
Source Team|Bytedance Live Operation PlatformIn the continuous construction of cross-domain data aggregation services based on ES, we found that many features of ES are quite different from commonly used databases such as MySQL. This article will share the implementation principles of ES, business selection suggestions in live broadcast platforms, and problems encountered in practice. and thinking.
ES Introduction and Application Scenarios
Elasticsearch is a distributed, near-real-time massive data storage, retrieval and analysis engine. What we often call "ELK" refers to a data system composed of Elasticsearch, Logstash/Beats, and Kibana that is capable of collection, storage, retrieval, and visualization. ES plays a role in data storage and indexing, data retrieval, and data analysis in similar data systems.
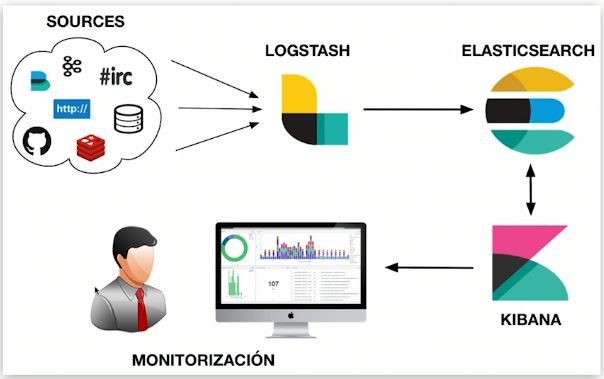
ES features
Each technology selection has its own characteristics, and the overall characteristics of ES are also affected by the underlying implementation. The second part of this article will detail the root causes of the following characteristics.
Pros:
-
Distributed: Through sharding, it can support up to PB level data and shield sharding details from the outside. Users do not need to be aware of read and write routing;
-
Scalable: Easy to expand horizontally, no need to manually divide databases and tables like MySQL or use third-party components;
-
Fast speed: parallel calculation of each shard, fast retrieval speed;
-
Full-text retrieval: multiple targeted optimizations, such as supporting multi-language full-text retrieval through various word segmentation plug-ins and improving accuracy through semantic processing;
-
Rich data analysis functions.
Cons:
-
Transactions are not supported: the calculation process of each shard is parallel and independent;
-
Near real-time: There is a delay of several seconds from when data is written to when the data can be queried;
-
The native DSL language is relatively complex and has a certain learning cost.
Common uses
Features will affect the application scenarios of components. In the document retrieval and analysis part, the live broadcast operation platform uses ES to aggregate various information of hundreds of millions of anchors and uses it to display various lists on the corresponding platform; the log retrieval part is used to detect Argos errors. Log search.
ES implementation and architecture
Next, understand how the above-mentioned ES advantages are realized and how the shortcomings are caused. When talking about ES, we must talk about Lucene. Lucene is a full-text search Java library. ES uses Lucene as the underlying component to implement all functions. The following mainly introduces the features of Lucene What functions, and what new capabilities does ES have compared to Lucene?
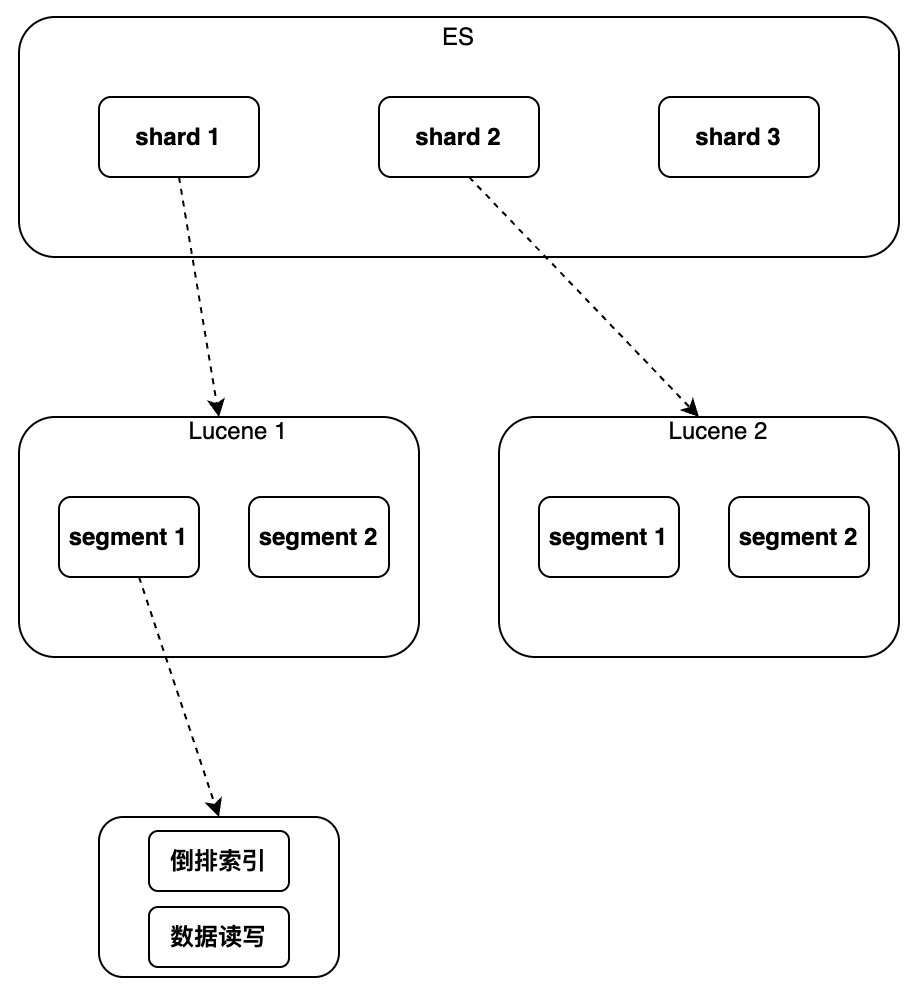
Lucene implements data indexing and retrieval on a single instance. It can support inverted index and sequential writing of data, but it does not support modification and deletion. There is no concept of global primary key. It cannot use a unified way to identify Documents and cannot support distribution. operate.
Therefore, ES has added some new features compared to Lucene
,
mainly including the new global primary key field "_id", which makes data modification/deletion and shard routing possible; and using a separate file to mark the deleted Document to "write new The Update operation is implemented by "Document, marking the old Document deleted"; by adding a new version number to the Document, concurrency is supported in the form of optimistic locking; the process of realizing distribution is by running multiple Lucene instances to route read and write requests and merge according to the primary key ID Query results; aggregation analysis has also been added, which can implement sorting, statistics, etc. analysis of query results. The specific implementation details will be introduced below in the order from single instance to cluster.
single instance
index
The purpose of indexing is to speed up the retrieval process. Index selection is an unavoidable issue for all databases. The initial target scenario of ES design is full-text retrieval, so it supports "inverted index" and has made many optimizations for this. In addition, it also supports other indexes such as Block Kd Tree. ES will automatically match the corresponding index type according to the field type and build indexes for the fields that need to be indexed.
Inverted index and Block Kd Tree are also commonly used index types for analysis. For strings, there are two common situations: Text uses word segmentation + inverted index, while Keyword uses non-word segmentation + inverted index. For numeric types, such as Long/Float, Block Kd Tree is usually used.
Inverted index
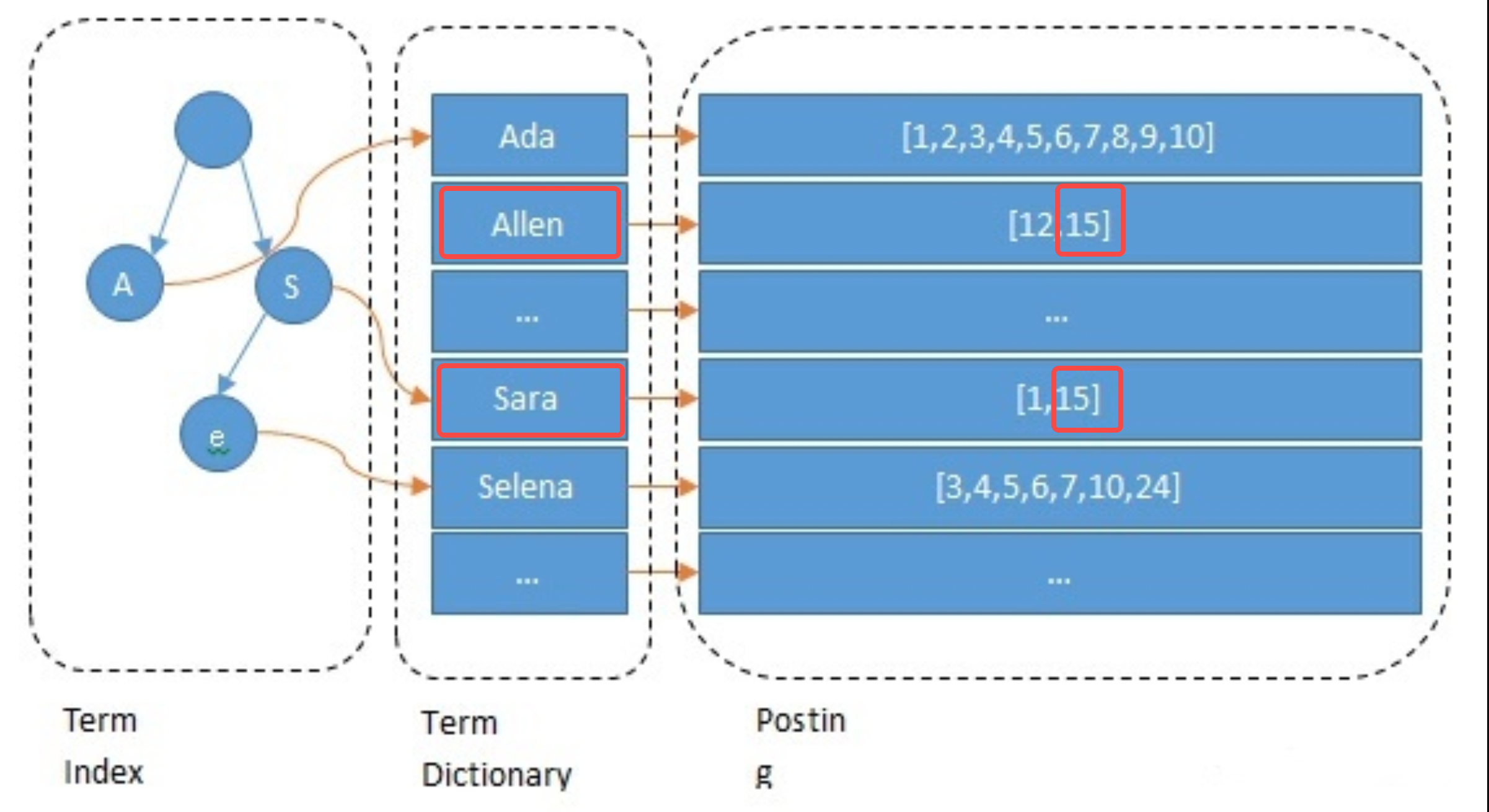
When building the index, ES will index each field by default. This process includes word segmentation, semantic processing and mapping table construction. First, the text will be segmented into words. The word segmentation method is related to the language, such as cutting by spaces in English. Then, meaningless words are deleted and semantic normalization is performed. Finally build the mapping table. The following example briefly shows the processing process of the Name field of anchor 15: it is segmented into allen and sara; converted to lowercase and other operations; and the mappings of allen->15 and sara->15 are constructed.
// 主播1 { "id": 1 "name":"ada sara" ... // 其他字段 } // 主播15 { "id": 15 "name":"allen sara" }
Query process
Take the query for the anchor named "allen sara" as an example. According to the word segmentation results, two lists [12, 15] and [1, 15] are found respectively (in actual applications, the query will also be based on synonyms); to merge the lists and scores, press The priority is to get the results [15, 12, 1] (this is the recall step in the search, and it will also be refined according to the algorithm).
Optimization items
In order to speed up retrieval and reduce memory/hard disk pressure, ES performs the following optimizations on the inverted index, which is also the advantage of ES over other components. What needs to be noted here is that the ultimate utilization of storage space may be a common feature of all databases. Redis also saves memory space in the same way: data is stored in as few bits as possible, and small sets and large sets are stored in different ways.
-
Term Index: Use prefix trees to speed up the positioning of "Term" words and solve the problem of slow retrieval speed caused by too many words;
-
Term Dictionary: Put words with the same prefix into a data block and retain only the suffix, such as [hello, head] -> [lo, ad];
-
Posting: Ordered + incremental coding + block storage, such as [9, 10, 15, 32, 37] -> [9, 1, 5, 17, 5], each element can use 5bit storage;
-
Posting merge optimization: Use Roaring Bitmap to save space. When using multi-condition queries, you need to merge multiple Postings;
-
Semantic processing: Content with similar semantics can be queried.
Features of inverted index:
-
Support full-text search: support multiple languages with different word segmentation plug-ins, such as the IK word segmentation plug-in to implement Chinese full-text search;
-
Small index size: The prefix tree greatly compresses space, and the index can be placed in memory to speed up retrieval;
-
Poor support for range search: limited by prefix tree selection;
-
Applicable scenarios: search by word, non-range search. ES non-numeric fields use this type of index.
B
lock
K d Tree index
The Block Kd Tree index is very friendly to range searches. Field types such as ES values, geo, and range all use this index type. In business selection, numerical fields that require range search should use numerical types such as Long. For inverted indexes, fields that do not require full-text search should use Keyword type. Otherwise, use Text.
Due to limited space, this article will not introduce too much here. Friends who are interested in BKd Tree can refer to the following content:
-
https://www.shenyanchao.cn/blog/2018/12/04/lucene-bkd/
-
https://www.elastic.co/cn/blog/lucene-points-6-0
data storage
This part mainly explains how the data in a single instance is stored in memory and hard disk.
Segmented storage Segment
The data of a single instance is up to hundreds of GB, and storing it in a file is obviously inappropriate. Like Kafka, Pulsar and other components that need to store Append Only data, ES chooses to split the data into segments for storage.
-
Segment: Each Segment has its own index file, and the results are merged after parallel queries;
-
Segment generation timing: scheduled generation or based on file size, the duration is configurable, usually a few seconds;
-
Segment merging: Because segments are generated regularly and are generally relatively small, they need to be merged into large segments.
Latency and data loss risk
-
Retrieval delay: Conditional retrieval depends on the index, and the index is only available when the segment is generated, so there is generally a delay of several seconds from writing to retrieval;
-
Risk of data loss: Newly generated segments will take tens of minutes to flush by default, and there is a risk of data loss;
-
Reduce the risk of data loss: Translog is additionally used to record write events. By default, the disk is flushed every 5 seconds, but there is still a risk of losing several seconds of data.
How to implement Delete/Update
-
Delete: Each Segment corresponds to a del file, recording the deleted ID, and the search results need to be filtered out;
-
Update: Write new documents and delete old documents.
cluster
Single-machine databases have problems such as limited capacity and throughput, and weak disaster recovery capabilities. These problems are generally solved through sharding and data redundancy. However, these two operations generally introduce the following problems. Let’s first look at how ES shards and backs up data, and then how to solve the following three questions: How are read and write requests routed to each shard? How to merge the search results of each shard? How to choose the master between active and standby instances?
Distributed Shard
The number of shards for each index can be configured independently. The following figure takes an index with three Shards as an example. The overall storage capacity is increased through horizontal expansion, and the retrieval speed is improved through parallel computing of each Shard.
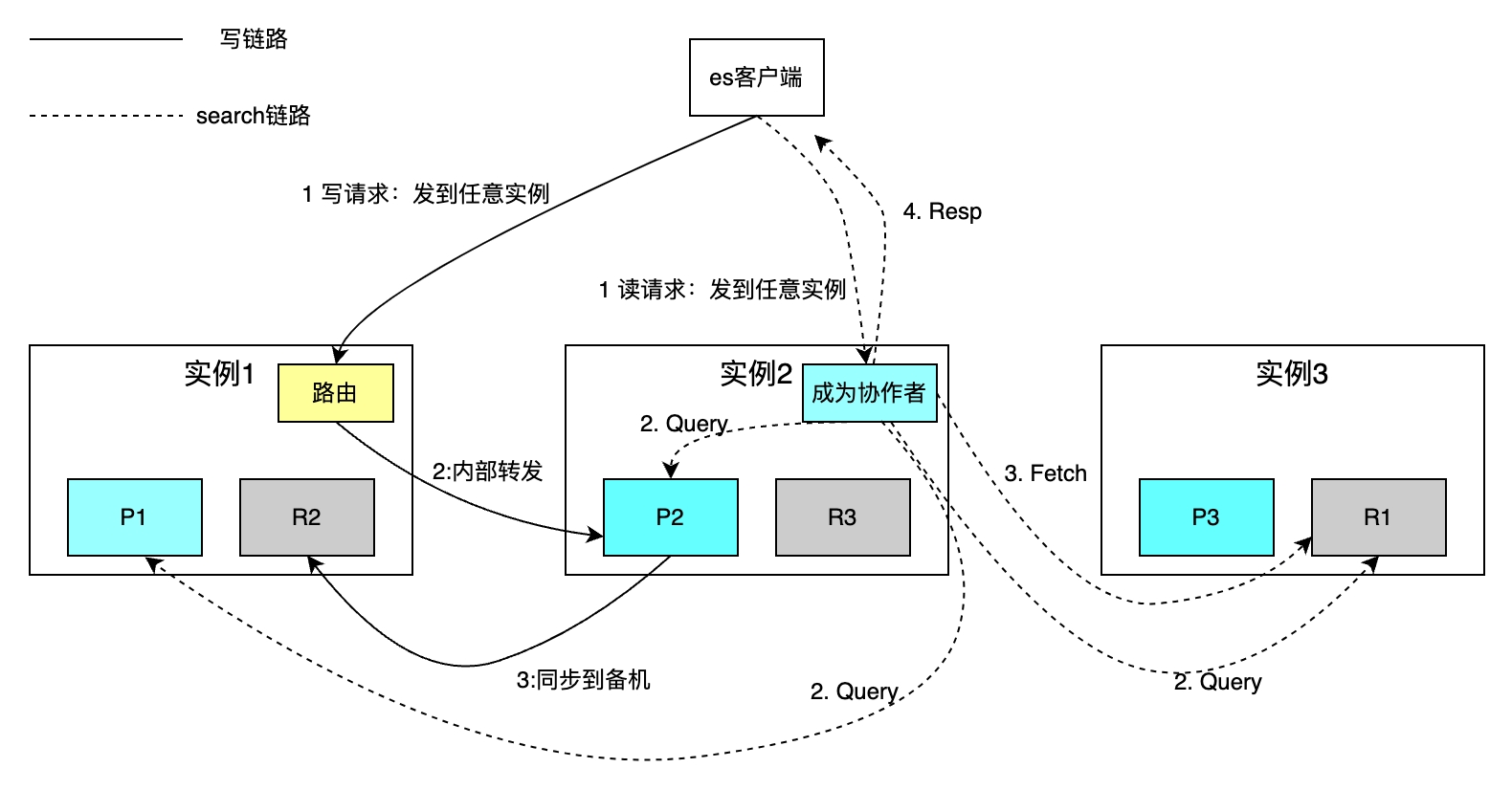
The routing policy reads and writes a single Document based on the primary key. Hash routing uses ID as the primary key by default. For write operations, if the business party does not specify the primary key ID, ES uses the Guid algorithm to automatically generate it. Due to routing policy restrictions, the increase or decrease in the number of shards requires the migration of all data. Search requests based on conditional retrieval are implemented through two steps: the collaborator Coordinate and Query Phase query phases, and the Fetch Phase acquisition phase. The collaborator sends a read request to any instance, and the instance sends the request to each shard in parallel. Each shard executes local SQL and returns 2000+100 data to the collaborator, each data including id and uid. The collaborator sorts all the sharded data, obtains the IDs of 100 Documents, and then obtains the data by ID and returns it to the client.
The disadvantage is that the above retrieval method shields the concept of sharding from the client, which greatly facilitates read and write operations. It does not need to be aware of sub-databases and tables like MySQL. However, each instance also needs to open up a space of from+limit size. When deep page turning occurs, a large amount of space is required; collaborators need to sort shard* (from+limit) documents and other issues.
In response to the above problems, in practice, we add parameters such as uid>2200 that change with each request to the conditional items of Search After, which can reduce the number of sorting from from+limit to Limit; for another form of Scroll Search After, Maintain the condition items of each request internally in ES and support concurrency.
Master-slave synchronization income
Benefits mainly include high availability through data redundancy and increased system throughput. The data synchronization method includes master-slave synchronization within the cluster, which is generally deployed in different computer rooms in the same region to speed up write operations. Synchronous or asynchronous can be selected. Consistency can be One, All or Quorum. In addition, there is cross-cluster synchronization (CCR), which is used for multi-cluster disaster recovery and nearby access in different regions. It adopts an asynchronous method and the index level can be one-way or two-way replication of data.
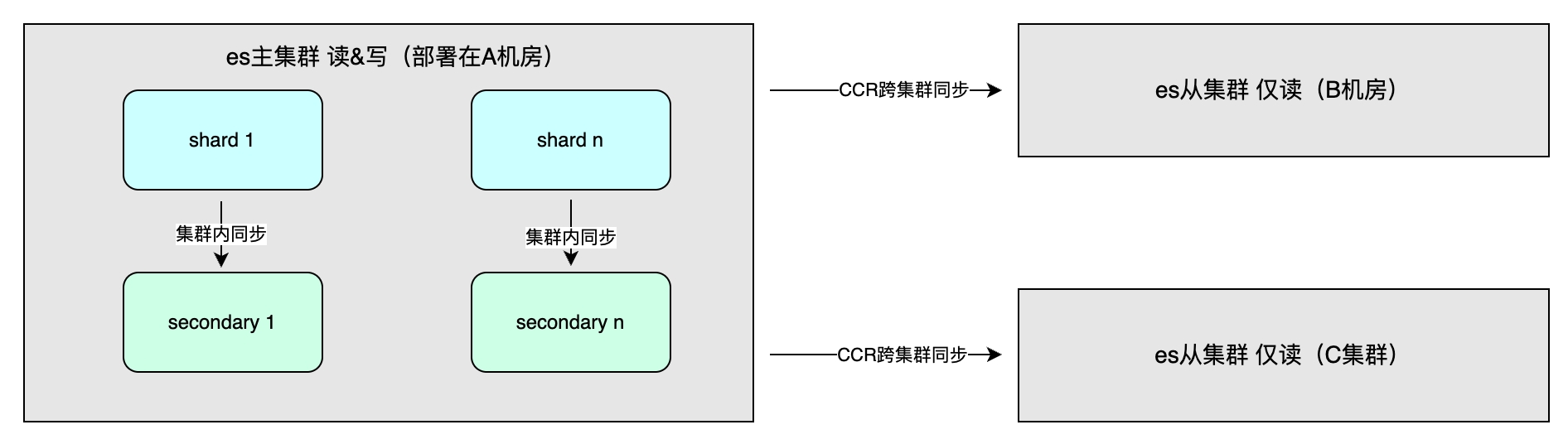
Applicable scene
The implementation details of ES determine its overall characteristics, which in turn affects applicable scenarios. Applicable scenarios include: large data volume, below the PB level; full-text retrieval, multi-field flexible indexing and sorting required; data visualization (Kibana); no requirements for transactions; low requirements for query latency after writing. However, it is not recommended to use ES as the only storage for important data, because there is a delay of several seconds and the risk of data loss, and unlike MySQL, high availability is carefully optimized in every detail.
Practice of cross-domain data aggregation system for live broadcast operation platform
Application scenarios
On the operation platform for live broadcast guilds and anchors, there are many scenarios for data viewing and analysis, such as anchor lists, anchors and guild tasks, etc. This type of data generally has the following characteristics: large data volume, many fields and from many sources. For example, the number of index fields for anchors is close to 200, the data sources are as many as 10+ (such as data platforms, security platforms, wallets, etc.), and operations such as retrieval and sorting by multiple fields are supported.
When users view data, it takes a lot of time to obtain data from each business party in real time, and it is difficult to perform conditional query and sorting based on multiple fields, so the data needs to be aggregated into a single database in advance. It is difficult for databases such as MySQL and Redis to meet the above characteristics, and ES can better support them. Therefore, we built a cross-domain data aggregation service system based on ES: consuming changes in upstream data sources and writing them to the ES large index to meet query needs. Take "Anchor Index" as an example to illustrate the data aggregation mode:
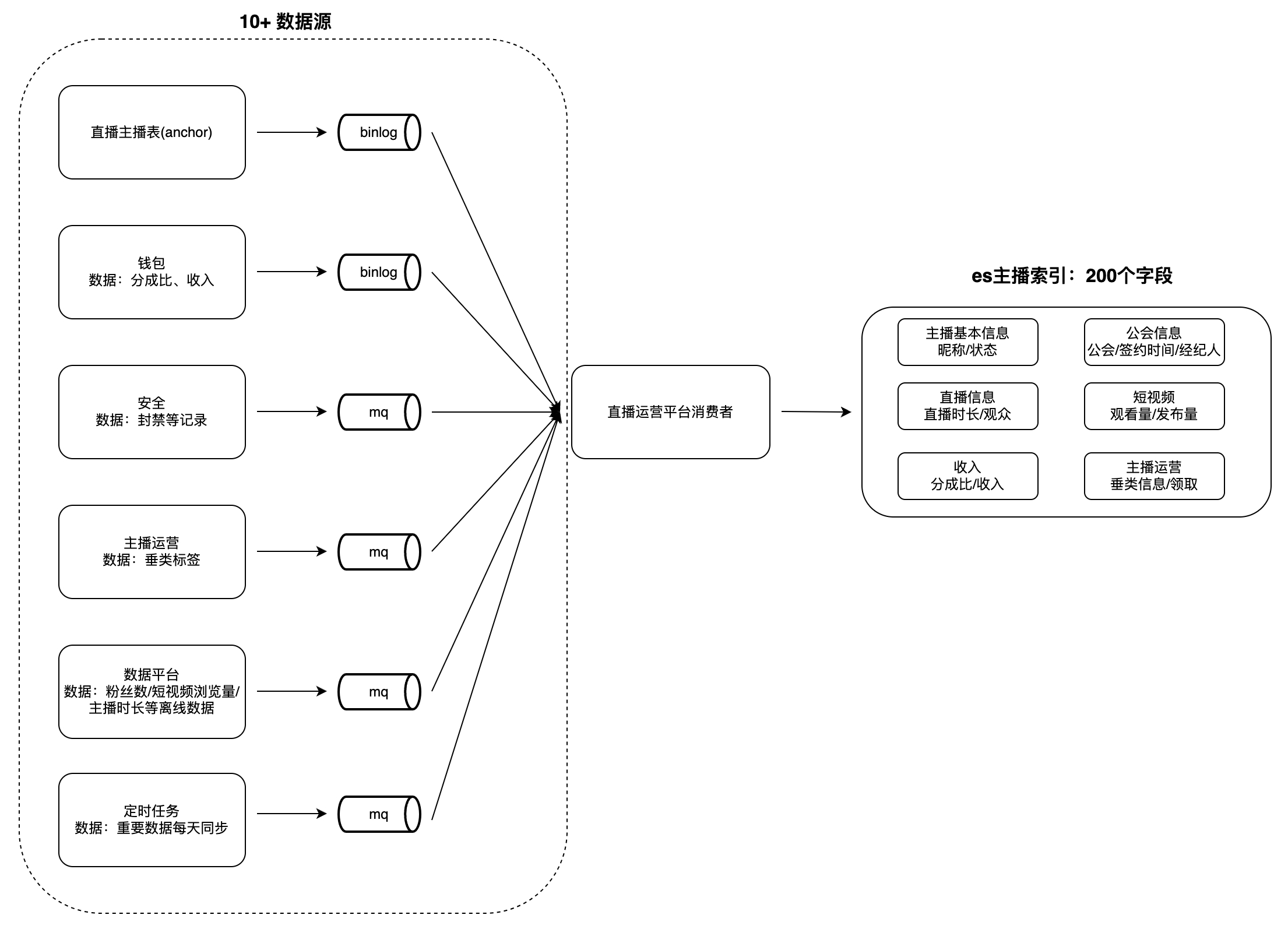
challenge
The first version of the implementation used a single PSM as a consumer to read upstream data and write it to ES. Since the writes were not isolated, there were many problems. First, all access parties write data consumption logic in the same PSM, resulting in high coupling of data processing logic and difficulty in maintenance. Secondly, there is a risk that multiple business parties may write to the same field, which may cause business exceptions. In addition, the full-coverage ES data writing mode results in slow data processing speed and low MQ consumption speed. At the same time, there are still problems such as resource competition and slow queries that cannot be associated with specific upstreams. With approximately 5 new fields added every bi-month and data continuing to grow, if these issues are not addressed, there will be greater challenges in the future.
Analysis of the above problems can be divided into three categories: the processing logic of each data source is highly coupled, and the whole is easily affected by a single business party; the data processing speed is slow, intensifying resource competition; the lack of read and write governance capabilities: write isolation, slow query statistics .
solution
The figure below introduces the overall structure after governance. Based on this, we will analyze the problems and considerations encountered in the governance process one by one.
This content cannot be displayed outside Feishu documents at the moment.
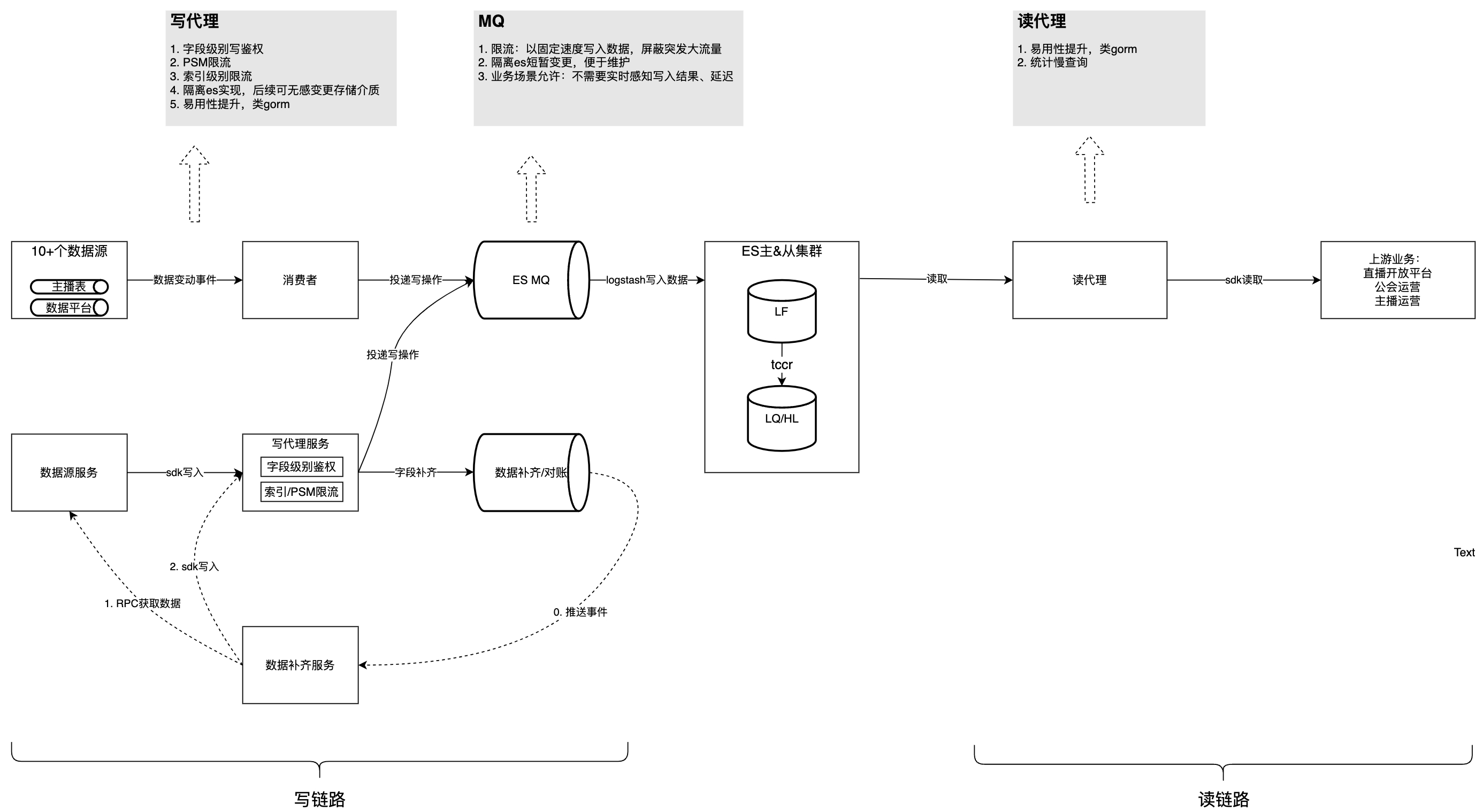
Problem 1: The consumption logic of each data source is strongly coupled, difficult to maintain, affects each other, and seizes resources.
The specific manifestation of this problem is that more than 10 MQ data consumption logics are implemented in the same PSM. The shared data processing logic and minor changes may affect other MQ processing, making maintenance inconvenient; the service monitors multiple MQ events, and there are Resource competition and uneven distribution of partitions of a single MQ event lead to uneven resource utilization on a single machine, which cannot be solved by horizontal expansion of the machine. Therefore, the code instability of a single MQ will affect the consumption of all MQ Topics. The uneven distribution of Partitions of individual MQ Topics will cause the CPU of individual consumer instances to skyrocket, thus affecting the consumption of other Topics.
Optimization Strategy:
-
Improve the consumption speed of a single event: ES partial update; review the current limiting configuration of all Topics;
-
Build more data writing methods and distribute the writing of non-core fields to various business sides. For example, it provides writing SDK and introduces Dsyncer.
Problem 2:
MQ
data consumption is slow and business data updates are delayed
The processing of a single MQ message is time-consuming. Taking the full coverage ES data writing mode as an example, updating one field requires writing the remaining fields that do not need to be updated together, because nearly 200 field data need to be obtained in real time through RPC. Overall It takes a long time and MQ consumption speed is slow; some MQ Topics consume 1 Worker in a single instance. The main impact is that the data update delay is high, and it takes a while for user information to be displayed on downstream platforms after changes. And each update requires nearly 200 fields to be obtained from multiple business parties. Abnormalities in a single data source will cause the entire MQ event consumption to fail and be retried.
Optimization Strategy:
-
Change the data writing mode of the ES cluster from full coverage to partial update: a single field can be updated on demand, and the Consumer no longer needs to obtain nearly 200 fields from multiple business parties, which not only reduces data processing time, but also reduces code Difficulty of maintenance;
-
Configure all MQ Topics to have multiple Workers, and those that require sequential consumption are configured to be routed to the same Worker based on the primary key ID.
Problem 3: Writing is not isolated/authenticated/limited
Field writing lacks isolation and authentication, and there is a risk that multiple business parties may write to the same field, which may cause business anomalies. The main reason is that the writing parties share resources. If one party writes too quickly, it will occupy the resources of other parties, causing the writing delay to increase. Therefore, it is necessary to strictly control the core field updates of ES storage to avoid triggering a large amount of feedback from users.
Optimization Strategy:
-
Added field-level write authentication, allowing only authorized PSMs to write certain field data;
-
To carry out traffic limiting strategies in the two dimensions of PSM and index, dynamically configurable components on the general traffic management platform are used.
Problem 4: Lack of slow query statistics and optimization methods
Like MySQL and other databases, non-standard SQL will lead to unnecessary scans and large query delays. ES provides the ability to query time-consuming SQL, but it cannot correlate upstream PSM, Logid and other information, making troubleshooting difficult.
Optimization strategy: The reading agent records SQL, upstream PSM, Logid and other messages that take more than the threshold in the form of an intermediate layer to the ES, and reports slow query conditions every day.
Question 5: Ease of use
Optimization Strategy:
-
Enable the ES SQL plug-in in the ES cluster. Because the ES SQL syntax is slightly different from MySQL SQL, additional support is provided through the read agent service: the user side uses MySQL syntax, and the read agent uses regular expressions to rewrite SQL to ES SQL standards; inject ScrollID into ES SQL, the user side does not need to care about how to express the Scroll query in SQL;
-
Help users deserialize query data into structures.
// es dsl查询样例 GET twitter/_search { "size": 10, "query": { "match" : { "title" : "Elasticsearch" } }, "sort": [ {"date": "asc"} ] } // 使用读sdk的等价sql select * from twitter where title="Elasticsearch" order by date asc limit 10
Governance results
Through the above governance, the accumulation of write links has been completely eliminated, and the consumption capacity has increased by 150%, which is specifically reflected in increasing the QPS of the business from 4k to 10k, without reaching the system performance upper limit. The peak reading QPS is 1500, and the SLA is stable at 99.99% in the long term. Currently, multiple business parties are using the SDK, and the business parties reported that the access time has been reduced from the original 2 days to 0.5 days.
Follow-up planning
Follow-up planning mainly includes expanding MVP reconciliation capabilities from individual scenarios to all scenarios; promoting upstream business optimization of SQL based on slow query statistics; and providing more data writing methods, such as FaaS.
Based on ByteDance's internal large-scale best practice experience, Volcano Engine provides externally consistent
ES
products
-
cloud search service
enterprise-level cloud products. The cloud search service is compatible with Elasticsearch, Kibana and other software and commonly used open source plug-ins. It provides multi-condition retrieval, statistics, and reports of structured and unstructured text. It can achieve one-click deployment, elastic scaling, simplified operation and maintenance, and quickly build log analysis, Information retrieval and analysis and other business capabilities.
{{o.name}}
{{m.name}}