Export the xm.xlsx file and simply operate it into xmA.xls

Split into a format suitable for import such as:

Next is the code to operate:
import xlrd # pip install xlrd==1.2.0 高版不支持xlsx
import xlwt
workbook = xlrd.open_workbook('xmA.xlsx') # 文件名要用英语,要不然会出错
print(workbook.sheet_names())
sheet = workbook.sheet_by_index(0)
print(sheet)
rows = [sheet.row_values(row, 0, 7) for row in range(sheet.nrows)]
good_lists = {}
for r in rows:
if r[4] not in good_lists: # r[4]第5列 单号
good_lists[r[4]] = []
print(good_lists)
good_lists[r[4]].append(r)
for (good, lst) in good_lists.items():
wb = xlwt.Workbook()
ws = wb.add_sheet('Sheet1')
ws.write(0, 0, '货品代码')
ws.write(0, 1, '品名规格(必填)')
ws.write(0, 2, '数量')
ws.write(0, 3, '原价') # 注意 单价不能为0
mz = [i[5] for i in lst] # 读取lst数据 取出 名称
c = mz[0]
ru = [i[3] for i in lst] # 读取lst数据 取出 日期
d = ru[0]
print(c)
print(d)
row_idx = 1
for new_r in lst:
col_idx = 1 # 这不选0 而选1 是为了第一列为空白
for v in new_r:
ws.write(row_idx, col_idx, v)
col_idx = col_idx + 1
row_idx = row_idx + 1
wb.save('./'+good+c+d+'.xlsx') # good 是单号 c 是名称 d 是日期Generate the file after running run.py:

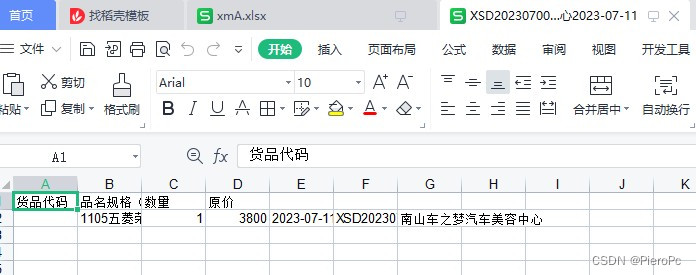
Then manually import the software (automatic still needs to be studied...)