
Based on Apache Doris's common questions about the reading and writing process, copy consistency mechanism, storage mechanism, high availability mechanism, etc., it is sorted out and answered in the form of questions and answers. Before we begin, let us first explain the terms related to this article:
-
FE : Frontend, the front-end node of Doris. Mainly responsible for receiving and returning client requests, metadata, cluster management, query plan generation, etc.
-
BE : Backend, the backend node of Doris. Mainly responsible for data storage and management, query plan execution, etc.
-
BDBJE : Oracle Berkeley DB Java Edition. In Doris, BDBJE is used to complete the persistence of metadata operation logs, FE high availability and other functions.
-
Tablet : Tablet is the actual physical storage unit of a table. A table is stored in units of tablets in the distributed storage layer formed by BE according to partitions and buckets. Each tablet includes meta information and several consecutive RowSets.
-
RowSet : RowSet is a data collection of a data change in Tablet. Data changes include data import, deletion, update, etc. RowSet records by version information. Each change will generate a version.
-
Version : consists of two attributes: Start and End, and maintains record information of data changes. Usually used to represent the version range of RowSet. After a new import, a RowSet with equal Start and End is generated. After Compaction, a ranged RowSet version is generated.
-
Segment : Represents data segments in RowSet. Multiple Segments constitute a RowSet.
-
Compaction : The process of merging consecutive versions of RowSet is called Compaction, and the data will be compressed during the merging process.
-
Key column, Value column : In Doris, data is logically described in the form of a table. A table includes rows (Row) and columns (Column). Row is a row of user data, and Column is used to describe different fields in a row of data. Column can be divided into two categories: Key and Value. From a business perspective, Key and Value can correspond to dimension columns and indicator columns respectively. The Key column of Doris is the column specified in the table creation statement. The column following the keyword unique key or aggregate key or duplicate key in the table creation statement is the Key column. In addition to the Key column, the rest is the Value column.
-
Data model : Doris' data model is mainly divided into three categories: Aggregate, Unique, and Duplicate.
-
Base table : In Doris, we call the table created by the user through the table creation statement the Base Table. The Base table stores the basic data stored in the manner specified by the user's table creation statement.
-
ROLLUP table : On top of the Base table, users can create any number of ROLLUP tables. These ROLLUP data are generated based on the Base table and are physically stored independently. The basic function of the ROLLUP table is to obtain coarser-grained aggregate data based on the Base table, similar to a materialized view.
Q1: What is the difference between Doris partitioning and bucketing?
Doris supports two levels of data partitioning:
-
The first layer is Partition, which supports Range and List division methods (similar to the concept of MySQL's partition table). Several Partitions form a Table, and Partition can be regarded as the smallest logical management unit. Data can be imported and deleted only for one Partition.
-
The second layer is Bucket (Tablet is also called bucketing), which supports Hash and Random division methods. Each Tablet contains several rows of data, and the data between Tablets has no intersection and is physically stored independently. Tablet is the smallest physical storage unit for operations such as data movement and copying.
You can also use only one level of partitioning. If you do not write a partitioning statement when creating a table, Doris will generate a default partition, which is transparent to the user.
The indication is as follows:
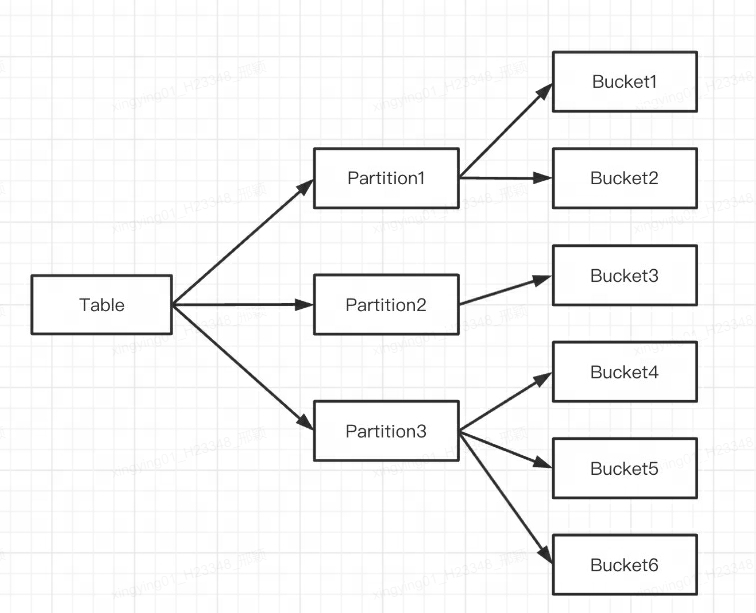
Multiple Tablets logically belong to different partitions (Partition). One Tablet only belongs to one Partition, and one Partition contains several Tablets. Because the Tablet is physically stored independently, it can be considered that the Partition is also physically independent.
Logically speaking, the biggest difference between partitioning and bucketing is that bucketing randomly splits the database, while partitioning splits the database non-randomly.
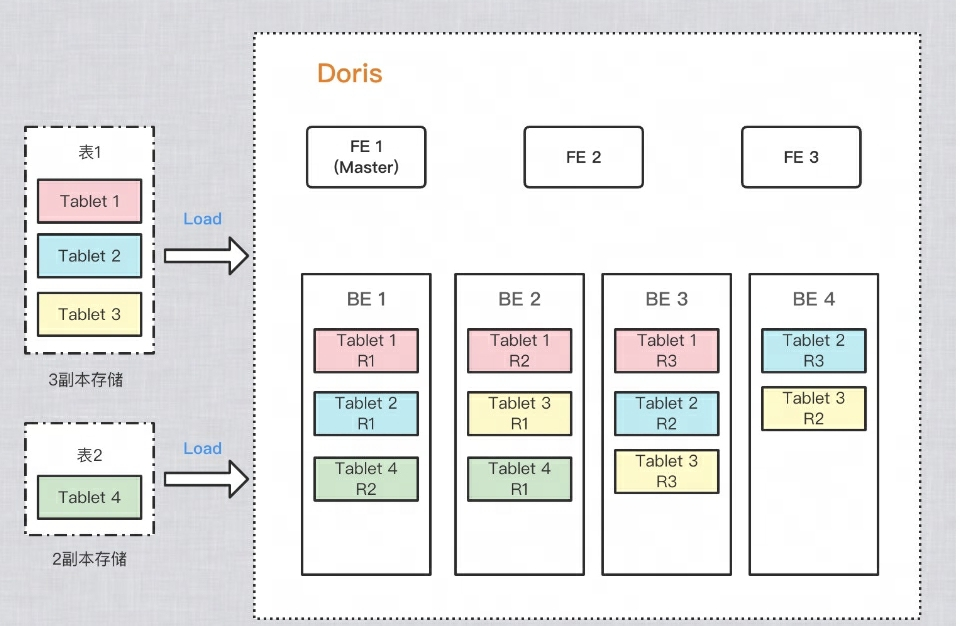
How to ensure multiple copies of data?
In order to improve the reliability of data storage and calculation performance, Doris makes multiple copies of each table for storage. Each copy of data is called a copy. Doris uses Tablet as the basic unit to store copies of data. By default, a shard has 3 copies. When creating a table, you can PROPERTIESset the number of copies in:
PROPERTIES
(
"replication_num" = "3"
);
As an example in the figure below, two tables are imported into Doris respectively. Table 1 is stored in 3 copies after import, and table 2 is stored in 2 copies after import. The data distribution is as follows:
Q2: Why do you need bucketing?
In order to cut into buckets and avoid data skew, and to disperse read IO and improve query performance, different copies of the Tablet can be dispersed on different machines, so that the IO performance of different machines can be fully utilized during queries.
Q3: What is the storage structure and format of physical files?
Each import of Doris can be regarded as a transaction and a RowSet will be generated. And RowSet includes multiple Segments, that is Tablet-->Rowset-->Segment. So how does BE store these files?
Doris's storage structure
Doris storage_root_pathconfigures the storage path through , and Segment files are stored in tablet_idthe directory and managed by SchemaHash. There can be multiple Segment files, which are generally divided according to size. The default is 256MB. The storage directory and Segment file naming rules are:
${storage_root_path}/data/${shard}/${tablet_id}/${schema_hash}/${rowset_id}_${segment_id}.dat
Enter storage_root_paththe directory and you can see the following storage structure:
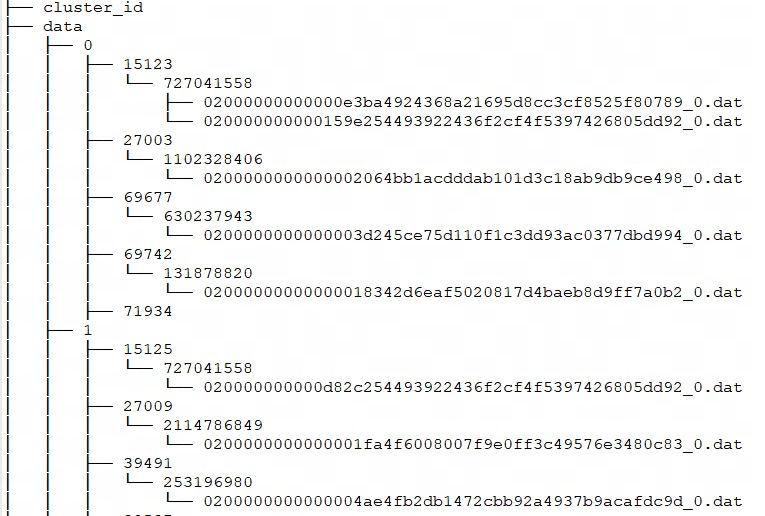
-
${shard}: That is 0, 1 in the above figure. It is automatically created by BE in the storage directory and is random. It will increase with the increase of data. -
${tablet_id}: That is, 15123, 27003, etc. in the above figure, which is the ID of the Bucket mentioned above. -
${schema_hash}: That is, 727041558, 1102328406, etc. in the picture above. Because the structure of a table may be changed, one is generated for each Schema versionSchemaHashto identify the data under that version. -
${segment_id}.dat: The first one isrowset_id, that is, 02000000000000e3ba4924368a21695d8cc3cf8525f80789 in the above figure;${segment_id}it is the current RowSetsegment_id, starting from 0 and increasing.
Segment file storage format
The overall file format of Segment is divided into three parts: data area, index area and Footer, as shown in the following figure:

-
Data Region: Used to store the data information of each column. The data here is loaded in Pages on demand. The Pages contain the column data, and each Page is 64k.
-
Index Region: Doris stores the Index data of each column in the Index Region. The data here will be loaded according to the column granularity, so it is stored separately from the column data information.
-
Footer information: Contains metadata information of the file, checksum of the content, etc.
Q4: What are the DML limitations of Doris's different table models?
-
Update: The Update statement currently only supports the UNIQUE KEY model, and only supports updating the Value column.
-
Delete: 1) If the table model uses an aggregate class (AGGREGATE, UNIQUE), the Delete operation can only specify the conditions on the Key column; 2) This operation will also delete the data of the Rollup Index related to this Base Index.
-
Insert: All data models can be Insert.
How to implement Insert? How can the data be queried after it is inserted?
-
AGGREGATE model : In the Insert phase, the incremental data is written to the RowSet in the Append method, and in the query phase, the Merge on Read method is used for merging. That is to say, the data is first written into a new RowSet when importing, and deduplication will not be performed after writing. Multi-way concurrent sorting will only be performed when a query is initiated. When performing multi-way merge sorting, duplicate data will be sorted. Keys are arranged together and aggregated. The higher version Key will overwrite the lower version Key, and ultimately only the record with the highest version will be returned to the user.
-
DUPLICATE model : This model is written similarly to the above, and there will be no aggregation operations in the reading phase.
-
UNIQUE model : Prior to version 1.2, this model was essentially a special case of the aggregate model, with behavior consistent with the AGGREGATE model. Since the aggregation model is implemented by Merge on Read , the performance on some aggregation queries is poor. Doris introduced a new implementation of the Unique model after version 1.2, Merge on Write , which marks and deletes overwritten and updated data when writing. During query, all marked and deleted data are deleted. The data will be filtered out at the file level, and the read data will be the latest data, eliminating the data aggregation process in read-time merging, and can support push-down of multiple predicates in many cases.
Simply put, the processing flow of Merge on Write is:
-
For each Key, find its position in the Base data (RowSetid + Segmentid + row number) [Segment-level primary key interval tree is maintained in memory to speed up queries]
-
If the Key exists, mark the row of data for deletion. The information marked for deletion is recorded in the Delete Bitmap, where each Segment has a corresponding Delete Bitmap.
-
Write the updated data into the new RowSet, complete the transaction, and make the new data visible, that is, it can be queried by the user.
-
When querying, read the Delete Bitmap, filter out the rows marked for deletion, and only return valid data [For all hit Segments, query according to version from high to low]
The following introduces the implementation of the writing process and reading process.
Writing process : When writing data, the primary key index of each Segment will be created first, and then the Delete Bitmap will be updated.
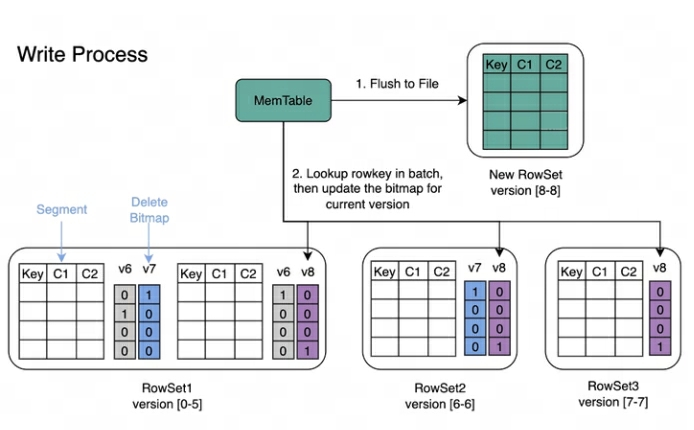
Reading process : The reading process of Bitmap is shown in the figure below. From the picture we can know:
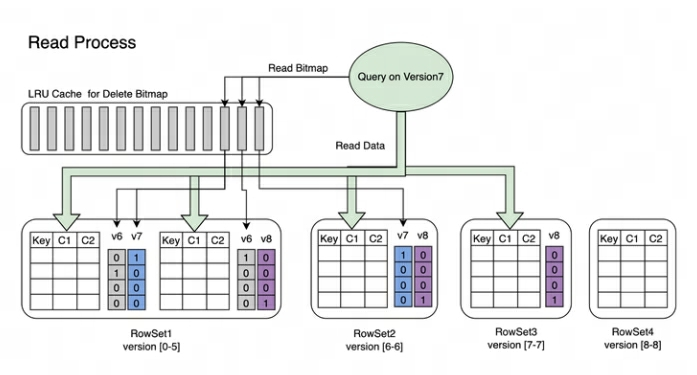
-
A Query that requests version 7 will only see data corresponding to version 7.
-
When reading the data of RowSet5, the Bitmaps generated by V6 and V7 modifications to it will be merged together to obtain the complete DeleteBitmap corresponding to Version7, which is used to filter the data.
-
In the example above, the import of version 8 covers a piece of data in Segment2 of RowSet1, but the Query requesting version 7 can still read the data.
How is Update implemented?
The UNIQUE model Update process is essentially Select+Insert.
-
Update uses the query engine's own Where filtering logic to filter out the rows that need to be updated from the table to be updated, and based on this, maintain the Delete Bitmap and generate newly inserted data.
-
Then execute the Insert logic. The specific process is similar to the above-mentioned UNIQUE model writing logic.
Q5: How is Doris' Delete implemented? Will a RowSet be generated as well? How to delete the corresponding data?
-
Doris' Delete will also generate a RowSet. In DELETE mode, the data is not actually deleted, but the data deletion conditions are recorded. Stored in Meta information. When executing Base Compaction, the deletion conditions will be merged into the Base version.
-
Doris also supports LOAD_DELETE under the UNIQUE KEY model, which enables data deletion by batch importing the keys to be deleted, and can support large-scale data deletion capabilities. The overall idea is to add a deletion status identifier to the data record, and the deleted Key will be compressed during the Compaction process. Compaction is mainly responsible for merging multiple RowSet versions.
Q6: What indexes does Doris have?
Currently, Doris mainly supports two types of indexes:
-
Built-in smart indexes, including prefix indexes and ZoneMap indexes.
-
Secondary indexes manually created by users include inverted indexes, Bloomfilter indexes, Ngram Bloomfilter indexes and Bitmap indexes.
The ZoneMap index is an index information automatically maintained for each column in column storage format, including Min/Max, the number of Null values, etc. This indexing is transparent to the user.
What level is the index?
-
Now all indexes in Doris are BE-level Local, such as inverted index, Bloomfilter index, Ngram Bloomfilter index and Bitmap index, prefix index and ZoneMap index, etc.
-
Doris does not have a Global Index. In a broad sense, partitions + bucket keys can also be considered Global, but they are relatively coarse-grained.
What is the storage format of the index?
In Doris, the Index data of each column is uniformly stored in the Index Region of the Segment file. The data here is loaded according to the column granularity, so it is stored separately from the column data information. Here we take the Short Key Index prefix index as an example.
Short Key Index prefix index is an index method based on Key (AGGREGATE KEY, UNIQ KEY and DUPLICATE KEY) sorting to quickly query data based on a given prefix column. The Short Key Index index here also adopts a sparse index structure. During the data writing process, an index item will be generated every certain number of rows. This number of rows is the index granularity, which defaults to 1024 rows and is configurable. The process is shown below:
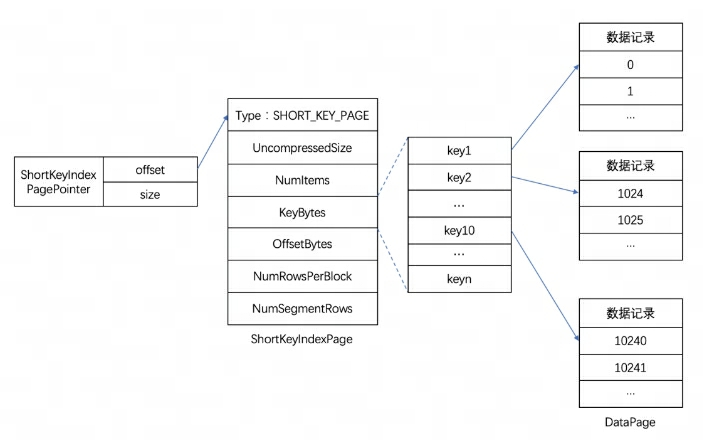
Among them, KeyBytes stores the index item data, and OffsetBytes stores the offset of the index item in KeyBytes.
Short Key Index uses the first 36 bytes as the prefix index of this row of data. When a VARCHAR type is encountered, the prefix index is truncated directly. Short Key Index uses the first 36 bytes as the prefix index of this row of data. When a VARCHAR type is encountered, the prefix index is truncated directly.
How does the reading process hit the index?
When querying the data in a Segment, according to the executed query conditions, the data will first be filtered based on the field index. Then read the data, the overall query process is as follows:
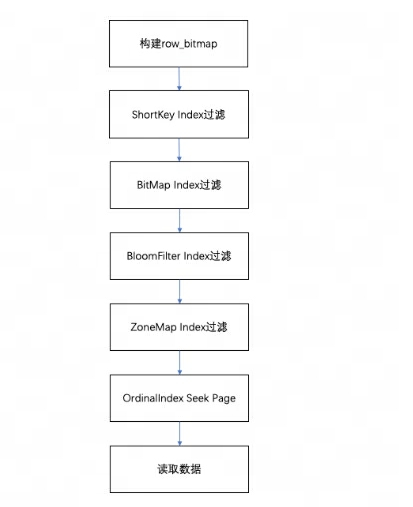
-
First, one will be constructed according to the number of rows in the Segment
row_bitmapto indicate which data needs to be read. All data needs to be read without using any index. -
When the Key is used in the query conditions according to the prefix index rule, the ShortKey Index will be filtered first, and the Oordinal row number range that can be matched in the ShortKey Index will be combined into
row_bitmap. -
When there is a BitMap Index index in the column field in the query condition, the Ordinal row number that meets the conditions will be directly found out according to the BitMap index, and intersected with the row_bitmap for filtering. The filtering here is precise. If the query condition is removed later, this field will not be filtered for subsequent indexes.
-
When the column field in the query condition has a BloomFilter index and the condition is equivalent (eq, in, is), it will be filtered according to the BloomFilter index. Here, all indexes will be walked through, the BloomFilter of each Page will be filtered, and the query conditions can be found. All Pages.
row_bitmapFilter the intersection of the Ordinal row number range in the index information and . -
When there is a ZoneMap index in the column field in the query condition, it will be filtered according to the ZoneMap index. Here, all indexes will also be run through to find all pages that the query condition can intersect with the ZoneMap.
row_bitmapFilter the intersection of the Ordinal row number range in the index information and . -
After generating
row_bitmap, find the specific Data Page through the OrdinalIndex of each Column in batches. -
Read the Column Data Page data of each column in batches. When reading, for Pages with Null values, determine whether the current row is Null based on the Null value bitmap. If it is Null, fill it directly.
Q7: How does Doris perform Compaction?
Doris uses Compaction to incrementally aggregate RowSet files to improve performance. The version information of RowSet is designed with two fields, Start and End, to represent the version range of the merged Rowset. The versions Start and End of an unmerged Cumulative RowSet are equal. During Compaction, adjacent RowSets will be merged to generate a new RowSet, and the Start and End of the version information will also be merged to form a larger version. On the other hand, the Compaction process greatly reduces the number of RowSet files and improves query efficiency.
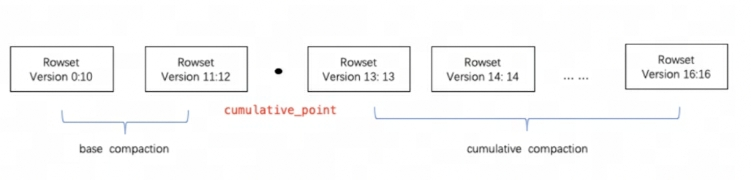
As shown in the figure above, Compaction tasks are divided into two types, Base Compaction and Cumulative Compaction. cumulative_pointIt is the key to separate the two strategies.
It can be understood like this:
-
cumulative_pointOn the right is an incremental RowSet that has never been merged, and the Start and End versions of each RowSet are equal; -
cumulative_pointOn the left is the merged RowSet, the Start version and the End version are different. -
The task processes of Base Compaction and Cumulative Compaction are basically the same. The only difference lies in the logic of selecting the InputRowSet to be merged.
What Key is Compaction based on?
-
In a Segment, data is always stored in the sorting order of Key (AGGREGATE KEY, UNIQ KEY and DUPLICATE KEY). That is, the sorting of Key determines the physical structure of data storage and determines the physical structure order of column data.
-
So the Doris Compaction process is based on AGGREGATE KEY, UNIQ KEY and DUPLICATE KEY.
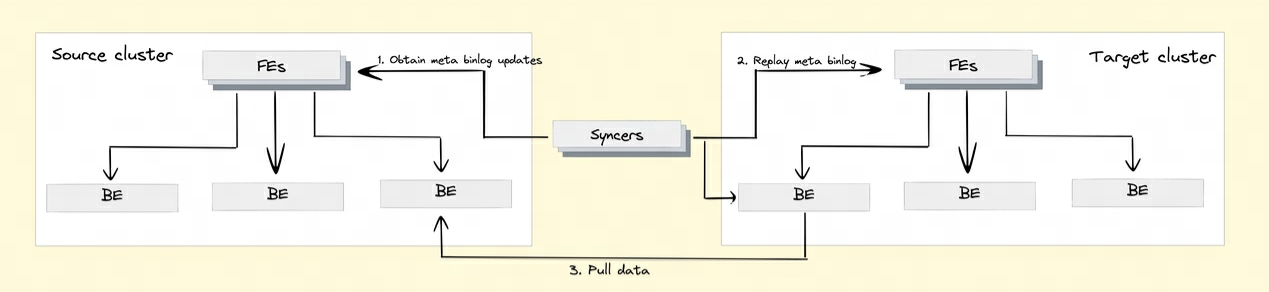
Q8: How does Doris implement cross-cluster data replication?
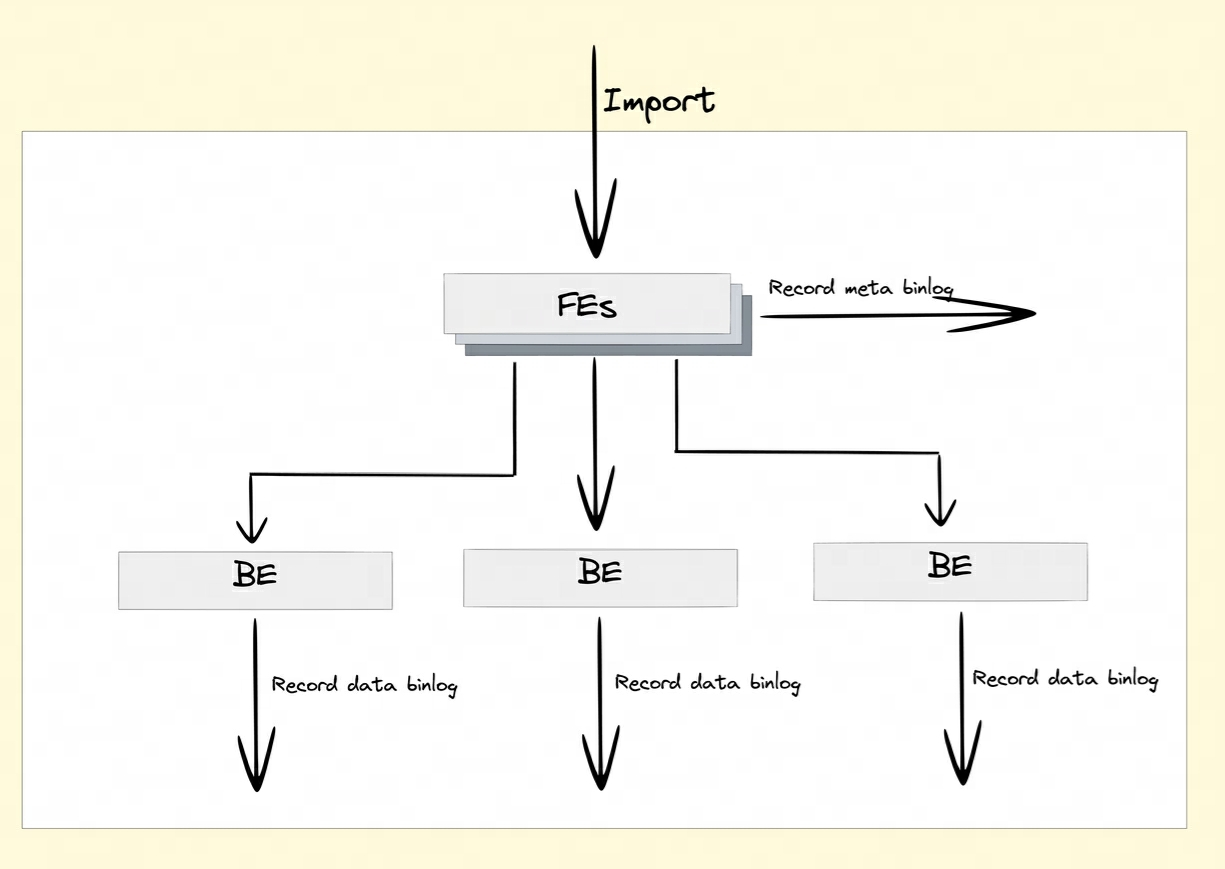
In order to realize the cross-cluster data replication function, Doris introduced the Binlog mechanism. Data modification records and operations are automatically recorded through the Binlog mechanism to achieve data traceability. Data replay and recovery can also be achieved based on the Binlog playback mechanism.
How is Binlog recorded?
After turning on the Binlog attribute, FE and BE will persist the modification records of DDL/DML operations into Meta Binlog and Data Binlog.
-
Meta Binlog: Doris has enhanced the implementation of EditLog to ensure the orderliness of the log. By constructing an increasing sequence of LogIDs, each operation is accurately recorded and persisted in order. This ordered persistence mechanism helps ensure data consistency.
-
Data Binlog: When FE initiates a Publish Transaction, BE will perform the corresponding Publish operation. BE will write the metadata information of this Transaction involving RowSet into the KV prefixed
rowset_metawith and persist it to the Meta storage. After submission The imported Segment Files will be linked to the Binlog folder.
Binlog generation:
BInlog data playback:
Q9: Doris's table has multiple copies. How to ensure multiple copies during the writing phase? Is there a master-slave concept? Is it necessary to return the write success after Majority?
-
The 3 copies of Doris BE do not have the concept of master-slave and use the Quorum algorithm to ensure multi-copy writing.
-
During the writing process, FE will determine whether the number of copies of each tablet that successfully writes data exceeds half of the total number of tablet copies. If the number of copies of each tablet that successfully writes data exceeds half of the total number of tablet copies (most success) , then the Commit Transaction is successful and the transaction status is set to COMMITTED; the COMMITTED status indicates that the data has been successfully written, but the data is not yet visible, and the Publish Version task needs to be continued. After that, the transaction cannot be rolled back.
-
FE will have a separate thread to execute Publish Version for the successful Commit Transaction. When FE executes Publish Version, it will send Publish Version requests to all Executor BE nodes related to the Transaction through Thrift RPC. The Publish Version task is executed asynchronously on each Executor BE node. Import the data into the generated RowSet and make it a visible data version.
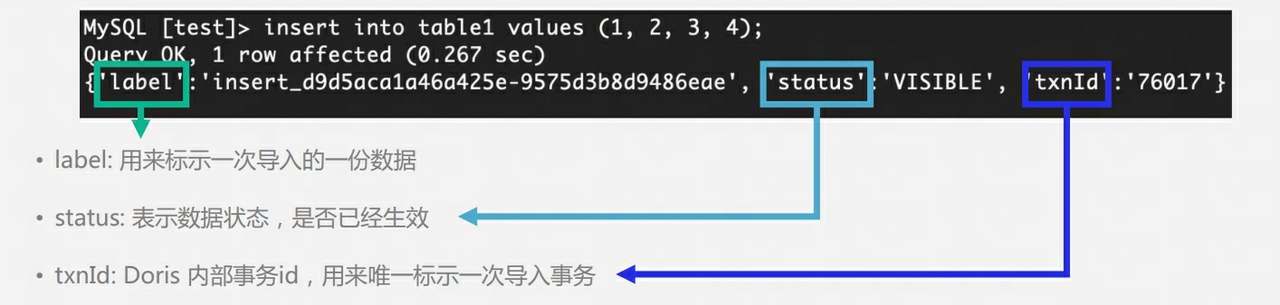
Why is there a Publish mechanism : Similar to MVCC, if there is no Publish mechanism, users may read data that has not yet been submitted.
What will happen if the table has 3 copies and only 1 copy is successfully written : At this time, the transaction will be ABORTED
What will happen if the table has 3 copies and only 2 copies are successfully written : At this time, the transaction will be COMMITTED, and Doris FE will regularly perform tablet monitoring and inspections. If an abnormality in the tablet copy is found, a Clone task will be generated to Clone a new copy.
Why does the user execute the query immediately after executing Insert Into, and the result may be empty ? The reason is that the transaction has not yet been Published.
Q10: How does Doris' FE ensure high availability?
At the metadata level, Doris uses the Paxos protocol and the Memory + Checkpoint + Journal mechanism to ensure high performance and high reliability of metadata.
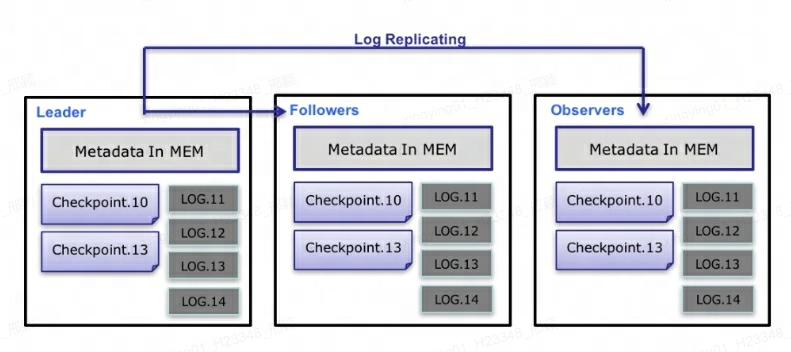
The specific process of metadata data flow is as follows :
-
Only Leader FE can write metadata. After the write operation modifies the Leader's memory, it will be serialized into a Log and
key-valuewritten to BDBJE in the form of . The Key is a continuous integer, andlog idthe Value is the serialized operation log. -
After the log is written to BDBJE, BDBJE will copy the log to other Non-Leader FE nodes according to the policy (write majority/all write). The Non-Leader FE node modifies its own metadata memory image by replaying logs to complete metadata synchronization with the Leader node.
-
The number of logs on the Leader node reaches the threshold (100,000 by default) and meets the Checkpoint thread execution cycle (60 seconds by default). Checkpoint will read the existing Image file and subsequent logs, and replay a new metadata image copy in the memory. The copy is then written to disk to form a new Image. The reason for regenerating a copy of the image instead of writing the existing image as an Image is mainly because writing to the Image and adding a read lock will block the write operation. Therefore, each Checkpoint will occupy double the memory space.
-
After the Image file is generated, the Leader node will notify other Non-Leader nodes that the new Image has been generated. Non-Leader actively pulls the latest Image file through HTTP to replace the old local file.
-
For logs in BDBJE, old logs will be deleted regularly after Image is completed.
explain :
-
Each update of metadata is first written to the log file on the disk, then written to the memory, and finally periodically Checkpointed to the local disk.
-
It is equivalent to a pure memory structure, which means that all metadata will be cached in memory, thus ensuring that FE can quickly restore metadata after a crash without losing metadata.
-
The three of Leader, Follower and Observer constitute a reliable service. When a single node fails, three are basically enough, because after all, the FE node only stores one copy of metadata, and its pressure is not great, so if When there are too many FEs, it will consume machine resources, so in most cases three is enough to achieve a highly available metadata service.
-
Users can use MySQL to connect to any FE node for read and write access to metadata. If the connection is to a Non-Leader node, the node will forward the write operation to the Leader node.
about the author
Invisible (Xing Ying) is a senior database kernel engineer at NetEase. She has been engaged in database kernel development since graduation. She is currently mainly involved in the development, maintenance and business support of MySQL and Apache Doris. As a MySQL kernel contributor, he reported more than 50 bugs and optimization items for MySQL, and multiple submissions were incorporated into MySQL 8.0 version. Joining the Apache Doris community since 2023, Apache Doris Active Contributor, has submitted and merged dozens of Commits for the community.
A middle school purchased an "intelligent interactive catharsis device" - which is actually a case for Nintendo Wii. TIOBE 2023 Programming Language of the Year: C# Kingsoft WPS crashed Linux's Rust experiment was successful, can Firefox seize the opportunity... 10 predictions about open source Follow-up to the incident of female executives firing employees: The company chairman called employees "repeat offenders" and questioned "false academic resumes". The open source artifact LSPosed announced that it would stop updating. The author said it suffered a large number of malicious attacks. 2024 "The Battle of the Year" in the front-end circle: React can't dig holes. Do you need to fill it in with documents? Linux Kernel 6.7 is officially released. The "post-open source" era is here: the license is invalid and cannot serve the general public. Female executives were illegally fired. Employees spoke out and were targeted for opposing the use of pirated EDA tools to design chips.