What is a semi-Markov decision process?
To understand what Semi-MDP (SMDP) is, we need to review the Markov Decision Process (MDP) first. Because MDP is actually a special case of SMDP. (The only difference is: the state transition probability matrix P, everything else is the same. In order to draw a parallel, I will take you to review MDP first)
I believe everyone is familiar with MDP. After all, for people like us who are engaged in reinforcement learning (RL), MDP and RL are like water to fish and sky to birds. After all, MDP is the mathematics of RL. Theoretical support.
Looking back at the knowledge points from many years ago——MDP
Markov Decision Process MDP is originally a very simple concept. It sounds quite advanced, complex, and pretentious, but in fact it is very simple. When there are too many formulas and symbols in an article, I will feel sleepy when I read the article. I have personally experienced this kind of torture, so this article strives to be concise and clear!
The causes and consequences of Markovianity
A long time ago, the term "Markov decision process" did not appear on the earth. And in our real world, people have long discovered that the environment transformation in the real world, the probability of transformation to the next state s′ is not only related to the previous state s, but also to the previous state, and the previous state. This will cause our environment transformation model to be very complex, so complex that it is difficult to model. Therefore, we need to simplify the environment transformation model, that is, we stubbornly believe that the state has Markov properties (Markov properties: the state S' at the next moment is only affected by the current state S, and has nothing to do with all previous states).
The differences and connections between MP, MRP and MDP
- It can be represented by a tuple <S, P>, where S is the state (set), P is the state transition probability matrix, and the state S has Markov properties. This binary group is the Markov process (MP), which is a memoryless random process.
- On the basis of the Markov process, the reward function R and the attenuation coefficient γ are added to form a four-tuple <S, R, P, γ>, which is called the Markov reward process (MRP).
- Adding the Decision process to the Markov reward process means adding an action set A, which is the Markov decision process (MDP).
Semi-Markov decision process——SMDP
There are two types of Markov decision processes (MDP), including discrete-time MDP and continuous-time MDP. The time and state of discrete-time MDP are both discrete, and the state transition relies on a 1-step transition matrix; the difference between continuous-time MDP and discrete-time MDP is that the moment when the state changes is any time and is a continuous value, and adjacent The residence time of the state obeys the exponential distribution, and the exponential distribution has a characteristic-no memory.
In mathematics, the exponential distribution is the only memoryless continuous distribution, and the geometric distribution is the only memoryless discrete distribution. The continuous form of geometric distribution is exponential distribution.
You may ask: What is memorylessness?
Xiao Ming is waiting hard for the first customer to come to his store. He has been waiting for three hours. Xiao Ming wants to go to the toilet, but he can only hold it in because he thinks that after waiting for so long, the probability of customers coming will increase with time. It will continue to improve as time goes by, so be sure to wait until you have guests before going to the toilet. This event can be regarded as an exponential distribution. Since the exponential distribution has no memory, the first three hours of waiting are sunk costs and will not affect the probability of subsequent visitors. Xiao Ming went to the toilet when he needed to. Waiting for three hours had nothing to do with increasing the visitor rate. This is memorylessness.
The difference and connection between SMDP and MDP
SMDP is continuous time, it still has Markov properties, and the residence time of its adjacent states obeys random distribution, not exponential distribution. In other words, the situation considered by MDP is simple, and the residence time of adjacent states obeys an exponential distribution, so the transition probability is time constant and memoryless, which limits the practical application of MDP. To overcome the limitations of MDP, SMDP has more general probability distributions and time-varying transition rates, and therefore has wider practical applications . For example, the transition of a single node's working state in the network is a random process, that is, the transition between working states is not an equiprobable event, and the corresponding transition rate is time-varying. For this kind of practical problem, we have no way to treat it as an MDP. We must use SMDP to model it.
Although the transition probability of the state transition matrix P of SMDP is time-varying, it can still be written as an optimal value function similar to MDP:
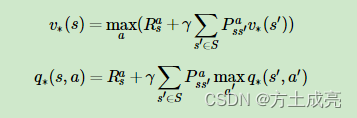
Regarding the application of reinforcement learning algorithms in solving the Bellman equation of SMDP, there are currently:
RVI Q-learning, R-learning, and GR-learning can iteratively solve the Bellman equation of SMDP.
Just a quick aside:
You may have heard of Q-Learning, but have you ever heard of another algorithm that fell from the sky——
R-Learning! ! ! !
The R-Learning algorithm is a generalization of Q-Learning. We know that the maximum reward function in the Q-Learning algorithm has an attenuation factor γ, and the R-Learning algorithm can also make the cumulative Maximize returns.
references:
1. A Zhihu article (no memory)
2. Another Zhihu article
3.Schwartz A. A reinforcement learning method for maximizing undiscounted rewards[C]//Proceedings of the tenth international conference on machine learning. 1993, 298: 298-305.
4.Singh, SP: Reinforcement learning algorithms for average-payoff Markovian decision processes. In: AAAI Conference on Artificial Intelligence, pp. 700–705 (1994)
5.Yang, J., Li, Y. , Chen, H., Li, J. (2017). Average Reward Reinforcement Learning for Semi-Markov Decision Processes.