity;}public void add(int data) {try {lock.lock();try {while (size >= capacity) {System.out.println("阻塞队列满了");isFull.await();}} catch (Exception e) {isFull.signal();e.printStackTrace();}++size;container.add(data);isNull.signal();} finally {lock.unlock();}}public int take() {try {lock.lock();try {while (size == 0) {System.out.println("阻塞队列空了");isNull.await();}} catch (Exception e) {isNull.signal();e.printStackTrace();}--size;int res = container.get(0);container.remove(0);isFull.signal();return res;} finally {lock.unlock();}}}public static void main(String[] args) {AxinBlockQueue queue = new AxinBlockQueue(5);Thread t1 = new Thread(() -> {for (int i = 0; i < 100; i++) {queue.add(i);System.out.println("塞入" + i);try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}}});Thread t2 = new Thread(() -> {for (; ; ) {System.out.println("消费"+queue.take());try {Thread.sleep(800);} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();t2.start();}
▐Handwritten multi-threaded alternate printing ABC
package com.demo.test;import java.util.concurrent.locks.Condition;import java.util.concurrent.locks.ReentrantLock;public class syncPrinter implements Runnable{// 打印次数private static final int PRINT_COUNT = 10;private final ReentrantLock reentrantLock;private final Condition thisCondtion;private final Condition nextCondtion;private final char printChar;public syncPrinter(ReentrantLock reentrantLock, Condition thisCondtion, Condition nextCondition, char printChar) {this.reentrantLock = reentrantLock;this.nextCondtion = nextCondition;this.thisCondtion = thisCondtion;this.printChar = printChar;}@Overridepublic void run() {// 获取打印锁 进入临界区reentrantLock.lock();try {// 连续打印PRINT_COUNT次for (int i = 0; i < PRINT_COUNT; i++) {//打印字符System.out.print(printChar);// 使用nextCondition唤醒下一个线程// 因为只有一个线程在等待,所以signal或者signalAll都可以nextCondtion.signal();// 不是最后一次则通过thisCondtion等待被唤醒// 必须要加判断,不然虽然能够打印10次,但10次后就会直接死锁if (i < PRINT_COUNT - 1) {try {// 本线程让出锁并等待唤醒thisCondtion.await();} catch (InterruptedException e) {e.printStackTrace();}}}} finally {reentrantLock.unlock();}}public static void main(String[] args) throws InterruptedException {ReentrantLock lock = new ReentrantLock();Condition conditionA = lock.newCondition();Condition conditionB = lock.newCondition();Condition conditionC = lock.newCondition();Thread printA = new Thread(new syncPrinter(lock, conditionA, conditionB,'A'));Thread printB = new Thread(new syncPrinter(lock, conditionB, conditionC,'B'));Thread printC = new Thread(new syncPrinter(lock, conditionC, conditionA,'C'));printA.start();Thread.sleep(100);printB.start();Thread.sleep(100);printC.start();}}
▐Alternately print FooBar
//手太阴肺经 BLOCKING Queuepublic class FooBar {private int n;private BlockingQueue<Integer> bar = new LinkedBlockingQueue<>(1);private BlockingQueue<Integer> foo = new LinkedBlockingQueue<>(1);public FooBar(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {foo.put(i);printFoo.run();bar.put(i);}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {bar.take();printBar.run();foo.take();}}}//手阳明大肠经CyclicBarrier 控制先后class FooBar6 {private int n;public FooBar6(int n) {this.n = n;}CyclicBarrier cb = new CyclicBarrier(2);volatile boolean fin = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {while(!fin);printFoo.run();fin = false;try {cb.await();} catch (BrokenBarrierException e) {}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {try {cb.await();} catch (BrokenBarrierException e) {}printBar.run();fin = true;}}}//手少阴心经 自旋 + 让出CPUclass FooBar5 {private int n;public FooBar5(int n) {this.n = n;}volatile boolean permitFoo = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; ) {if(permitFoo) {printFoo.run();i++;permitFoo = false;}else{Thread.yield();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; ) {if(!permitFoo) {printBar.run();i++;permitFoo = true;}else{Thread.yield();}}}}//手少阳三焦经 可重入锁 + Conditionclass FooBar4 {private int n;public FooBar4(int n) {this.n = n;}Lock lock = new ReentrantLock(true);private final Condition foo = lock.newCondition();volatile boolean flag = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {lock.lock();try {while(!flag) {foo.await();}printFoo.run();flag = false;foo.signal();}finally {lock.unlock();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n;i++) {lock.lock();try {while(flag) {foo.await();}printBar.run();flag = true;foo.signal();}finally {lock.unlock();}}}}//手厥阴心包经 synchronized + 标志位 + 唤醒class FooBar3 {private int n;// 标志位,控制执行顺序,true执行printFoo,false执行printBarprivate volatile boolean type = true;private final Object foo= new Object(); // 锁标志public FooBar3(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {synchronized (foo) {while(!type){foo.wait();}printFoo.run();type = false;foo.notifyAll();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {synchronized (foo) {while(type){foo.wait();}printBar.run();type = true;foo.notifyAll();}}}}//手太阳小肠经 信号量 适合控制顺序class FooBar2 {private int n;private Semaphore foo = new Semaphore(1);private Semaphore bar = new Semaphore(0);public FooBar2(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {foo.acquire();printFoo.run();bar.release();}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {bar.acquire();printBar.run();foo.release();}}}
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。