
Master-slave delay tuning ideas
1. What is master-slave delay?
The essence is that the playback of the slave library cannot keep up with the master library, and the playback stage is delayed.
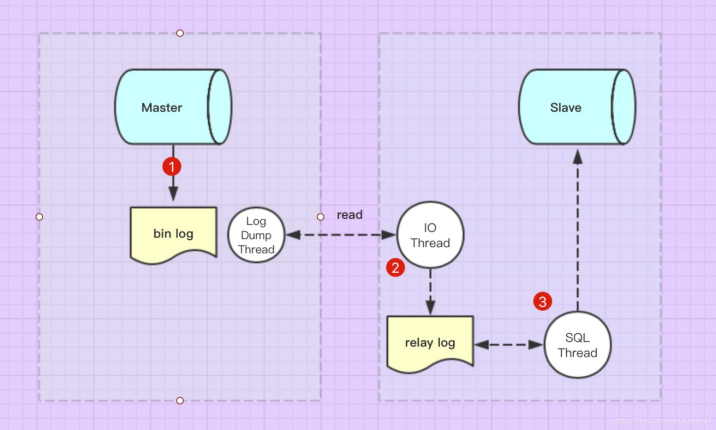
2. What are the common causes of master-slave delay?
1. For large transactions, the slave library playback time is long, resulting in master-slave delay.
2. The main library writes too frequently and the slave library cannot keep up with playback.
3. Unreasonable parameter configuration
4. Differences in master-slave hardware
5. Network delay
6. The table does not have a primary key or the index is updated frequently and frequently.
7. Some architectures that separate reading and writing put greater pressure on the slave library.
3. What are the methods to solve the master-slave delay?
1. For large transactions, split them into small transactions
2. Enable parallel replication
3. Upgrade slave hardware
4. Try to have primary keys
4. What is parallel replication and what are its parameters?
Review the journey of MySQL parallel replication
MySQL5.6 is based on database-level parallel replication
slave-parallel-type=DATABASE (transactions in different libraries, no lock conflicts)
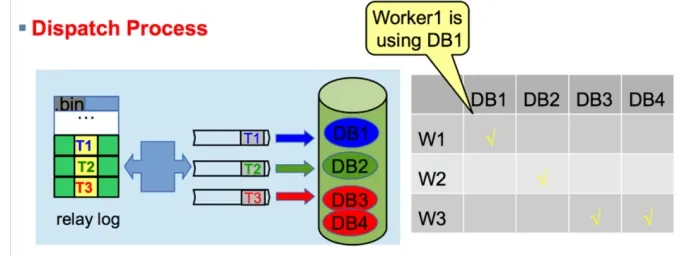
MySQL5.7 Parallel replication based on group commit
slave-parallel-type=LOGICAL_CLOCK : Commit-Parent-Based模式(同一组的事务[last-commit相同]There is no lock conflict. In the same group, there must be no conflict, otherwise there is no way to become the same group)
The above is the configuration of the slave library. Parallel replication depends on the group submission of the master library (note the distinction between group replication)
greatsql> show variables like '%group%delay%';
+-----------------------------------------+-------+
| Variable_name | Value |
+-----------------------------------------+-------+
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
+-----------------------------------------+-------+
2 rows in set (0.01 sec)
-
binlog_group_commit_sync_delay: How long to wait before submitting the group -
binlog_group_commit_sync_no_delay_count: How many transactions to wait before committing the group
The above parameters all depend on the busy situation of the main database. If the business is not frequent, it will be very embarrassing.
binlog_group_commit_sync_no_delay_count: This parameter is set to 2
For example, if only one thread executes one transaction, and the second transaction is executed 24h later, then this transaction needs to wait 24h before being submitted, which is very frustrating.
binlog_group_commit_sync_delay
If it is set to 200ms and only one thread executes a transaction, it can be submitted in 10ms, but it must wait for 200ms.
Generally, both are set up online. For example, it is like a small boat transporting people across a river.
Suppose our parameters are set like this:
binlog_group_commit_sync_delay=200;
binlog_group_commit_sync_no_delay_count=2
Either you can go directly if you need 200ms, or you can go directly if you need 2 people. This is a lot more user-friendly, but it is still embarrassing when the business is not busy.

MySQL8.0 parallel replication based on write-set
Conflict detection based on primary key (binlog_transaction_depandency_tracking = COMMIT_ORDERE|WRITESET|WRITESET_SESSION, if there is no conflict in the primary key or non-empty unique key of the modified row, it can be parallelized)
Transaction detection algorithm:transaction_write_set_extraction = XXHASH64
MySQL will have a variable to store the HASH value of the submitted transaction. After hashing, the values of the primary key (or unique key) modified by all submitted transactions will be compared with the set of that variable to determine whether the change of row conflicts with it, and To determine dependencies
The variables mentioned here can be set in size through this:binlog_transaction_dependency_history_size
This kind of granularity has reached the row level, that is, the parallel granularity is more refined at this time, and the parallel speed will be faster. In some cases, it is not an exaggeration to say that the parallelism of the slave exceeds the master ( the master is a single-threaded write, slave can also play back in parallel )
Simply put, it is parallel playback based on rows. Different rows at the rc level will not have lock conflicts.
Group submission performance:
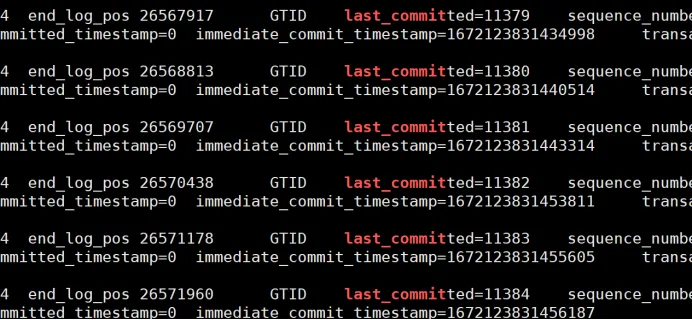
Check whether the last_committed value of the main library binlog is consistent. If consistent, it can be played back in parallel. If it is inconsistent, it can only be played back serially.
5. Practical analysis
5.1 Check the online master-slave delay
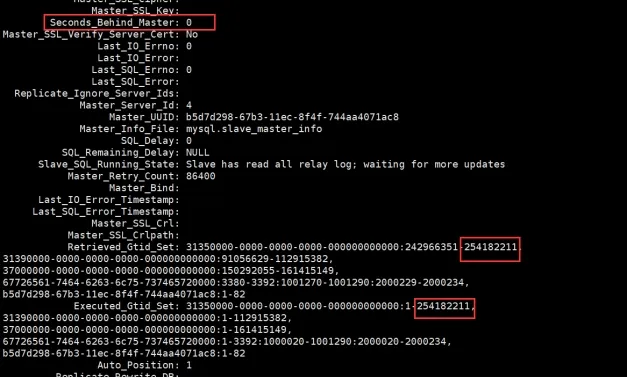
Seconds_Behind_Master: 48828
It can be seen that the delay is very high, close to 14 hours. At this time, the main library is also constantly writing data, about 6 minutes for one binlog and one for 500M
5.2 View current replication configuration
View the slave library configuration:
greatsql> show variables like '%slave%para%';
+------------------------+---------------+
| Variable_name | Value |
+------------------------+---------------+
| slave_parallel_type | LOGICAL_CLOCK |
| slave_parallel_workers | 128 |
+------------------------+---------------+
2 rows in set (0.02 sec)
Delay phenomenon:
The slave library has been chasing, indicating that it is not a big transaction, but Seconds_Behind_Masterthe delay has been increasing.
Retrieved_Gtid_Set: 00000000-0000-0024-0046-41a8003b4b99:242966351-253068975,
00000000-0000-0040-0095-5fff003b4b99:91056629-110569633,
00000000-0000-005c-0ced-7bae003b4b99:150292055-160253193,
31f4399f-ade5-11ed-a544-00163ebdeb51:1-12,
Executed_Gtid_Set: 00000000-0000-0024-0046-41a8003b4b99:1-252250235,
00000000-0000-0040-0095-5fff003b4b99:1-109120315,
00000000-0000-005c-0ced-7bae003b4b99:1-159504296,
31f4399f-ade5-11ed-a544-00163ebdeb51:1-12,
Auto_Position: 1
At this time, it is suspected that there is no parallel replication, and the main library may not have set up group submission (just a guess)
5.3 For further verification, check the binlog of the main library
Check the parameter configuration of the main library: still the rules submitted for the group
greatsql> show variables like '%binlog_transac%';
+--------------------------------------------+----------+
| Variable_name | Value |
+--------------------------------------------+----------+
| binlog_transaction_compression | OFF |
| binlog_transaction_compression_level_zstd | 3 |
| binlog_transaction_dependency_history_size | 25000 |
| binlog_transaction_dependency_tracking | WRITESET |
+--------------------------------------------+----------+
4 rows in set (0.02 sec)
Look at the configuration of group submission: it means there is no group submission.
greatsql> show variables like '%group%delay%';
+-----------------------------------------+-------+
| Variable_name | Value |
+-----------------------------------------+-------+
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
+-----------------------------------------+-------+
2 rows in set (0.01 sec)
After further verification, looking at the binlog, we found that last_committed is indeed different, indicating that parallelism is not possible.

5.4 Set parameters for the main library and parse its binlog again
will binlog_transaction_dependency_trackingbe changed to WRITESETmode
greatsql> show variables like '%transaction%';
+----------------------------------------------------------+-----------------+
| Variable_name | Value |
+----------------------------------------------------------+-----------------+
| binlog_direct_non_transactional_updates | OFF |
| binlog_transaction_compression | OFF |
| binlog_transaction_compression_level_zstd | 3 |
| binlog_transaction_dependency_history_size | 25000 |
| binlog_transaction_dependency_tracking | WRITESET |
| kill_idle_transaction | 300 |
| performance_schema_events_transactions_history_long_size | 10000 |
| performance_schema_events_transactions_history_size | 10 |
| replica_transaction_retries | 10 |
| session_track_transaction_info | OFF |
| slave_transaction_retries | 10 |
| transaction_alloc_block_size | 8192 |
| transaction_allow_batching | OFF |
| transaction_isolation | REPEATABLE-READ |
| transaction_prealloc_size | 4096 |
| transaction_read_only | OFF |
| transaction_write_set_extraction | XXHASH64 |
+----------------------------------------------------------+-----------------+
17 rows in set (0.00 sec)
Check its binlog again and see that many of them can be played back in parallel.

5.5 Optimization completed
Even though the main library is writing in large batches, the delay is slowly shrinking. It is only a matter of time before it catches up. Today it is 0
Enjoy GreatSQL :)
About GreatSQL
GreatSQL is a domestic independent open source database suitable for financial-level applications. It has many core features such as high performance, high reliability, high ease of use, and high security. It can be used as an optional replacement for MySQL or Percona Server and is used in online production environments. , completely free and compatible with MySQL or Percona Server.
Related links: GreatSQL Community Gitee GitHub Bilibili
GreatSQL Community:

Community reward suggestions and feedback: https://greatsql.cn/thread-54-1-1.html
Community blog prize-winning submission details: https://greatsql.cn/thread-100-1-1.html
(If you have any questions about the article or have unique insights, you can go to the official community website to ask or share them~)
Technical exchange group:
WeChat & QQ group:
QQ group: 533341697
WeChat group: Add GreatSQL Community Assistant (WeChat ID: wanlidbc) as a friend, and wait for the community assistant to add you to the group.