Table of Contents of Series Articles
Paper : Instance-aware Multi-Camera 3D Object Detection with Structural Priors Mining and Self-Boosting Learning
Address : https://arxiv.org/pdf/2312.08004.pdf
Source : Fudan University Intel Shanghai Key Lab/Meituan
Article directory
Summary
Multi-camera three-dimensional target detection is an important research direction in the field of autonomous driving. A common method is to convert multi-view image features into a unified bird's-eye view (BEV) space for perception . We propose an instance-aware bird's-eye view detector (IA-BEV), which introduces instance-aware information on the image plane during the depth estimation process. On the nuScenes dataset, the method achieves state-of-the-art results using two keyframes
I. Introduction
In recent years, multi-camera 3D target detection has received widespread attention in the field of autonomous driving. Compared with lidar, its camera can better capture the semantic information of objects and has a lower cost advantage. The latest trend in this field is to convert multi-view image features into a unified BEV space for subsequent perception tasks . This representation facilitates alignment of signals from multiple sensors and timestamps in BEV space, thereby providing a common representation for downstream tasks such as detection, map segmentation, and motion planning.
In the BEV-based perception process, depth estimation is a key link in the perspective projection from the image view to the BEV . Early methods implicitly or explicitly estimated depth from monocular images. Inspired by multi-view stereo matching technology, subsequent methods use continuous camera frames to construct a cost volume for stereo matching . Due to the improved depth estimation, these methods obtain high-quality BEV features, thus significantly improving detection performance.
Despite significant progress, existing methods ignore inherent properties in foreground objects because they treat every pixel as equally important. In fact, foreground objects can exhibit intra-class consistency and inter-instance variability , which we believe can be used to improve depth estimation. On the one hand, objects of the same semantic category have similar structural priors , which is reflected in two points:
1) The scale of objects in the image has a certain correlation with its true depth . This correlation is usually consistent for objects of the same semantic category, but different for objects of different categories. For example, the scale of a car in an image is inversely proportional to its true depth, but even at the same depth, there are significant differences in the scale of cars and pedestrians.
2) Objects in the same semantic category have consistent internal geometric structures . As shown in Figure 1(b), objects of the same category (cars) have similar relative depth distributions when viewed separately from the image plane.
On the other hand, for different instance objects, even in the same category, their visual appearance is greatly different due to different resolutions and occlusion states . Therefore, the depth estimation difficulty for different instance objects is also different. As shown in Figure 1, the car image on the left contains more texture and shape details, which reduces the uncertainty of the depth estimation. Although some methods explore 2D object priors for 3D object detection, they mainly utilize the detected 2D objects after perspective projection, thus ignoring their potential to improve depth estimation to enhance BEV feature construction.

2. Propose solutions
Based on the above observations, a depth estimation algorithm based on BEV detector using 2D instance perception enhancement , namely IA-BEV, is proposed . As shown in Figure 1(d), our IA-BEV first decomposes the scene into individual objects, and then exploits the inherent properties of these objects to effectively assist monocular and stereo depth estimation through two novel modules:
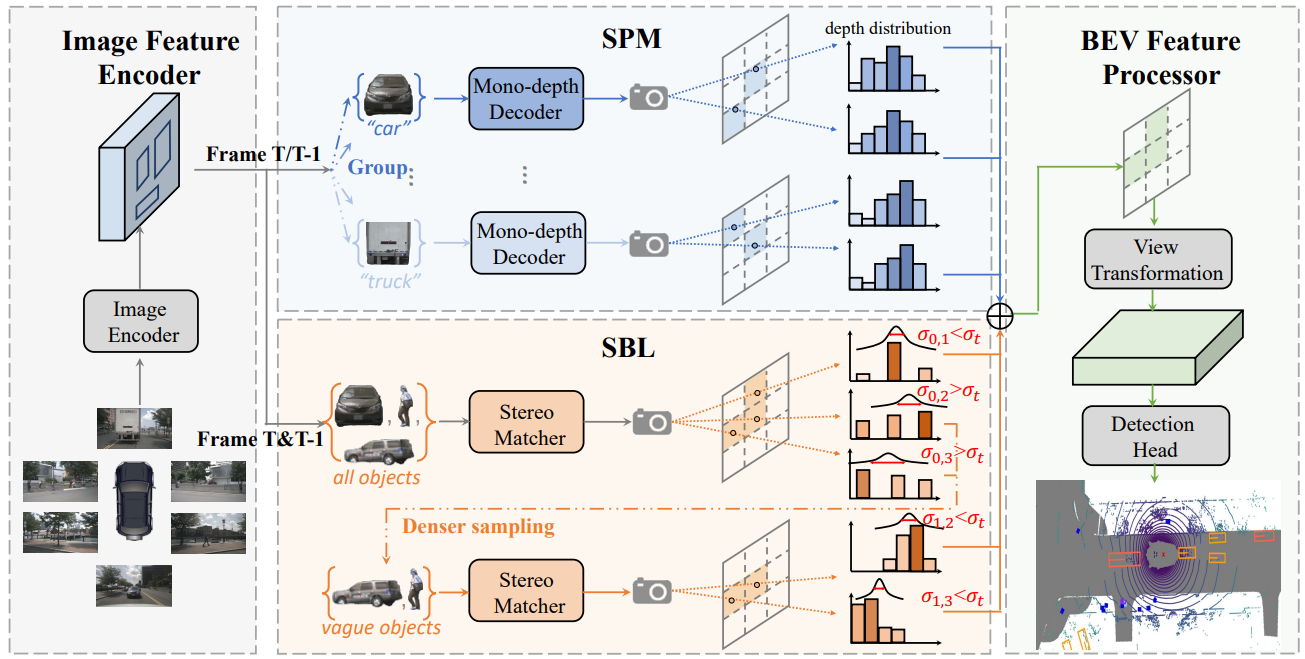
Figure 2 | Detailed design of our proposed method. Given images collected from multi-view cameras, we first parse foreground objects using an off-the-shelf 2D scene parser. Then, these objects and their image features are input into our proposed SPM and SBL in parallel to perform efficient depth estimation by exploring object properties from both category and instance perspectives. Finally, the outputs of SPM and SBL are combined to obtain the final image depth and used for conventional view transformation and BEV-based detection. T frames and T-1 frames are input into SPM separately, and they are input into SBL at the same time, because the stereo matching here requires multi-frame temporal information.
The first module is category-based structural prior mining (SPM) , which groups objects belonging to the same or similar semantic categories to be processed by respective lightweight deep decoders to better exploit structural priors. However, it is very difficult to expect these parallel decoders to actively learn category-specific patterns simply by grouping inputs, resulting in poor performance. To address this issue, we explicitly encode object scale attributes as additional inputs and apply two instance-based loss functions to supervise coarse instance absolute depth and fine-grained internal object relative depth predictions.
The second module is self-reinforcement learning (SBL) , which operates in a category-agnostic manner and focuses on iteratively distinguishing and reinforcing harder objects . At each iteration, the objects are first divided into two groups based on the uncertainty of the stereo matching. Then, groups with higher uncertainty (indicating inaccurate estimates) are further reinforced in subsequent iterations. As the foreground regions that need to be processed gradually become sparser in later iterations, we can set denser depth hypotheses for selected challenging samples within the uncertainty range to perform more comprehensive stereo matching on them. Finally, based on the combined depth estimation of SPM and SBL, a conventional view transformation process is performed to construct BEV features for final detection.
3. Main methods
IA-BEV contains four key components: the feature encoder , which is responsible for extracting image features and parsing foreground objects; the structure prior mining method (SPM) , which enhances monocular depth estimation by exploiting the structural consistency of objects of the same category; self-augmentation Learning strategy (SBL) , which enhances blurred objects in stereo depth estimation; BEV feature encoder , which is used to render features and detect objects in BEV space.
3.1 Feature Encoder
For images collected by multi-view cameras, image features are extracted using a backbone network (such as ResNet-50 or ConvNeXt) . At the same time, we use a mature instance segmenter to parse the foreground objects , here we retain the features of all pixels of the object instead of aggregating into a vector, since our goal is to densely predict depth for the entire object region . SPM and SBL are then used to exploit the potential of the object's inherent properties in depth estimation .
3.2 Structural prior mining
01. Category-based deep decoder
Estimating depth from monocular images is challenging as it requires understanding the relationship between different semantic object scales and depth values. Existing BEV-based methods adopt the popular image backbone network as a feature encoder to give the model powerful semantic capture capabilities, but they rely on a single depth decoder to learn scale-to-depth mapping patterns for multiple semantic categories simultaneously, increasing the optimization requirements. burden .
In order to simplify the learning process of different semantic categories, multiple parallel lightweight deep decoders are designed , where each decoder is responsible for processing objects belonging to the same category, as shown in Figure 2. Specifically, we first divide all foreground objects into several non-overlapping semantic groups. Then, taking the object features extracted from the semantic group, we simultaneously input the object features and box parameters (i.e., normalized box height and width) into the lightweight deep decoder . In each depth decoder, the box parameters are encoded through linear mapping and then fused with object features using SE modules. Finally, the output will be predicted by the convolutional layer to predict the depth of the current object region. Finally, by merging the predicted depths of all instances, a monocular estimated depth is obtained.
02. Example-based supervision
In a typical BEV-based perception pipeline, depth prediction is supervised by pixel-level cross-entropy loss, which cannot capture fine-grained instance-level cues, thereby increasing the difficulty of learning semantic structure priors for the above-mentioned category-specific depth decoders . Therefore, we design two new loss functions to encourage learning of coarse instance absolute depth and fine intra-instance relative depth . First, we convert the discrete depth predictions of the object into continuous depth values. We then project the lidar points onto the image plane to obtain GroundTruth depth and retain those parts that intersect with foreground objects to construct the supervision signal .
At this point, we have both the predicted value and the GroundTruth depth value. To explicitly supervise instance-level depth prediction, for each object, we extract an absolute depth value Dgt as the regression target . It is worth noting that there are some outliers in the GroundTruth depth due to sensor errors , which brings great challenges to our supervised model. Therefore, we first scatter all depth values into predefined depth bins, and then average only the values in the depth bin with the largest number of votes as the absolute depth loss d gt . Additionally, we compute a relative depth loss to encourage specific decoders to learn fine-grained object geometry patterns .
3.3 Self-Boosting learning
Time-based stereo matching techniques rely on geometric consistency in the time dimension for depth estimation . Specifically, for each pixel in T frames, we initially propose several depth hypotheses along the depth channel. These hypotheses are then projected into the (T-1) frame via a homography transformation between the T frame and the (T-1) frame to construct the cost volume and learn the best match between them. In the above process, the main obstacle is the huge memory overhead of constructing a three-dimensional cost volume for a large number of pixels in high-resolution image features and dense hypotheses. However, in our scenario, image regions should not be treated equally.
First, foreground objects are more important than background areas. Second, depth estimation for objects with lower visual clarity is more challenging and should be given more attention. Therefore, we design a self-reinforcement strategy that iteratively focuses on more difficult object regions, which further allows the granularity of cost volume construction to be adaptively adjusted according to different regions, thereby achieving a better trade-off between cost and effect.
01. Sparse Cost Volume construction
To improve efficiency, we mainly focus on exploring the stereo matching behavior of foreground objects in T frames, which breaks the traditional dense Cost Volume construction paradigm. Therefore, we rewrite such a procedure into the sparse format introduced below. We transform it using the homography transformation between the T frame and the (T-1) frame to obtain the corresponding projection position. For each pixel of different depth hypotheses, we establish its corresponding in the (T-1) frame. pixels and then combine their features to generate a sparse Cost Volume. Subsequently, the matching score is calculated using three-dimensional sparse convolution.
Taking the coordinates (u, u) and the corresponding depth hypothesis d h as an example, homography warping between the T frame and the T-1 frame is used to obtain the corresponding projection:
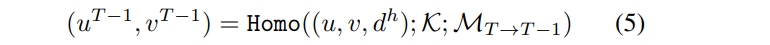
where K is the intrinsic parameter of the camera, M T→ T-1 is the transformation matrix from T to T-1 frame. According to the above process, for each target pixel with different depth assumptions, we establish its correspondence with the (T-1) frame pixel, and then combine it with the features to generate a sparse generation Cost Volume 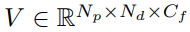
, where N p and N d are the foreground respectively. The number of pixels and the number of depth hypotheses, C f is the feature channel dimension. Subsequently, the matching score is calculated using 3D sparse convolution.
02. Iterative stereo matching
In the first round, to effectively identify visually detail-rich objects, we uniformly sample the sparse depth hypothesis for all pixels in foreground objects. Then construct a sparse Cost Volume and calculate the matching score. We calculate the mean and standard deviation along the pixel depth channel. When the mean and standard deviation are small, the depth hypothesis has been successfully verified to find the best match. On the contrary, larger means and standard deviations mean that multiple deep hypotheses are prioritized and therefore should be further enhanced. Therefore, we consider pixels with matching score standard deviation less than a predefined threshold as satisfactory results and filter them in the next iteration. For the remaining pixels, their mean and standard deviation can provide a more accurate search range, which helps to propose depth hypotheses more effectively for the next iteration. Based on the mean and standard deviation, we update the depth sampling range for the next iteration.
We further sample multiple depth hypotheses uniformly for the remaining pixels. The depth hypothesis will be used in the next iteration to construct the sparse Cost Volume and similarly calculate the mean and standard deviation. Since the number of depth hypotheses is different in different iterations, we use interpolation operations to fill all predefined depth bins for alignment. As shown in Figure 4, the proposed self-reinforcement learning strategy can distinguish mainly clear object regions in early iterations, thereby saving resources to strengthen blurry objects.
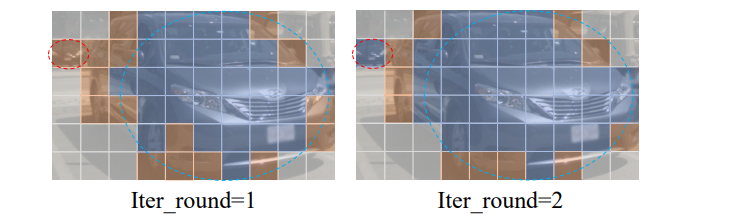
Visualization of filtered and remaining patches in SBL. Gray patches represent background areas, blue and orange patches represent filtered patches and remaining patches, respectively. We use red and blue dashed circles to highlight blurry and clear objects respectively
3.4 BEV feature processor
By summing the monocular and stereo depth predictions from SPM and SBL, the final depth prediction for rendering BEV features from multi-camera images can be obtained. Afterwards, the BEV features will be input to a conventional inspection head for final 3D inspection.
4. Experimental results
The method conducted a large number of experiments on the nuScenes data set, and compared with the state-of-the-art methods (validation set and test set):
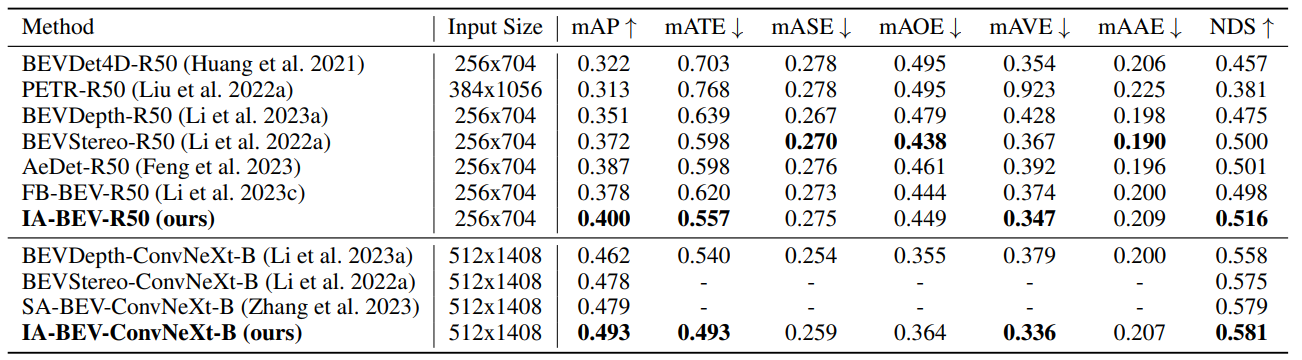
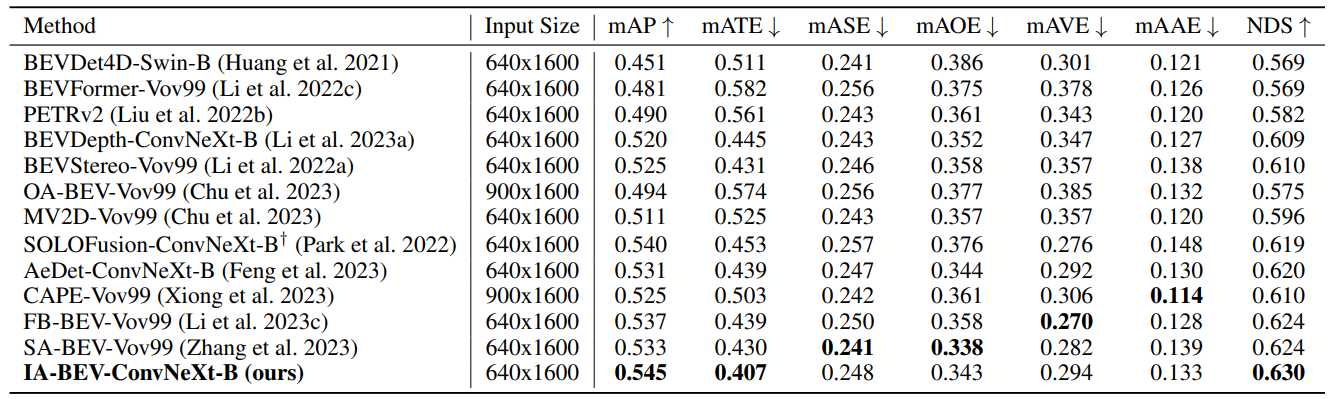
Qualitative results comparison between baseline method and IA-BEV:

Summarize
提示:这里对文章进行总结:
d \sqrt{d}d 1 0.24 \frac {1}{0.24} 0.241 x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ϵ \epsilonϵ