

This article introduces the support of the Databend open tabular format engine, including advantages and disadvantages, usage methods, and comparison with the Catalog solution. In addition, a simple Workshop is included to introduce how to use Databend Cloud to analyze the Delta Table located in object storage.
Databend recently released two table engines, Apache Iceberg and Delta Table, to provide support for the two most popular open table formats to meet the advanced analysis needs of modern data lake solutions based on different technology stacks.
Using a one-stop solution based on Databend/Databend Cloud, you can gain insights into open tabular data and simplify the deployment architecture and analysis process without activating additional Spark/Databricks services. In addition, using Databend / Databend Cloud's data access solution built on Apache OpenDAL™, you can easily access dozens of storage services, including object storage, HDFS and even IPFS, and can be easily integrated with existing technology stacks.
Advantage
-
When using the open table format engine, you only need to specify the type (
DeltaorIceberg) of the table engine and the location where the data file is stored, and you can directly access the corresponding table and use Databend to query. -
Using Databend's open tabular format engine, you can easily handle scenarios where you mix different data sources and data in different tabular formats:
- Under the same database object, query and analyze data tables summarized in different formats.
- With Databend's rich storage backend integration, you can handle data access needs in different storage backends.
insufficient
- Currently, the Apache Iceberg and Delta Lake engines only support read-only operations, that is, they can only query data but cannot write data to the table.
- The Schema of the table is determined when the table is created. If the Schema of the original table is modified, in order to ensure data consistency and synchronization, the table needs to be re-created in Databend.
Instructions
-- Set up connection
CREATE [ OR REPLACE ] CONNECTION [ IF NOT EXISTS ] <connection_name>
STORAGE_TYPE = '<type>'
[ <storage_params> ]
-- Create table with Open Table Format engine
CREATE TABLE <table_name>
ENGINE = [Delta | Iceberg]
LOCATION = '<location_to_table>'
CONNECTION_NAME = '<connection_name>'
Tip: Use in Databend
CONNECTIONto manage the details needed to interact with external storage services, such as access credentials, endpoint URLs, and storage types. By specifyingCONNECTION_NAME, you can reuse it when creating resourcesCONNECTION, simplifying the management and use of storage configurations.
Comparison with Catalog solution
Databend has previously provided support for Iceberg and Hive through Catalog. Compared with table engines, Catalog is more suitable for complete docking related ecology and mounting multiple databases and tables at one time.
The new open table format engine is more flexible in terms of experience, supporting the aggregation and mixing of data from different data sources and different table formats under the same database, and conducting effective analysis and insights.
Workshop: Use Databend Cloud to analyze data in Delta Table
This example will show how to use Databend Cloud to load and analyze a Delta Table located in object storage.
We will use the classic penguin body feature data set (penguins), convert it into a Delta Table and place it in an S3-compatible object storage. This data set contains a total of 8 variables, including 7 feature variables and 1 categorical variable, with a total of 344 samples.
- The categorical variables are penguin species (species), which belong to three subgenus of the genus Hard-tailed Penguin , namely Adélie, Chinstrap and Gentoo.
- The six characteristics of the three penguins included are the island (island), bill length (bill_length_mm), bill depth (bill_depth_mm), flipper length (flipper_length_mm), body weight (body_mass_g), and gender (sex).
If you don’t have a Databend Cloud account yet, please visit https://app.databend.cn/register to register and get free quota. Or you can refer to https://docs.databend.com/guides/deploy/ to deploy Databend locally.
This article also covers the use of object storage, and you can also try to create a Bucket using Cloudflare R2 with free quota.
Write data to object storage
We need to install the corresponding Python package, seabornwhich is responsible for providing raw data, deltalakeconverting the data into a Delta Table and writing it to S3:
pip install deltalake seaborn
Then, edit the code below, configure the corresponding access credentials, and save it as writedata.py:
import seaborn as sns
from deltalake.writer import write_deltalake
ACCESS_KEY_ID = '<your-key-id>'
SECRET_ACCESS_KEY = '<your-access-key>'
ENDPOINT_URL = '<your-endpoint-url>'
storage_options = {
"AWS_ACCESS_KEY_ID": ACCESS_KEY_ID,
"AWS_SECRET_ACCESS_KEY": SECRET_ACCESS_KEY,
"AWS_ENDPOINT_URL": ENDPOINT_URL,
"AWS_S3_ALLOW_UNSAFE_RENAME": 'true',
}
penguins = sns.load_dataset('penguins')
write_deltalake("s3://penguins/", penguins, storage_options=storage_options)
Execute the above Python script to write data to object storage:
python writedata.py
Access data using the Delta table engine
Create corresponding access credentials in Databend:
--Set up connection
CREATE CONNECTION my_r2_conn
STORAGE_TYPE = 's3'
SECRET_ACCESS_KEY = '<your-access-key>'
ACCESS_KEY_ID = '<your-key-id>'
ENDPOINT_URL = '<your-endpoint-url>';
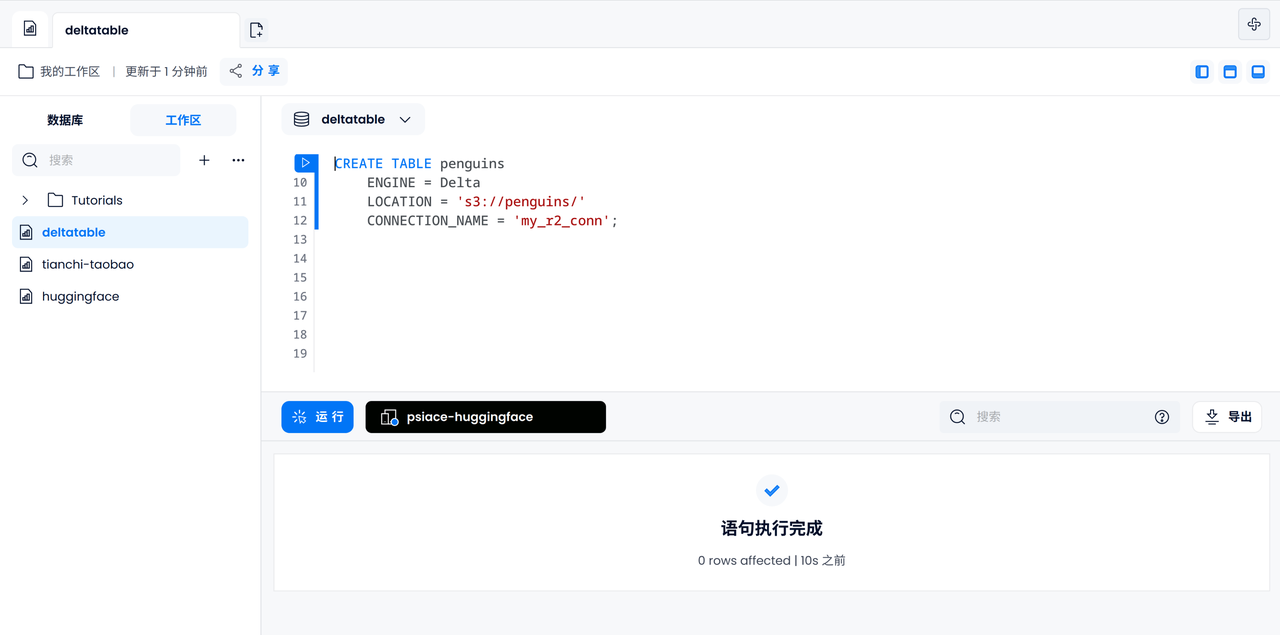
Create a data table powered by the Delta table engine:
-- Create table with Open Table Format engine
CREATE TABLE penguins
ENGINE = Delta
LOCATION = 's3://penguins/'
CONNECTION_NAME = 'my_r2_conn';
Use SQL to query and analyze data in tables
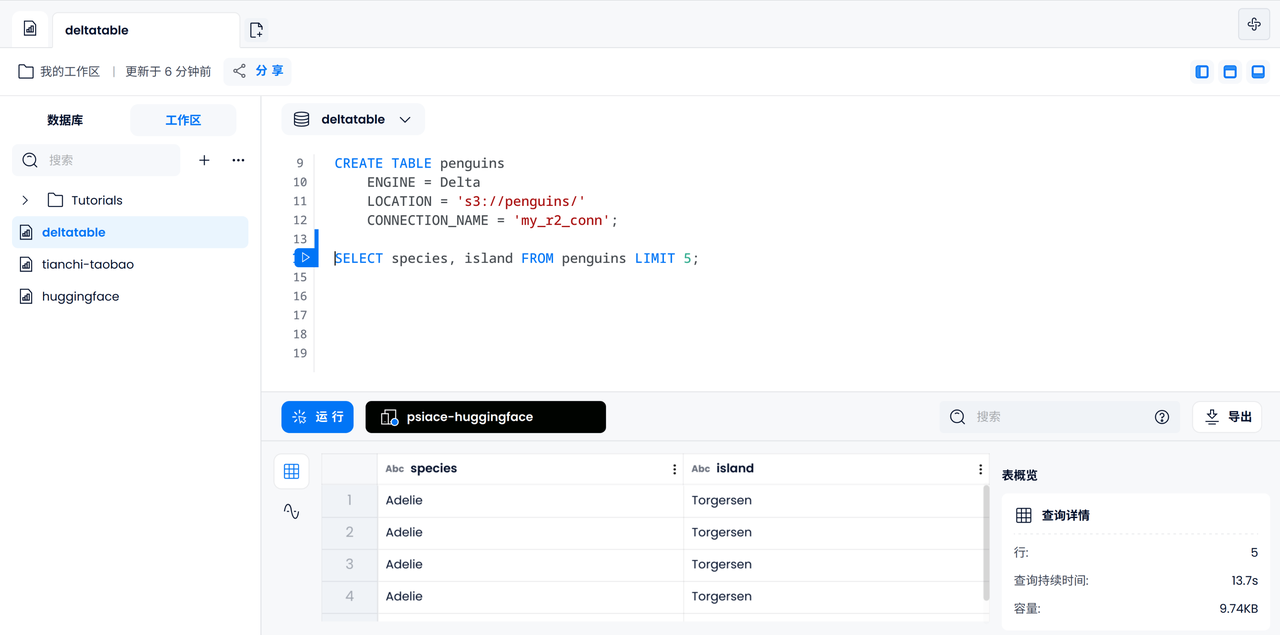
Verify data accessibility
First, let us output the species and islands of the 5 penguins to check whether the data in the Delta Table can be accessed correctly.
SELECT species, island FROM penguins LIMIT 5;
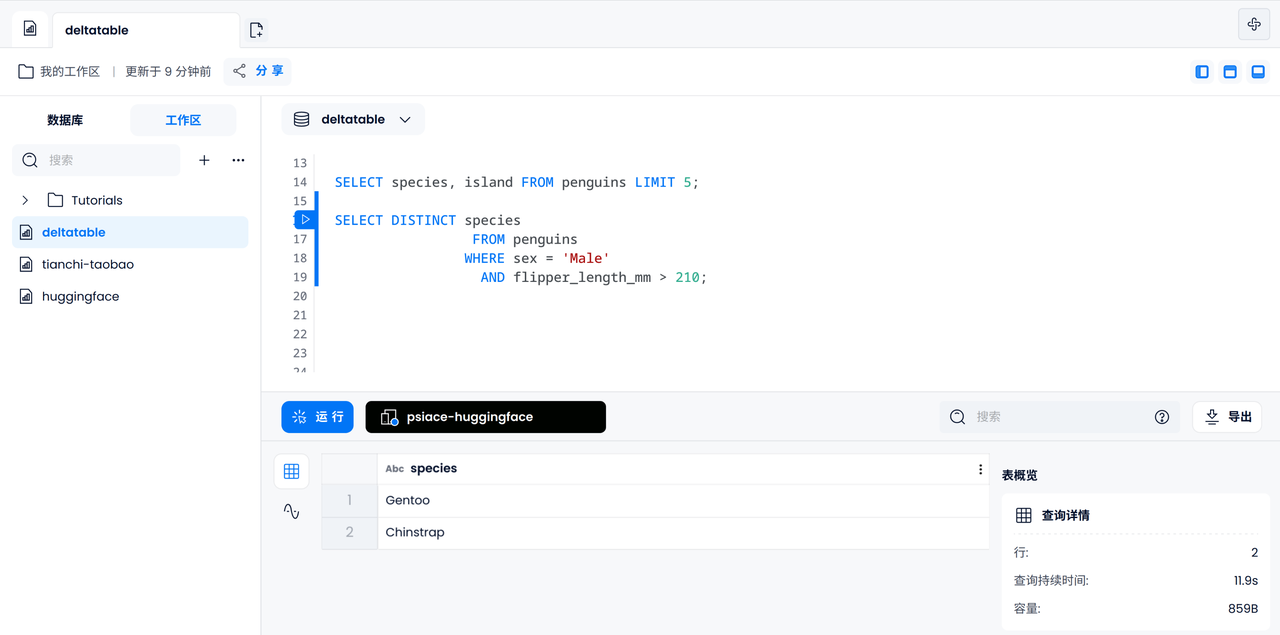
Data filtering
Next, you can perform some basic data filtering operations, such as finding out which subgenus male penguins with flipper lengths exceeding 210mm may belong to.
SELECT DISTINCT species
FROM penguins
WHERE sex = 'Male'
AND flipper_length_mm > 210;
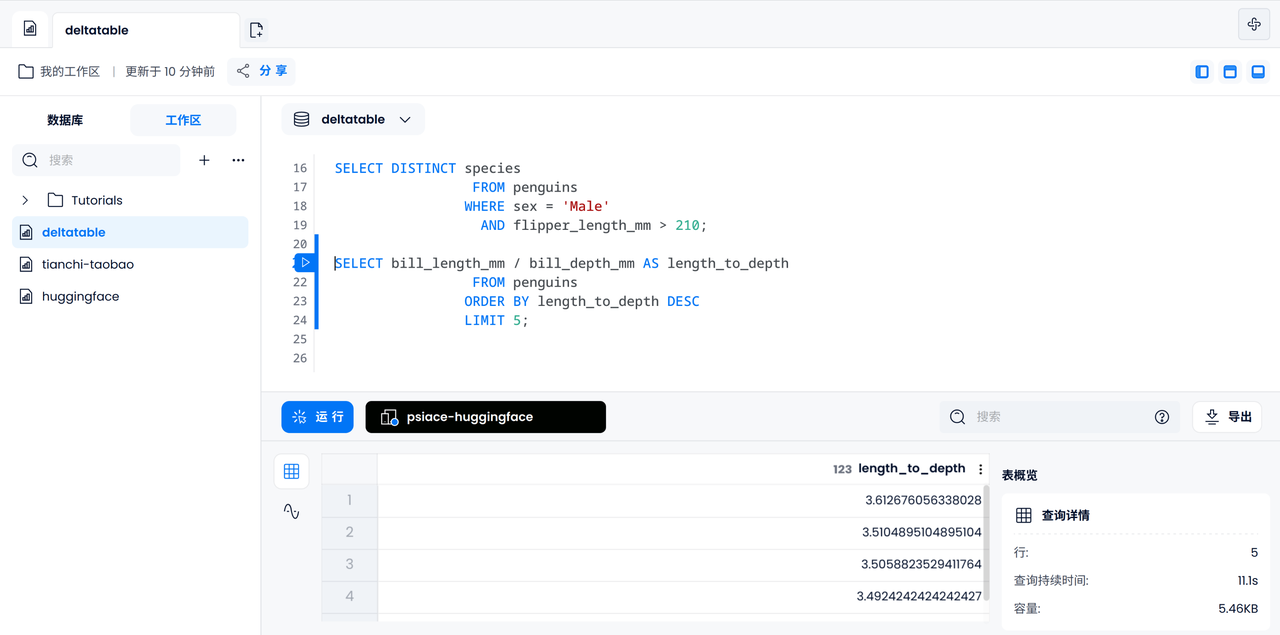
data analysis
Similarly, we could try to calculate the ratio of bill length and depth for each penguin and output the five largest ones.
SELECT bill_length_mm / bill_depth_mm AS length_to_depth
FROM penguins
ORDER BY length_to_depth DESC
LIMIT 5;
Mixed data source case: Penguin observation log
Now we will enter an interesting part: Suppose we find an observation record from a scientific research station, let us try to enter this data under the same database, and try to conduct a simple data analysis: a bird of a specific gender What is the probability that a penguin is tagged by a scientist.
Create observation log table
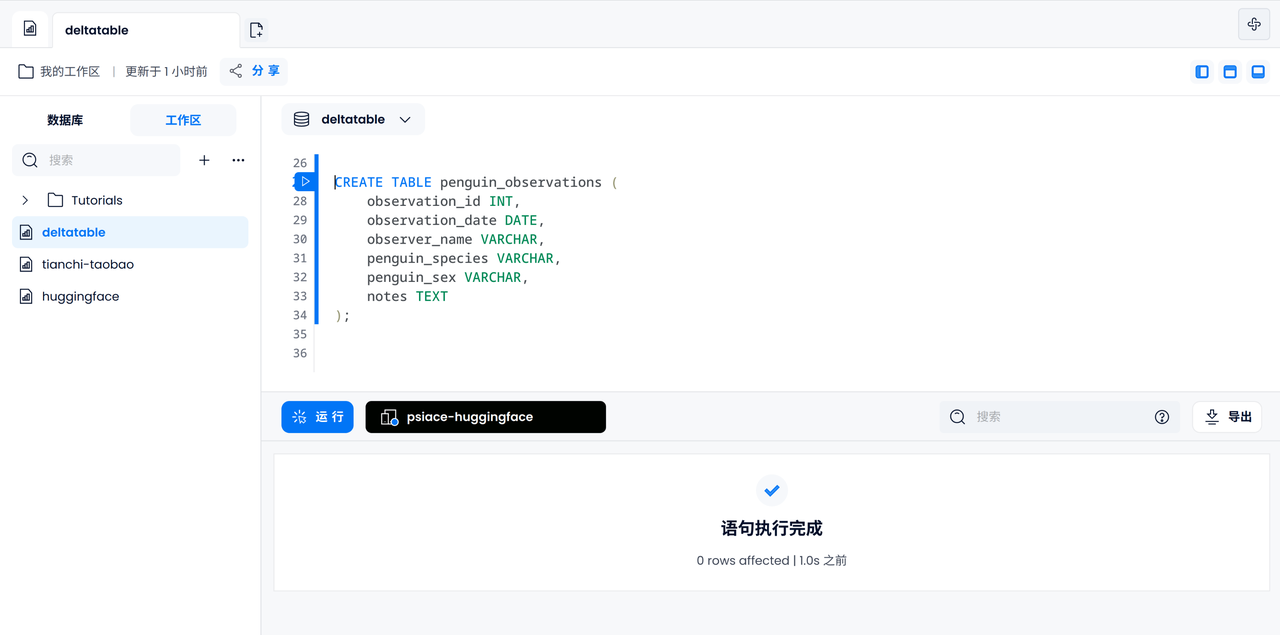
Use the default FUSE engine to create penguin_observationsa table, including ID, date, name, penguin species and gender, remarks and other information.
CREATE TABLE penguin_observations (
observation_id INT,
observation_date DATE,
observer_name VARCHAR,
penguin_species VARCHAR,
penguin_sex VARCHAR,
notes TEXT,
);
Enter observation log
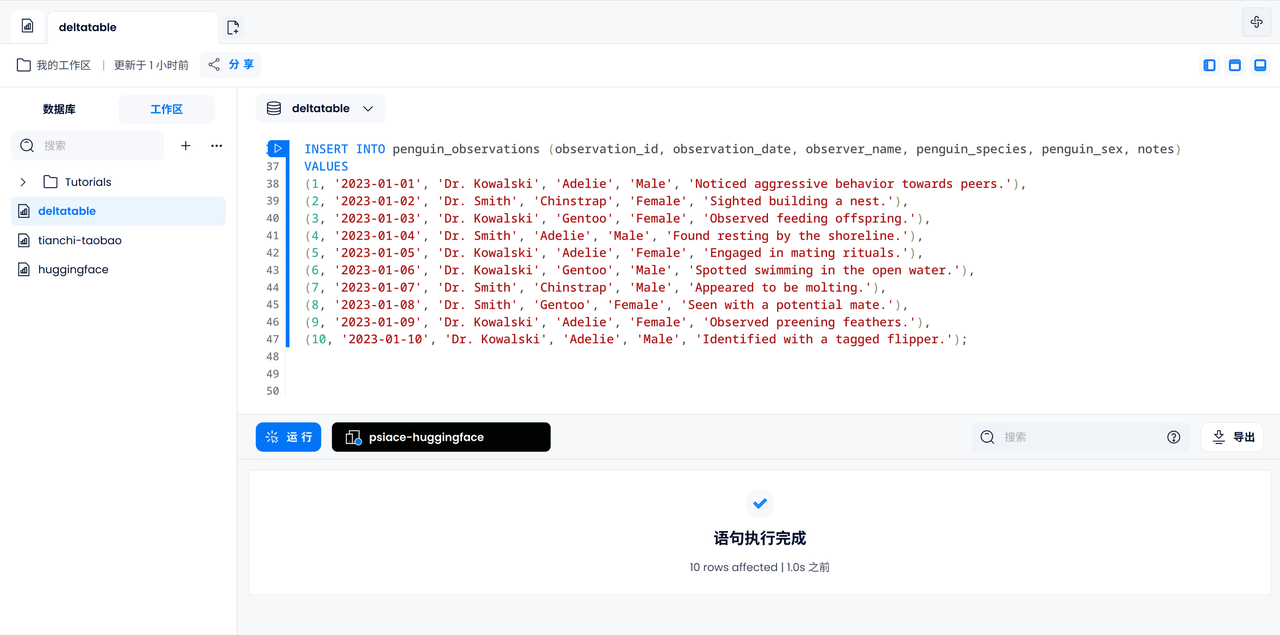
Let's try to enter all 10 logs manually. Penguins appearing in log records are known to be different from each other.
INSERT INTO penguin_observations (observation_id, observation_date, observer_name, penguin_species, penguin_sex, notes)
VALUES
(1, '2023-01-01', 'Dr. Kowalski', 'Adelie', 'Male', 'Noticed aggressive behavior towards peers.'),
(2, '2023-01-02', 'Dr. Smith', 'Chinstrap', 'Female', 'Sighted building a nest.'),
(3, '2023-01-03', 'Dr. Kowalski', 'Gentoo', 'Female', 'Observed feeding offspring.'),
(4, '2023-01-04', 'Dr. Smith', 'Adelie', 'Male', 'Found resting by the shoreline.'),
(5, '2023-01-05', 'Dr. Kowalski', 'Adelie', 'Female', 'Engaged in mating rituals.'),
(6, '2023-01-06', 'Dr. Kowalski', 'Gentoo', 'Male', 'Spotted swimming in the open water.'),
(7, '2023-01-07', 'Dr. Smith', 'Chinstrap', 'Male', 'Appeared to be molting.'),
(8, '2023-01-08', 'Dr. Smith', 'Gentoo', 'Female', 'Seen with a potential mate.'),
(9, '2023-01-09', 'Dr. Kowalski', 'Adelie', 'Female', 'Observed preening feathers.'),
(10, '2023-01-10', 'Dr. Kowalski', 'Adelie', 'Male', 'Identified with a tagged flipper.');
Calculate marking probability
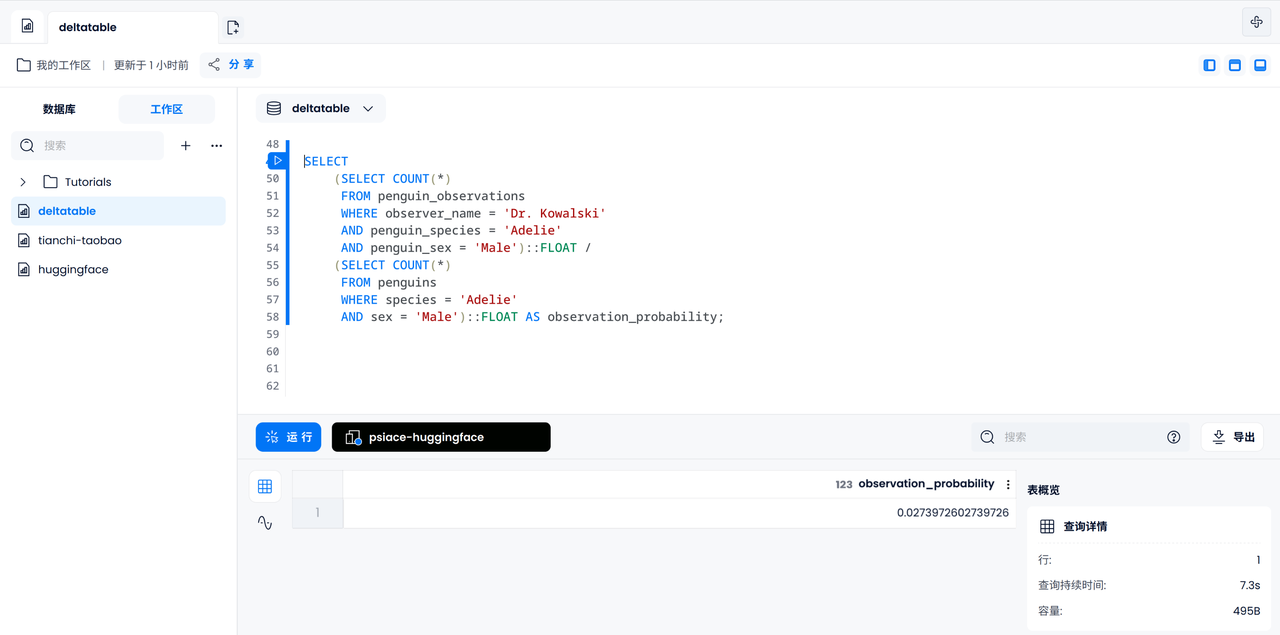
Now let us calculate the probability that a certain male Adelie penguin is observed by Dr. Kowalski among all penguins. First we need to count the number of male Adelie penguins observed by Dr. Kowalski, then count the number of all recorded male Adelie penguins, and finally divide to get the result.
SELECT
(SELECT COUNT(*)
FROM penguin_observations
WHERE observer_name = 'Dr. Kowalski'
AND species = 'Adelie'
AND sex = 'Male')::FLOAT /
(SELECT COUNT(*)
FROM penguins
WHERE species = 'Adelie'
AND sex = 'Male')::FLOAT AS observation_probability;
Summarize
By combining different table engines for query, Databend / Databend Cloud can support mixing tables of different formats under the same database for analysis and query. This article only provides a basic Workshop for everyone to experience the functions and use. You are welcome to expand based on this case and explore more scenarios of combining Iceberg and Delta Table for data analysis, as well as more potential real-world applications.