
Spark is a fast, versatile, and scalable big data computing engine . It has the advantages of high performance, ease of use, fault tolerance, seamless integration with the Hadoop ecosystem, and high community activity. In actual use, it has a wide range of application scenarios:
· Data cleaning and preprocessing: In big data analysis scenarios, data usually needs cleaning and preprocessing operations to ensure data quality and consistency. Spark provides a rich API that can clean, filter, transform and other operations on data.
· Batch processing analysis: Spark is suitable for batch processing tasks in various application scenarios, including statistical analysis, data mining, feature extraction, etc. Users can use Spark's powerful API and built-in libraries to perform complex data processing and analysis to mine data. intrinsic value in
· Interactive query: Spark provides the Spark SQL module that supports SQL query . Users can use standard SQL statements for interactive query and large-scale data analysis.
The use of Spark in Kangaroo Cloud
In the Kangaroo Cloud Stack offline development platform , we provide three ways to use Spark:
● Create Spark SQL tasks
Users can implement their own business logic directly by writing SQL. This method is currently the most widely used way to use Spark on the data stack offline platform, and it is also the most recommended method.
● Create Spark Jar task
Users need to use Scala or Java language to implement business logic on IDEA, then compile and package the project, upload the resulting Jar package to the offline platform, then reference this Jar package when creating a Spark Jar task , and finally submit the task Just go to the scheduled run.
For requirements that are difficult to achieve or express using SQL, or users have other deeper requirements, Spark Jar tasks undoubtedly provide users with a more flexible way to use Spark.
● Create PySpark tasks
Users can directly write corresponding Python code . Among our customer base, there are quite a few customers for whom, in addition to SQL, Python may be their main language. Especially for users with certain data analysis and algorithm foundations, they often conduct deeper analysis of processed data. At this time, PySpark tasks are naturally their best choice.
Spark plays an important role in the Kangaroo Cloud Data Stack offline development platform . Therefore, we have made a lot of internal optimizations to Spark to make it more convenient for customers to submit tasks using Spark. We have also made some tools based on Spark to enhance the functionality of the entire data stack offline development platform.
In addition, Spark also plays a very important role in the data lake scenario. Kangaroo Cloud's integrated lake and warehouse module already supports two major data lakes, Iceberg and Hudi. Users can use Spark to read and write lake tables. The bottom layer of lake table management is also implemented by using Spark to call different stored procedures.
The following will explain the optimization made inside Kangaroo Cloud from both the engine side and Spark itself.
Engine side optimization
The functions of the internal engine of Kangaroo Cloud are mainly used for task submission, task status acquisition, task log acquisition, stopping tasks, syntax verification, etc. We have optimized each function point to varying degrees. The following is a brief introduction through two examples.
Spark on Yarn submission speed improved
With the continuous development and improvement of new functions on the engine-side Spark plug-in, the time required for the engine-side to submit Spark tasks is also increasing accordingly. Therefore, the code related to submitting Spark tasks needs to be optimized to shorten the time for Spark task submission. Improve user experience.
To this end, we have done the following work. For some common configuration files, such as core-site.xml, yarn-site.xml, keytab file, spark-sql-application.jar, etc., it turns out that each time you submit a task, you need to download it from The server downloads and submits these configuration files. Now after optimization, the above file only needs to be downloaded once when the client SparkYarnClient is initialized, and then uploaded to the specified HDFS path. Subsequent submission of Spark tasks only needs to be specified to the corresponding HDFS path through parameters. In this way, the submission time of each Spark task is greatly shortened.
In the new version of the data stack, for temporary queries , we will also judge the complexity of the SQL to be executed based on custom rules, and send the less complex SQL to the SparkSQLEngine started on the engine side to speed up the operation. This internal SparkSQLEngine was only used for syntax verification in the past, but now it also assumes part of the SQL execution function, and SparkSQLEngine can also dynamically expand and contract resources according to the overall running situation to achieve effective utilization of resources.
Grammar check
In older data stack versions, for syntax verification of SQL, the engine will first send the SQL to Spark Thrift Server. This Spark Thrift Server is deployed in local mode and is not only used for syntax verification. All metadata on other platforms is obtained by sending SQL to this Spark Thrift Server for execution. This method has major disadvantages, so we have made some optimizations. A Spark task is started in local mode on the Engine side . When performing syntax verification, the SQL is no longer sent to the Spark Thrift Server. Instead, a SparkSession is maintained internally to directly perform syntax verification on the SQL.
Although this method does not require a strong connection with the external Spark Thrift server, it will put a certain amount of pressure on the scheduling component, and the overall complexity of Engine-Plugins will also increase a lot during the implementation process.
In order to optimize the above problems, we have made further optimization. When the scheduling component is started, it submits a Spark task SparkSQLEngine to Yarn. It can be understood as a remote Spark Thrift Server running on Yarn. The engine side monitors the health status of the SparkSQLEngine at all times . In this way, every time syntax verification is performed, the engine sends SQL to SparkSQLEngine through JDBC for syntax verification.
Through the above optimization, the offline development platform is decoupled from the Spark Thrift Server. EasyManager does not need to deploy additional Spark Thrift Server, making the deployment more lightweight. There is no need to maintain a local mode Spark resident process on the scheduling side. It also paves the way for interactive query enhancement of Spark SQL tasks on the offline development platform.
Decoupling the offline development platform from the Spark Thrift Server deployed by EasyManager will have the following benefits:
· Able to truly realize the coexistence of multiple Spark clusters and multiple versions
· EasyManager standard deployment can remove Spark Thrift Server and reduce the burden on front-line operation and maintenance
· Spark SQL syntax verification becomes more lightweight, no need to cache SparkContext, reducing Engine resource usage
Spark function optimization
As the business develops, we find that the open source Spark does not have corresponding functional implementations in some scenarios. Therefore, we have developed more new plug-ins based on the open source Spark to support more functional applications of the data stack.
Mission diagnostics
First, we enhanced Spark's metric sink. Spark provides various sinks internally. In addition to ConsoleSink, there are also CSVSink, JmxSink, MetricsServlet, GraphiteSink, Slf4jSink, StatsdSink, etc. PrometheusServlet was also added after Spark3.0, but these cannot meet our needs.
When developing the task diagnosis function , we need to push the internal indicators of Spark to PushGateway in a unified manner, and the Prometheus Server periodically pulls the indicators from PushGateway. Finally, by calling the query interface provided by Prometheus, we can query the internal indicators of Spark in near real-time. index of.

But Spark does not implement sinking internal indicators to PushGateway. Therefore, we added the spark-prometheus-sink plug-in and customized the PrometheusPushGatewaySink to push Spark internal indicators to PushGateway.
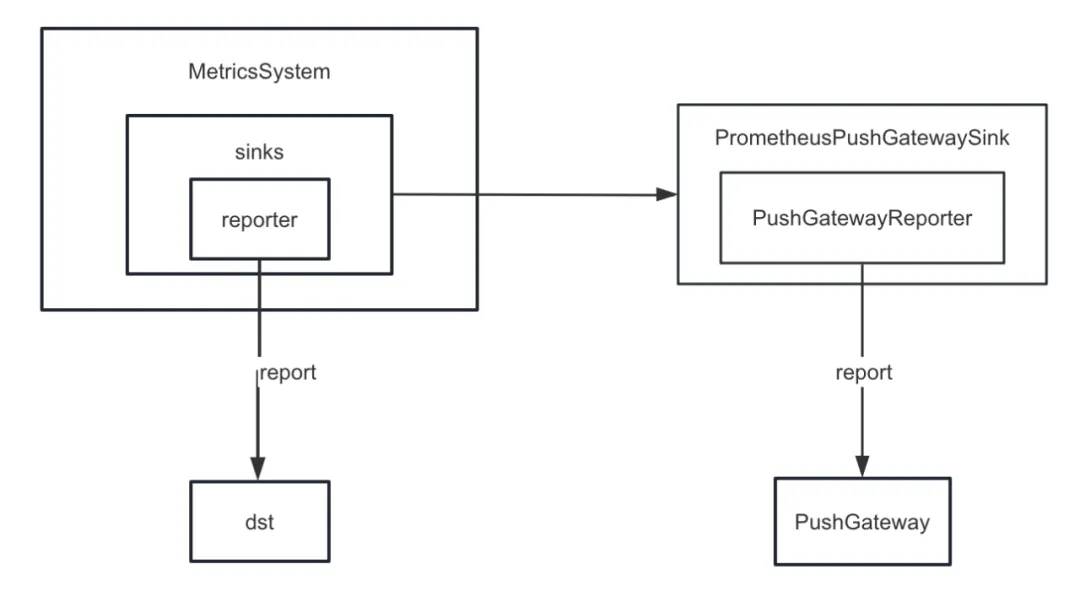
In addition, we also customized a new indicator to describe the Spark SQL temporary query display task execution progress. Specific steps are as follows:
· Add an indicator to describe the progress of offline tasks by customizing JobProgressSource , and register the indicator into the indicator management system in Spark's internal management system
· Customize the JobProgressListener and register the JobProgressListener to the ListenerBus in the Spark internal management system. Among them, the logic of the onJobStart method of JobProgressListener is to calculate the number of all Tasks under the current Job; the logic of the onTaskEnd method is to calculate and update the current offline task progress after each Task is completed; the logic of the onJobEnd method is to calculate and update the current offline task progress after each Job is completed. Update current offline task progress
Connecting to the commercial version of Hadoop cluster
As the number of Kangaroo Cloud customers increases, their environments also vary. Some customers use the open source version of Hadoop clusters, and a considerable number of customers use HDP, CDH, CDP, TDH, etc. When we connect to the clusters of these customers, the development side often needs to make new adaptations, and the operation and maintenance side also needs to configure additional parameters or perform other additional operations every time it is deployed and upgraded.
Taking HDP as an example, when connecting to HDP, the Spark we use is Spark2.3 that comes with HDP, and we also need to add some parameters on the operation and maintenance side and move all the Jar packages of Spark that comes with HDP to Specify directory. These operations will actually bring some confusion and trouble to operation and maintenance. Different types of clusters need to maintain different operation and maintenance documents, and the deployment process is also more error-prone. And we have actually made functional enhancements and bug fixes to the Spark source code. If you use the Spark that comes with HDP, you will not be able to enjoy all the benefits of our internally maintained Spark.
In order to solve the above problems, our internal Spark has been adapted to existing and common publishers in the existing market. In other words, our internal Spark can run on all different Hadoop clusters. In this way, no matter which type of Hadoop cluster is connected, operation and maintenance only need to deploy the same Spark, which greatly reduces the pressure of operation and maintenance deployment. More importantly, customers can directly use our internal Spark stable version to enjoy more new features and greater performance improvements.
Spark3.2 new features-AQE
In older Data Stack versions, the default Spark version is 2.1.3. Later we upgraded the Spark version to 2.4.8. Starting from Data Stack 6.0, Spark 3.2 can also be used. Here we focus on AQE , which is also the most important new feature in Spark3.x.
AQE Overview
Before Spark3.2, AQE was turned off by default. You need to set spark.sql.adaptive.enabled to true to enable AQE. After Spark3.2, AQE is enabled by default. As long as the task meets the trigger conditions of AQE during operation, you can enjoy the optimization brought by AQE.
It should be noted that the optimization of AQE will only occur in the shuffle phase. If the shuffle operation is not involved in the running process of SQL, AQE will not play a role even if the value of spark.sql.adaptive.enabled is true. More precisely, AQE will take effect only if the physical execution plan contains an exchange node or contains a subquery.
During operation, AQE collects the information of the intermediate files generated in the shuffle map stage, collects statistics on this information, and dynamically adjusts the Optimized Logical Plan and Spark Plan that have not yet been executed based on the existing rules, thereby modifying the original SQL statement. Runtime optimization.
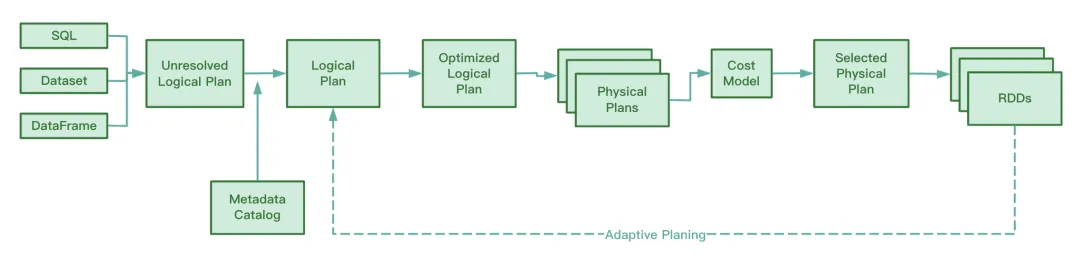
Judging from the Spark source code, AQE involves the following four optimization rules:

We know that RBO optimizes SQL based on a series of rules, including predicate pushdown, column pruning, constant replacement, etc. These static rules themselves have been built into Spark. When Spark executes SQL, these rules will be applied to the SQL one by one.
AQE Advantages
This feature of CBO is only available after Spark2.2. Compared with RBO, CBO will combine the statistical information of the table and select a more optimized execution plan based on these statistical information and the cost model.
However, CBO only supports tables registered to the Hive Metastore. CBO does not support files such as parquet and orc stored in distributed file systems. Moreover, if the Hive table lacks metadata information, CBO will not be able to collect statistics when collecting statistics, which may cause CBO to fail.
Another disadvantage of CBO is that CBO needs to execute ANALYZE TABLE COMPUTE STATISTICS to collect statistical information before optimization. If this statement encounters a large table during execution, it will be more time-consuming and the collection efficiency will be low.
Whether it is CBO or RBO, they are static optimizations. After the physical execution plan is submitted, if the data volume and data distribution change while the task is running, CBO will not optimize the existing physical execution plan.
Different from CBO and RBO, during the running process, AQE will analyze the intermediate files generated during the shuffle map process, and dynamically adjust and optimize the logical execution plan and physical execution plan that have not yet started execution. Compared with the statically optimized CBO, Compared with RBO, AQE processing can obtain a more optimized physical execution plan .
AQE three major features
● Automatic partition merging
The Shuffle process is divided into two stages: Map stage and Reduce stage. The Reduce stage will pull the intermediate temporary files generated in the Map stage to the corresponding Executor. If the data processed by the Map stage is very unevenly distributed, there are many keys. In fact, there are only a few keys. piece of data, the data may form a large number of small files after processing.
In order to avoid the above situation, you can enable AQE's automatic partition merging function to avoid starting too many reduce tasks to pull the small files generated in the Map stage.
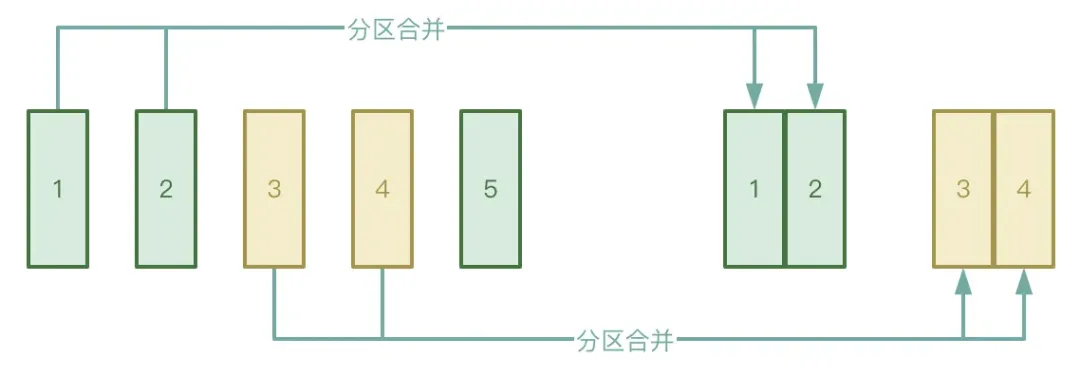
● Automatic data skew processing
The application scenario is mainly in Data Joins. When data skew occurs, AQE can automatically detect the skewed partition and split the skewed partition according to certain rules. Currently, in Spark3.2, automatic data skew processing is supported for both SortMergeJoin and ShuffleHashJoin.
● Join strategy adjustment
AQE will dynamically downgrade Hash Join and Sort Merge Join to Broadcast Join.
We know that once a Spark task starts executing, the degree of parallelism is determined. For example, in the shuffle map stage , the parallelism is the number of partitions; in the shuffle reduce stage, the parallelism is the value of spark.sql.shuffle.partitions, which defaults to 200. If the amount of data becomes smaller during the running of the Spark task, causing the size of most partitions to become smaller, it will lead to a waste of resources if so many threads are still started to process the small data set.
During the execution process, AQE will automatically merge partitions based on the intermediate temporary results generated after shuffle, and under certain conditions, by applying CoalesceShufflePartitions rules and combining the parameters provided by the user, which is actually adjusting the number of reducers. Originally, a reduce thread would only pull the data of one processed partition. Now, a reduce thread will pull the data of more partitions according to the actual situation, which can reduce the waste of resources and improve the efficiency of task execution. "Industry Indicator System White Paper" download address: https://www.dtstack.com/resources/1057?src=szsm
"Dutstack Product White Paper" download address: https://www.dtstack.com/resources/1004?src=szsm
"Data Governance Industry Practice White Paper" download address: https://www.dtstack.com/resources/1001?src=szsm
For those who want to know or consult more about big data products, industry solutions, and customer cases, visit the Kangaroo Cloud official website: https://www.dtstack.com/?src=szkyzg
I decided to give up on open source Hongmeng. Wang Chenglu, the father of open source Hongmeng: Open source Hongmeng is the only architectural innovation industrial software event in the field of basic software in China - OGG 1.0 is released, Huawei contributes all source code Google Reader is killed by the "code shit mountain" Fedora Linux 40 is officially released Former Microsoft developer: Windows 11 performance is "ridiculously bad" Ma Huateng and Zhou Hongyi shake hands to "eliminate grudges" Well-known game companies have issued new regulations: employee wedding gifts must not exceed 100,000 yuan Ubuntu 24.04 LTS officially released Pinduoduo was sentenced for unfair competition Compensation of 5 million yuan