
At the just past 2024 spring conference, Kangaroo Cloud brought a new release of the V6.2 version of the data stack product . Among them, EasyMR, as a key capability in the data stack V6.2, represents Kangaroo Cloud’s in-depth understanding and continuous innovation of the big data ecosystem.
EasyMR (hereinafter collectively referred to as EMR) is an elastic computing engine built by Kangaroo Cloud based on open source components such as Hadoop, Hive, Spark, Flink, and HBase. It provides safe, reliable, elastically scalable, and low-cost big data storage and computing services . Among them, the independently developed EasyManager enterprise-level big data operation and maintenance management platform supports the one-stop creation, management, deployment, operation and maintenance and monitoring functions of Hadoop clusters, providing an efficient data center solution.
Facing the growing data processing and analysis needs of enterprises, EMR6.2 version will provide users with better big data operation and maintenance services and computing performance optimization. The following is a detailed introduction to the optimization of the four major functions of the EMR6.2 version to help users fully understand this innovative product.
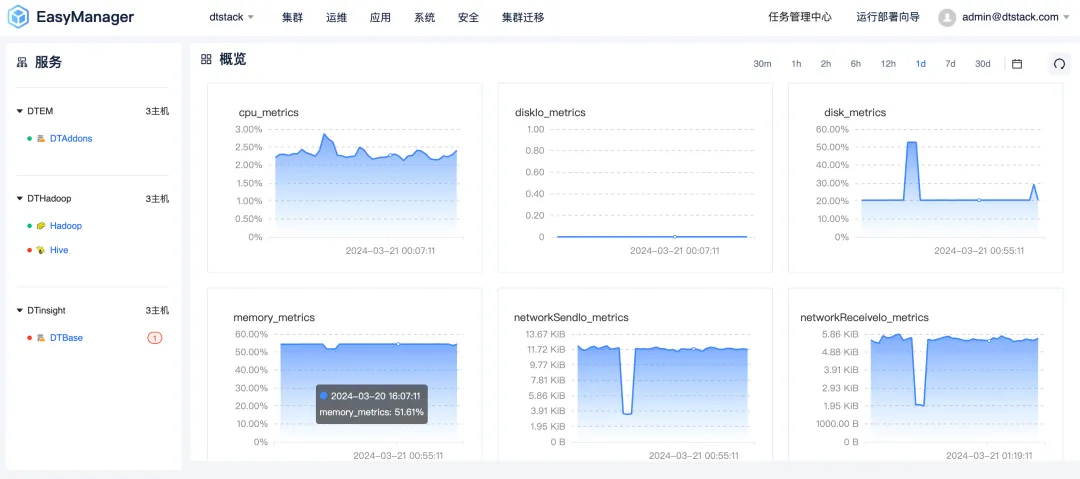
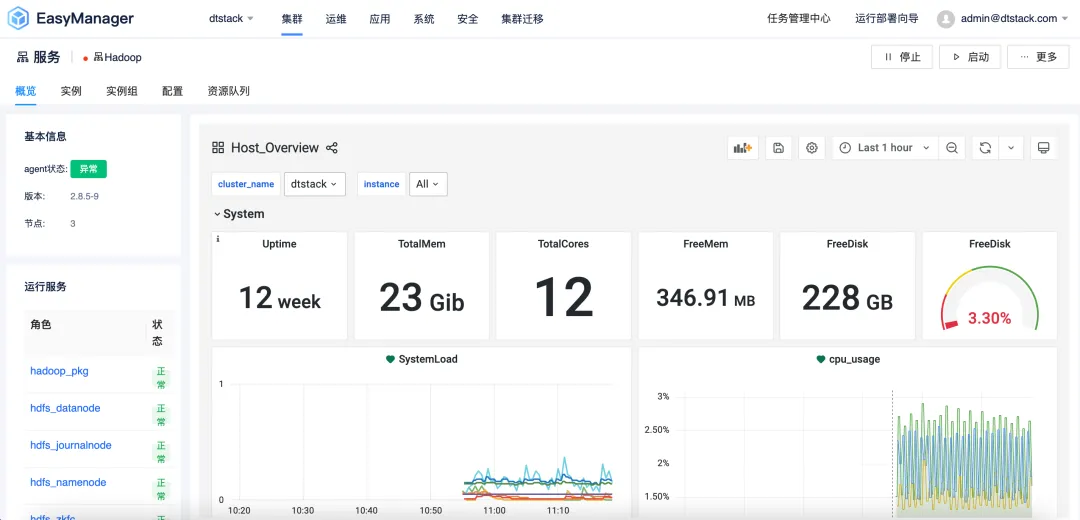
UI completely refreshed and upgraded: simple and comfortable interactive experience
Kangaroo Cloud understands the importance of user experience, so in the EMR6.2 version, we have comprehensively refreshed and upgraded the UI interface. The new interface design follows a simple yet elegant style, aiming to provide users with an intuitive and comfortable interactive experience. Whether you are a novice or an experienced user, you can quickly get started and easily manage complex big data clusters.
In addition, we have also optimized the response speed and operation fluency of the interface to ensure that users can enjoy a smoother operating experience during cluster operation and maintenance .
Differentiated configuration: meet diverse needs
EMR6.2 version introduces the instance group-differentiated configuration function , allowing users to customize the cluster configuration according to their specific needs. Users can build independent instance groups from different nodes in the EMR cluster , and set specific configuration parameters in the instance group to achieve better performance, resource utilization and task scheduling.
Whether it is a cost-sensitive start-up or a large enterprise with higher performance requirements, EMR6.2 can provide flexible configuration options to meet the needs of different users.
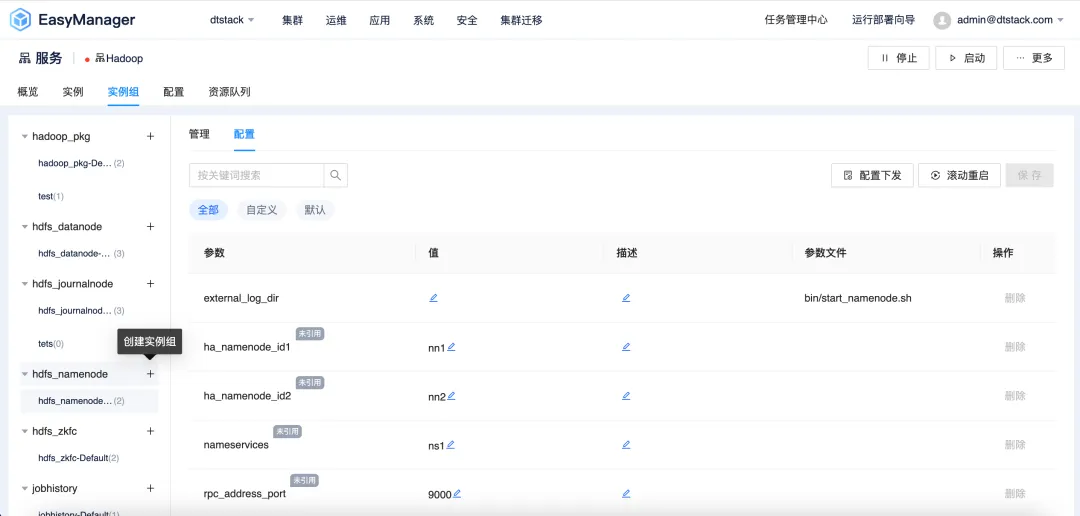
The specific advantages of implementing differentiated configuration strategies for instance groups include but are not limited to the following:
● Resource allocation
Differentiated configuration can effectively implement refined resource allocation according to the unique needs of various tasks, covering multiple levels such as computing, storage and network resources. Avoid resource waste and improve resource utilization to ensure that all tasks in the cluster are supported by appropriate resources.
●Task scheduling optimization
For different types of tasks or jobs, different configuration parameters can be set according to their characteristics to optimize task scheduling and execution efficiency.
● Fault tolerance and stability
Through differentiated configuration, the fault tolerance and stability of the cluster can be improved. Depending on the importance and load of the node or instance group, different fault tolerance mechanisms and fault handling strategies can be set to ensure that the cluster can maintain stable operation in the face of abnormal situations.
● Cost management
Differentiated configuration can also help manage costs. According to business needs and budget constraints, different instance groups in the cluster can be reasonably configured to avoid resource waste, reduce operation and maintenance costs, and find a balance between performance and cost.
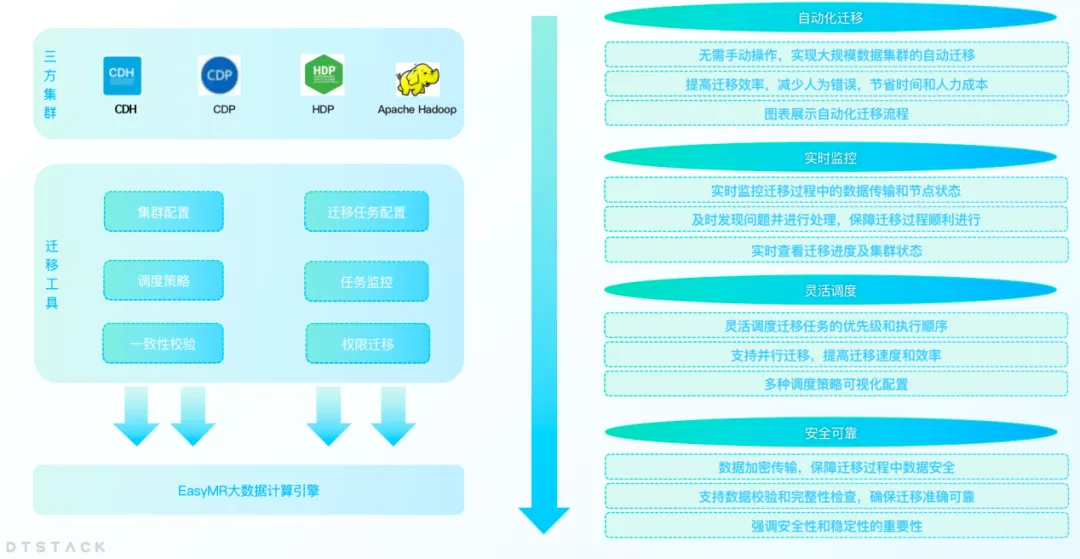
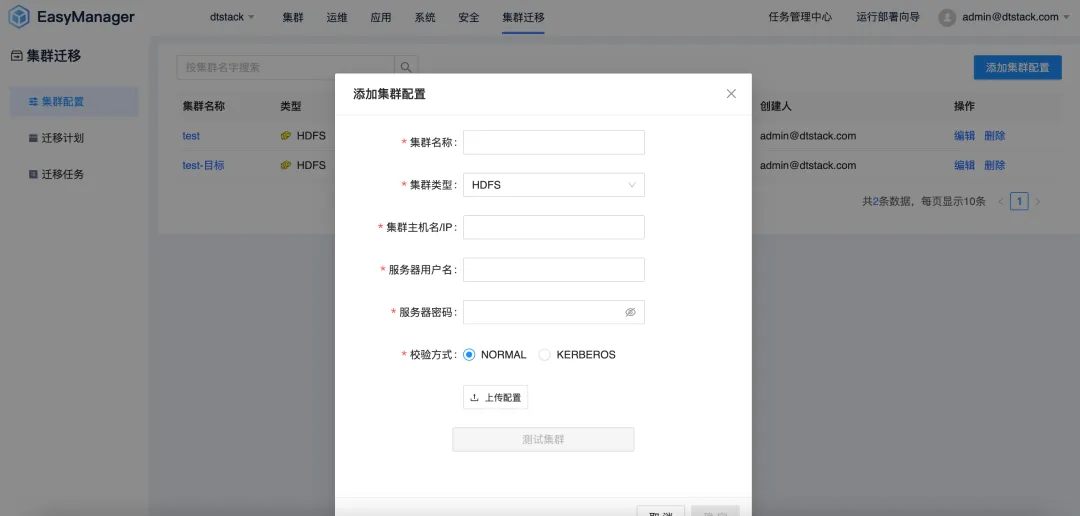
Cluster migration: seamless transition without business interruption
As an enterprise's business develops, the growing amount of data often leads to problems such as insufficient data center capacity or data center changes. Enterprises need to migrate data from one data center to another. At the same time, in the context of localization replacement, more and more companies are migrating non-innovation platforms such as CDH, HDP, and CDP to localized big data platforms. Therefore, EMR has launched a big data cluster migration function to help enterprises complete data center migration efficiently.
The cluster migration feature enables users to seamlessly migrate their big data clusters between different data centers or cloud services without worrying about data loss or business interruption. Through this feature, enterprises can more flexibly adjust their IT infrastructure to adapt to changing market needs.
Engine upgrade revealed: performance leap, new experience
The most exciting thing is that the EMR6.2 version has achieved a major breakthrough in computing engine performance . We not only optimized the existing Spark and Flink computing engines, but also introduced new algorithms and technologies to improve data processing speed and computing efficiency. This means that users can complete more complex data analysis tasks in a shorter time, thereby speeding up the decision-making process and improving corporate competitiveness.
● Spark3 supports Z-oreder index optimization
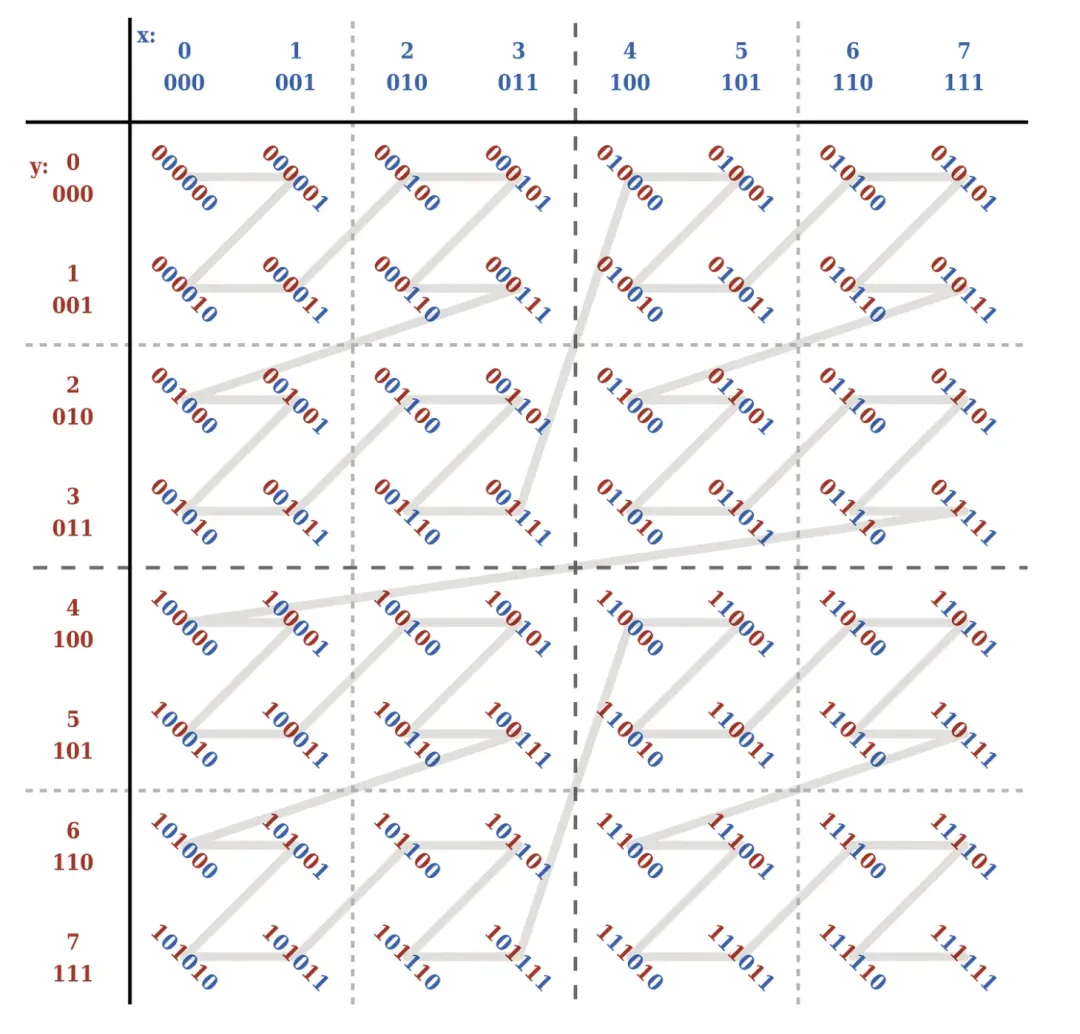
Z-Order is a technology that can compress multi-dimensional data into one dimension. For a piece of data, we can regard its multiple fields to be sorted as multiple dimensions of the data. Z-Order can pass certain rules Mapping multidimensional data to one-dimensional data.
Specifically, the z-value is constructed through certain rules . The z-value can be understood as the one-dimensional data mentioned above. At this time, we can sort based on the one-dimensional data. As shown below:
In Spark SQL, Kangaroo Cloud has added OPTIMIZE XX ZORDER BY syntax to support Z-Order index, realizing Z-Order index optimization of INSERT INTO table, INSERT OVERWRITE table, CREATE TABLE table AS SELECT, DISTINCT and other SQL.
Spark3 supports Z-order optimization, which greatly improves the efficiency of data processing and query, reduces IO overhead, and accelerates job execution. Especially in scenarios where large-scale data sets and complex query operations need to be processed, Z-order optimization can play an important role. In solving the problem of file compression rate, after using Z-order optimization, the file compression rate has increased by nearly 20% compared with manual optimization, and has increased by nearly 10 times compared with the original task. Compared with the open source Spark3 task, the performance is also nearly 30%. Improvement has greatly improved the performance and efficiency of offline operations.
● Flink Per-job task hot update
In actual production operations, real-time task parameter changes or operator and function tuning often occur. Usually, the current task can only be canceled first, and then CheckPoint is selected to restore or rerun. The whole process takes about 3-5 minutes to wait, which is very difficult. A big waste of task development time.
In order to solve the service interruption problem caused by task updates in the traditional Per-Job mode, improve task stability and system availability, and meet the requirements for business continuity and high availability in the production environment. The Kangaroo Cloud Engine team has conducted relevant exploration and source code improvements, and optimized hot restart of tasks in the asynchronous callback of Per-Job task cancellation :
① First determine whether there is a new JobGraph cache currently. If there is a cache, enter the hot restart logic.
② Obtain the CheckPoint information of the canceled task and fill it in the new JobGraph
③Update JobGrap to JobMaster and clear the cache information of JobGraph
④Clear the resources managed by SloyPool in JobMaster
⑤JobMaster re-creates ScheduleNg and schedules it to run. This will start a new JobGraph scheduling run.
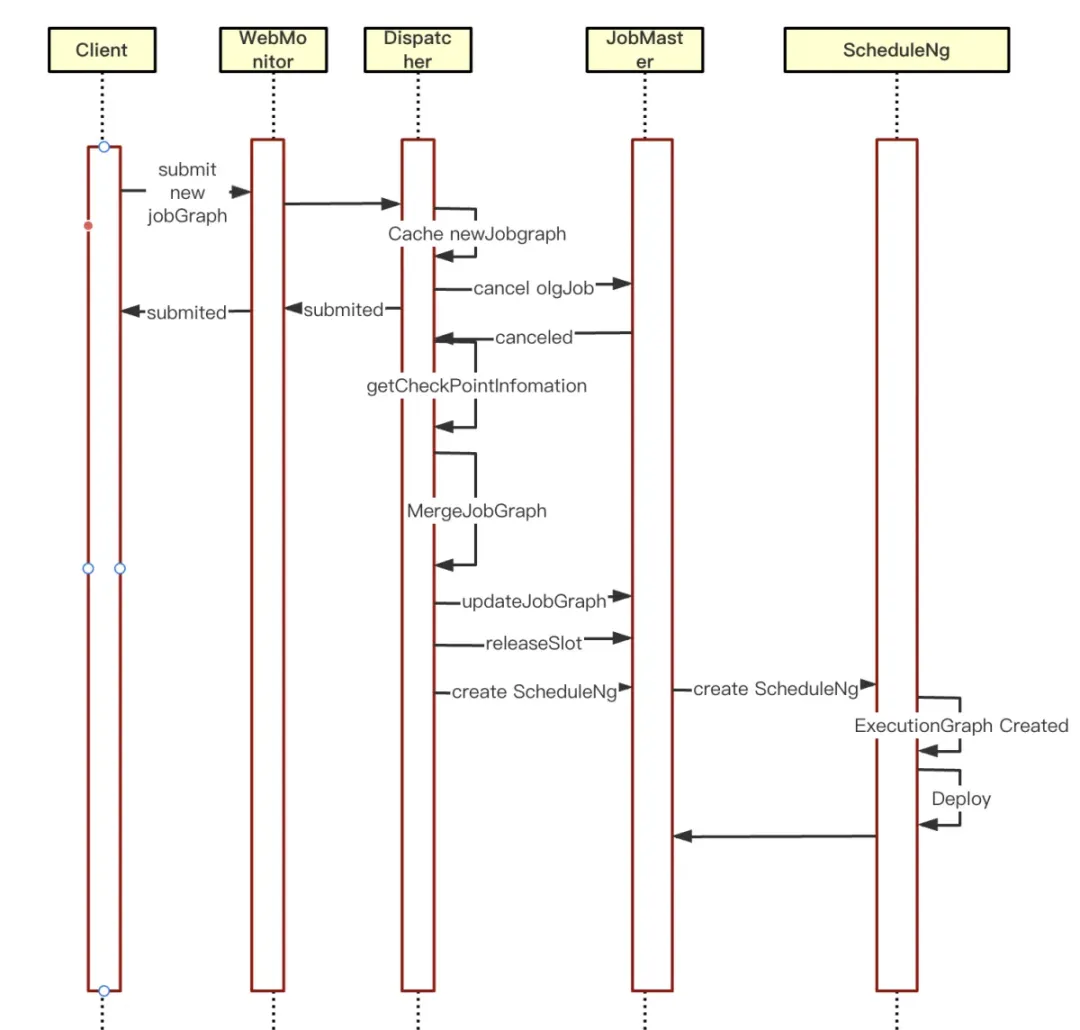
Flink Per-job 任务热更新优化之后显著提高了开发效率,减少停机时间并提升了应用程序的灵活性和可靠性。对于需要快速迭代和动态调整的实时应用程序,带来极致的效率体验。
Improved development efficiency: Developers can quickly test and iterate code without going through the tedious stop and restart process, which speeds up development cycles and allows for more frequent releases
· Reduce downtime: Hot updates can minimize application downtime, thereby increasing service availability, which is especially important for mission-critical and real-time applications.
· Dynamically adjust parameters: Job configuration parameters, such as parallelism or operator parameters , can be dynamically adjusted without restarting the job, allowing for flexible adjustments based on real-time data flow or load conditions.
● Other function development
In addition, on the engine side, we have also developed functions such as Spark Ranger docking , Spark materialized view optimization , and Flink Session mode class loading isolation to improve the engine's computing performance while enhancing the engine's task security and scalability.
Summarize
In summary, the release of EMR6.2 marks another important milestone for Kangaroo Cloud in the field of big data services. Through the optimization of four major functions, including comprehensive UI refresh and upgrade, differentiated configuration, cluster migration and engine upgrade, EMR6.2 provides users with a more powerful, flexible and efficient big data computing engine platform , helping enterprises in data management and A qualitative leap in analysis.
"Industry Indicator System White Paper" download address: https://www.dtstack.com/resources/1057?src=szsm
"Dutstack Product White Paper" download address: https://www.dtstack.com/resources/1004?src=szsm
"Data Governance Industry Practice White Paper" download address: https://www.dtstack.com/resources/1001?src=szsm
For those who want to know or consult more about big data products, industry solutions, and customer cases, visit the Kangaroo Cloud official website: https://www.dtstack.com/?src=szkyzg
Linus took it upon himself to prevent kernel developers from replacing tabs with spaces. His father is one of the few leaders who can write code, his second son is the director of the open source technology department, and his youngest son is an open source core contributor. Robin Li: Natural language will become a new universal programming language. The open source model will fall further and further behind Huawei: It will take 1 year to fully migrate 5,000 commonly used mobile applications to Hongmeng. Java is the language most prone to third-party vulnerabilities. Rich text editor Quill 2.0 has been released with features, reliability and developers. The experience has been greatly improved. Ma Huateng and Zhou Hongyi shook hands to "eliminate grudges." Meta Llama 3 is officially released. Although the open source of Laoxiangji is not the code, the reasons behind it are very heart-warming. Google announced a large-scale restructuring