linear regression
Data sets and source files can be obtained in the Github project
Address: https://github.com/Raymond-Yang-2001/AndrewNg-Machine-Learing-Homework
1. Univariate linear regression
Univariate linear regression finds a one-dimensional equation and fits a straight line.
Univariate linear regression formula
h w , b ( x ) = b + w x h_{w,b}(x)=b+wx hw,b(x)=b+wx
w w w andbbb is a parameter. To facilitate calculation, you can givexxx plus anx 0 = 1 x_0=1x0=1
h w , b ( x ) = b x 0 + w x 1 h_{w,b}(x)=bx_{0}+wx_{1} hw,b(x)=bx0+wx1
loss function
J ( w , b ) = 1 2 m ∑ i = 1 m ( h w , b ( x ( i ) ) − y ( i ) ) 2 J(w,b)=\frac{1}{2m}\sum_{i=1}^{m}(h_{w,b}(x^{(i)})-y^{(i)})^{2} J(w,b)=2m _1i=1∑m(hw,b(x(i))−y(i))2
In order to avoid excessive or small losses caused by inappropriate data ranges (for example, if the data value is too large, the loss may be1 0 5 10^5105 or1 0 6 10^6106 , this order of magnitude is not suitable for intuitive analysis) When evaluating the loss, you can hw, b (x (i)) h_{w,b}(x^{(i)})hw,b(x( i ) )sumy( i ) y^{(i)}y( i ) First standardize so that the loss value is within an evaluable range. But this is not done when doing gradient descent
Optimization Algorithm—Batch Gradient Descent (BGD)
w j = w j − α ∂ ∂ w j J ( w , b ) = w j − α 1 m ∑ i = 1 m ( h w , b ( x ( i ) ) − y ( i ) ) x ( i ) w_j=w_{j}-\alpha\frac{\partial}{\partial{w_j}}{J(w,b)}=w_{j}-\alpha \frac{1}{m}\sum_{i=1}^{m}{(h_{w,b}(x^{(i)})-y^{(i)})x^{(i)}} wj=wj−a∂wj∂J(w,b)=wj−am1i=1∑m(hw,b(x(i))−y(i))x(i)
b j = b j − α ∂ ∂ b j J ( w , b ) = w j − α 1 m ∑ i = 1 m ( h w , b ( x ( i ) ) − y ( i ) ) b_j=b_{j}-\alpha\frac{\partial}{\partial{b_j}}{J(w,b)}=w_{j}-\alpha \frac{1}{m}\sum_{i=1}^{m}{(h_{w,b}(x^{(i)})-y^{(i)})} bj=bj−a∂bj∂J(w,b)=wj−am1i=1∑m(hw,b(x(i))−y( i ) )
Here, we can useθ \thetaθ unified identification parameters, includingwww andbbb。
That is, jjthj parametersθ j \theta_jijDetermine the following:
θ j = θ j − α ∂ ∂ wj J ( θ ; x ) = wj − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x ( i ) \theta_{j}=\theta_{j}-\alpha\frac{\partial}{\partial{w_j}}{J(\theta;\mathbf{x})}=w_{j}-\alpha \frac{1}{m}\sum_{i=1^{m}{(h_{\theta}(x^{(i)})-y^{(i)})x^{(i) }}ij=ij−a∂wj∂J(θ;x)=wj−am1i=1∑m(hi(x(i))−y(i))x( i )
whereα \alphaα is the learning rate.
2. Multivariable linear regression
Multivariable linear regression attempts to find the relationship between multiple variables and predicted values. For example, the relationship between house size, number of bedrooms in a house, and house prices.
Feature scaling (normalization)
When the numerical differences between different features of the sample are too large, gradient-based optimization methods will have some problems. For example, there is the following regression equation:
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 h_{\theta}(x)=\theta_{0}+\theta_{1}x_{1}+\ theta_{2}x_{2}hi(x)=i0+i1x1+i2x2
Assume x 2 x_{2}x2The range is 0 ∼ 1 0\sim10∼1, x 1 x_1 x1The range is 1 0 3 ∼ 1 0 4 10^3\sim10^4103∼104 . We simultaneously optimizeθ 0 ∼ θ 2 \theta_0\sim\theta_2i0∼i2, so that they all change by the same size, then obviously when the input samples are the same, θ 1 \theta_1i1The change will be greater than θ 2 \theta_2i2changes that lead to greater output. This can also be understood as the model pair θ 1 \theta_1i1More sensitive. As shown in the following loss isoline diagram, θ 1 \theta_1i1Small changes can bring drastic changes in losses. In this case, parameter optimization will be more difficult.
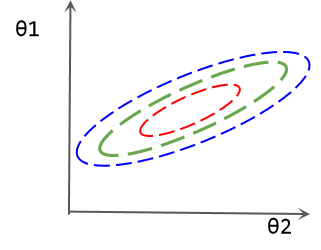
One way to solve this problem is feature scaling, which scales two features to the same range. For example, z-score normalization can be performed:
xnew = x − μ σ x_{new} = \frac{x-\mu}{\sigma}xnew=px−m
Among them, μ \muμ is the mean of the data set,σ \sigmaσ is the standard deviation, and the distribution of new data is a distribution with mean 0 and standard deviation 1.
The parameter loss diagram after data normalization is as follows:
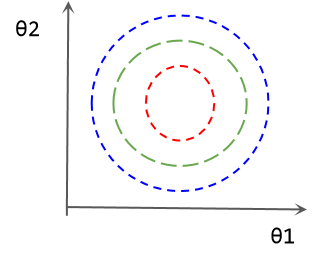
Inverse scaling of parameters
Since the data is scaled, the final parameters will also be scaled accordingly. The specific relationship is as follows:
θ 0 + θ 1 ∼ d + 1 x 1 ∼ d + 1 − μ x σ x = y − μ y σ y \theta_{0}+\theta_{1\sim d+1}\frac {x_{1\sim d+1}-\mu_{x}}{\sigma_{x}}=\frac{y-\mu_{y}}{\sigma_{y}}i0+i1∼d+1pxx1∼d+1−mx=pyy−my
Here we are talking about yyy has also been standardized.In fact, it is not necessary to do this, and there will be no impact on performance. But the normalization of y makes the parameters smaller, and convergence can be achieved faster for parameters initialized to 0.
In standardizationyyIn this case, the inverse scaling formula of the parameters is:
θ 1 ∼ d + 1 new = θ 1 ∼ d + 1 σ x σ y \theta_{1\sim d+1}^{new}=\frac{\ theta_{1\sim d+1}}{\sigma_{x}}\sigma_{y}i1∼d+1new=pxi1∼d+1py
Formula:
θ 0 σ y + θ 1 ∼ d + 1 new ( x 1 ∼ d + 1 − μ x ) = y − μ y \theta_{0}\sigma_{y}+\theta_{1\sim d+1 }^{new}(x_{1\sim d+1}-\mu_{x})=y-\mu_{y}i0py+i1∼d+1new(x1∼d+1−mx)=y−my
θ 0 new = θ 0 σ y + μ y − θ 1 ∼ d + 1 new μ x \theta_{0}^{new}=\theta_{0}\sigma_{y}+\mu_{y}-\theta_ {1\sim+1}^{new}\mu_{x}i0new=i0py+my−i1∼d+1newmx
Among them, during vectorization operation, θ 1 ∼ d + 1 new \theta_{1\sim d+1}^{new}i1∼d+1new和μ x \mu_{x}mxThey are all vectors of (1,d), and multiplication should use vector inner product.
3. Linear regression algorithm code implementation
vector implementation
Let the data x \boldsymbol{x}The dimensions of x are(n, d) (n,d)(n,d ) , where n is the number of samples and d is the dimension of the sample features. For the convenience of calculation, we add an extra feature dimension with all values 1 to the sample, so that its dimension becomes( n , d + 1 ) (n, d+1)(n,d+1)
- Prediction
Let the parameter θ \boldsymbol{\theta}The dimension of θ is (1, d+1), thenx θ ⊤ \boldsymbol{x\theta^{\top}}xθ⊤或 ( θ x ⊤ ) ⊤ \boldsymbol{(\theta x^{\top})^{\top}} (θx⊤)⊤The dimension can be obtained as(n, 1) (n,1)(n,1 ) Prediction resulth θ ( x ) h_{\boldsymbol{\theta}}(\boldsymbol{x})hi(x)。 - Let us divide the
quantity j by the quantity:
θ j = θ j − α ∂ ∂ wj J ( θ ; x ) = wj − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x ( i ) \theta_{j}=\theta_{j}-\alpha\frac{\partial}{\partial{w_j}}{J(\theta;\mathbf{x})}=w_ {j}-\alpha\frac{1}{m}\sum_{i=1}^{m}{(h_{\theta}(x^{(i)})-y^{(i)}) x^{(i)}}ij=ij−a∂wj∂J(θ;x)=wj−am1i=1∑m(hi(x(i))−y(i))x( i )
In fact, here we putθ 0 \theta_{0}i0As a bias, its gradient should be:
∂ ∂ w 0 J ( θ ; x ) = w 0 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) \frac{\ partial}{\partial{w_0}}{J(\theta;\mathbf{x})}=w_{0}-\alpha \frac{1}{m}\sum_{i=1}^{m}{ (h_{\theta}(x^{(i)})-y^{(i)})}∂w0∂J(θ;x)=w0−am1i=1∑m(hi(x(i))−y( i ) ), since we supplement the data with feature dimensionsx 0 x_0x0, so it can be calculated using the above formula like other parameters.
Let error errorerror matrixβ \boldsymbol{\beta}β为 h θ ( x ) − x h_{\boldsymbol{\theta}}(\boldsymbol{x})-\boldsymbol{x} hi(x)−x , with dimensions( n , 1 ) (n,1)(n,1 ) , thenx ⊤ β / n \boldsymbol{x^{\top}\beta} /nx⊤ β/nis the dimension(d + 1, 1) (d+1,1)(d+1,1)的梯度矩阵。
x ⊤ β = [ x ( 1 ) x ( 2 ) ⋯ ] × [ h ( x ( 1 ) ) − y ( 1 ) h ( x ( 2 ) ) − y ( 2 ) ⋮ ] = [ ∑ i = 1 n ( h ( x ( i ) ) − y ( i ) ) x 0 ( 1 ) ∑ i = 1 n ( h ( x ( i ) ) − y ( i ) ) x 1 ( 1 ) ⋮ ] \boldsymbol{x^{\top}\beta}= \left[ \begin{matrix} x^{(1)}& x^{(2)} &\cdots \end{matrix} \right] \times \left[ \begin{matrix} h(x^{(1)})-y^{(1)}\\ h(x^{(2)})-y^{(2)}\\ \vdots \end{matrix} \right] =\left[ \begin{matrix} \sum_{i=1}^{n}{(h(x^{(i)})-y^{(i)})x_{0}^{(1)}}\\ \sum_{i=1}^{n}{(h(x^{(i)})-y^{(i)})x_{1}^{(1)}}\\ \vdots \end{matrix} \right] x⊤β=[x(1)x(2)⋯]× h(x(1))−y(1)h(x(2))−y(2)⋮ = ∑i=1n(h(x(i))−y(i))x0(1)∑i=1n(h(x(i))−y(i))x1(1)⋮
x ⊤ β / n \boldsymbol{x^{\top}\beta} /n xEach element in ⊤ β/n
Python code
import numpy as np
def square_loss(pred, target):
"""
计算平方误差
:param pred: 预测
:param target: ground truth
:return: 损失序列
"""
return np.sum(np.power((pred - target), 2))
def compute_loss(pred, target):
"""
计算归一化平均损失
:param pred: 预测
:param target: ground truth
:return: 损失
"""
pred = (pred - pred.mean(axis=0)) / pred.std(axis=0)
target = (pred - target.mean(axis=0)) / target.std(axis=0)
loss = square_loss(pred, target)
return np.sum(loss) / (2 * pred.shape[0])
class LinearRegression:
"""
线性回归类
"""
def __init__(self, x, y, val_x, val_y, epoch=100, lr=0.1):
"""
初始化
:param x: 样本, (sample_number, dimension)
:param y: 标签, (sample_numer, 1)
:param epoch: 训练迭代次数
:param lr: 学习率
"""
self.theta = None
self.loss = []
self.val_loss = []
self.n = x.shape[0]
self.d = x.shape[1]
self.epoch = epoch
self.lr = lr
t = np.ones(shape=(self.n, 1))
self.x_std = x.std(axis=0)
self.x_mean = x.mean(axis=0)
self.y_mean = y.mean(axis=0)
self.y_std = y.std(axis=0)
x_norm = (x - self.x_mean) / self.x_std
y_norm = (y - self.y_mean) / self.y_std
self.y = y_norm
self.x = np.concatenate((t, x_norm), axis=1)
self.val_x = val_x
self.val_y = val_y
def init_theta(self):
"""
初始化参数
:return: theta (1, d+1)
"""
self.theta = np.zeros(shape=(1, self.d + 1))
def validation(self, x, y):
x = (x - x.mean(axis=0)) / x.std(axis=0)
y = (y - y.mean(axis=0)) / y.std(axis=0)
outputs = self.predict(x)
curr_loss = square_loss(outputs, y) / (2 * y.shape[0])
return curr_loss
def gradient_decent(self, pred):
"""
实现梯度下降求解
"""
# error (n,1)
error = pred - self.y
# gradient (d+1, 1)
gradient = np.matmul(self.x.T, error)
# gradient (1,d+1)
gradient = gradient.T / pred.shape[0]
# update parameters
self.theta = self.theta - (self.lr / self.n) * gradient
def train(self):
"""
训练线性回归
:return: 参数矩阵theta (1,d+1); 损失序列 loss
"""
self.init_theta()
for i in range(self.epoch):
# pred (1,n); theta (1,d+1); self.x.T (d+1, n)
pred = np.matmul(self.theta, self.x.T)
# pred (n,1)
pred = pred.T
curr_loss = square_loss(pred, self.y) / (2 * self.n)
val_loss = self.validation(self.val_x, self.val_y)
self.gradient_decent(pred)
self.val_loss.append(val_loss)
self.loss.append(curr_loss)
print("Epoch: {}/{}\tTrain Loss: {:.4f}\tVal loss: {:.4f}".format(i + 1, self.epoch, curr_loss, val_loss))
# un_scaling parameters
self.theta[0, 1:] = self.theta[0, 1:] / self.x_std.T * self.y_std[0]
self.theta[0, 0] = self.theta[0, 0] * self.y_std[0] + self.y_mean[0] - np.dot(self.theta[0, 1:], self.x_mean)
return self.theta, self.loss, self.val_loss
def predict(self, x):
"""
回归预测
:param x: 输入样本 (n,d)
:return: 预测结果 (n,1)
"""
# (d,1)
t = np.ones(shape=(x.shape[0], 1))
x = np.concatenate((t, x), axis=1)
pred = np.matmul(self.theta, x.T)
return pred.T
4. Experimental results
Univariate regression
Data set visualization
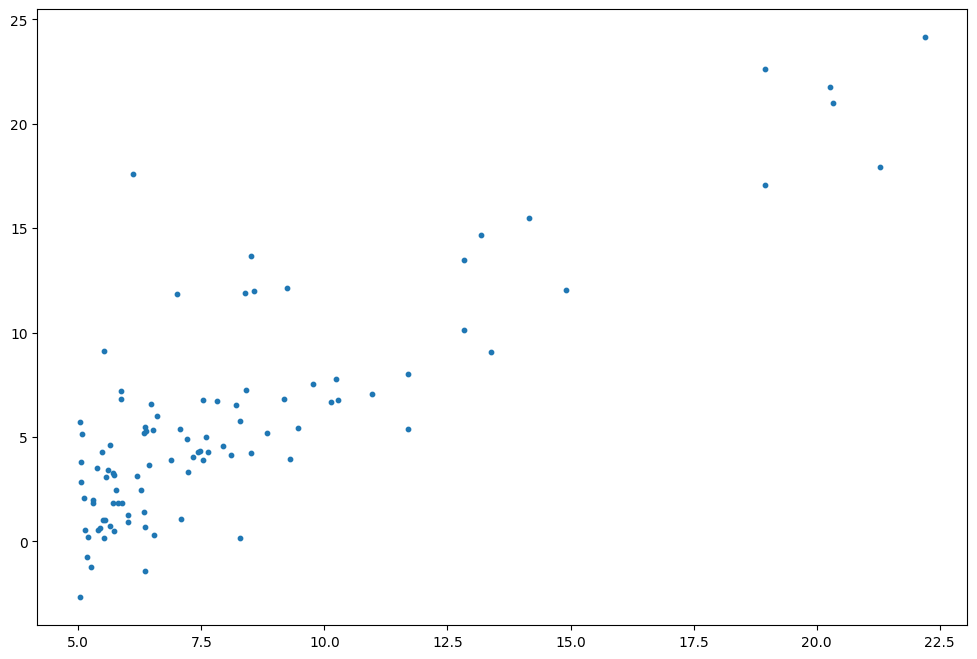
training set and test set division
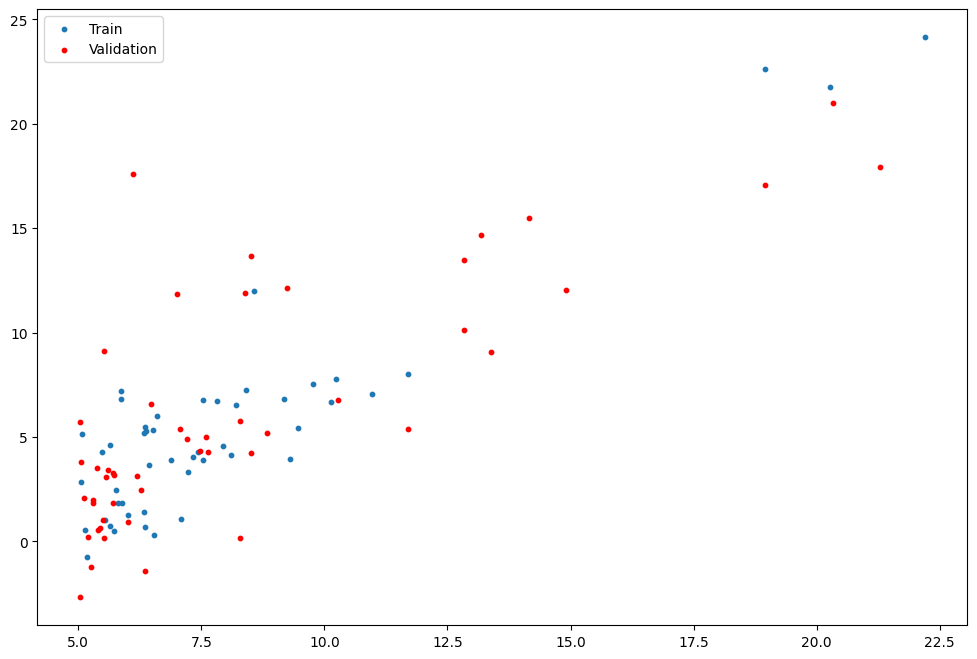
from LinearRegression import LinearRegression
epochs = 200
alpha = 1
linear_reg = LinearRegression(x=train_x_ex,y=train_y_ex,val_x=val_x_ex, val_y=val_y_ex, lr=alpha,epoch=epochs)
start_time = time.time()
theta,loss, val_loss = linear_reg.train()
end_time = time.time()
Train Time: 0.0309s
Val Loss: 6.7951
Training process visualization
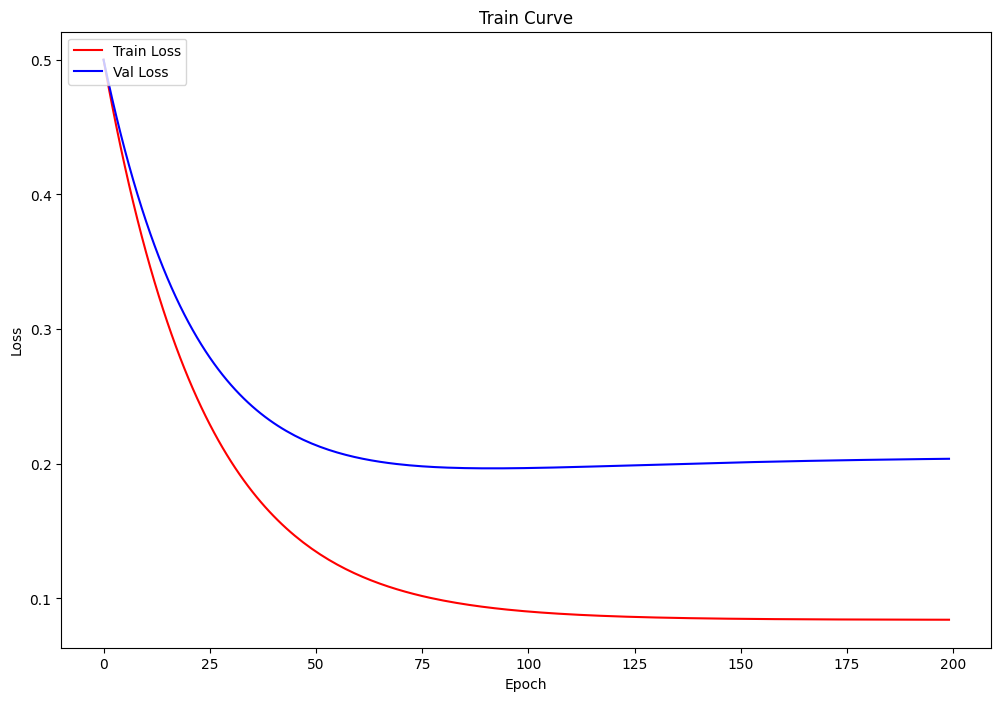
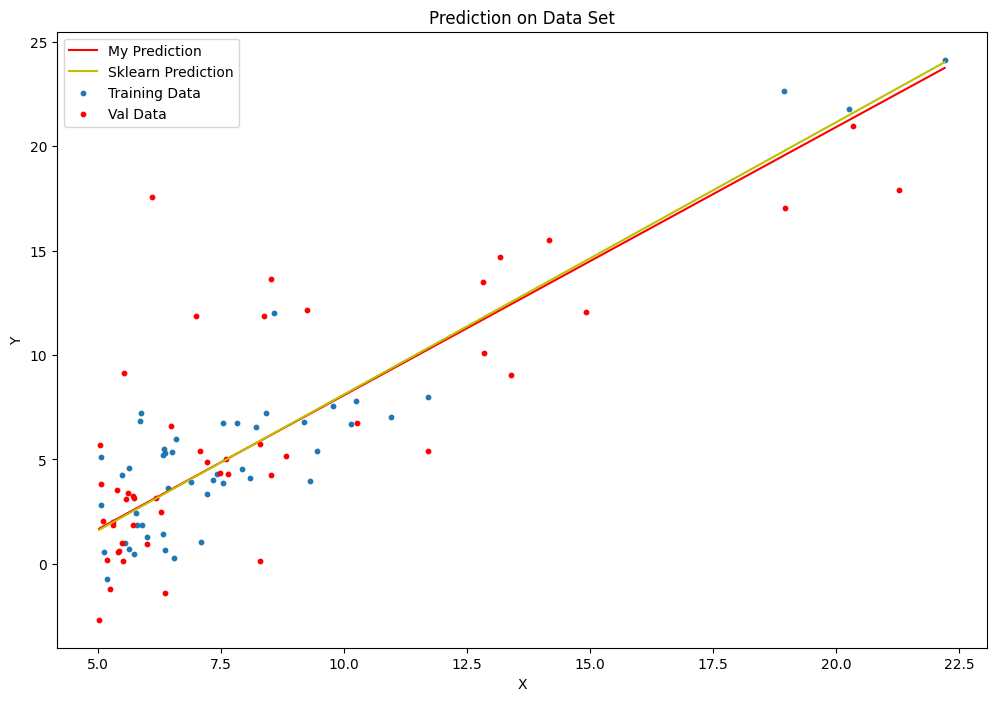
and sk-learn comparison prediction curve
multivariable regression
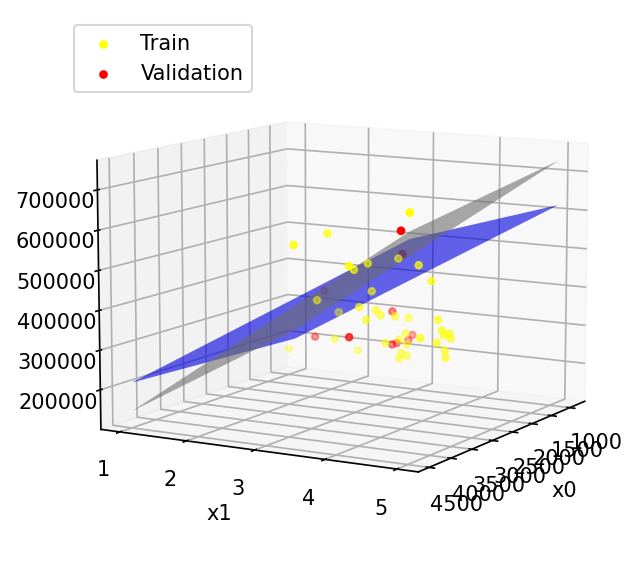
Data visualization and training set and validation set
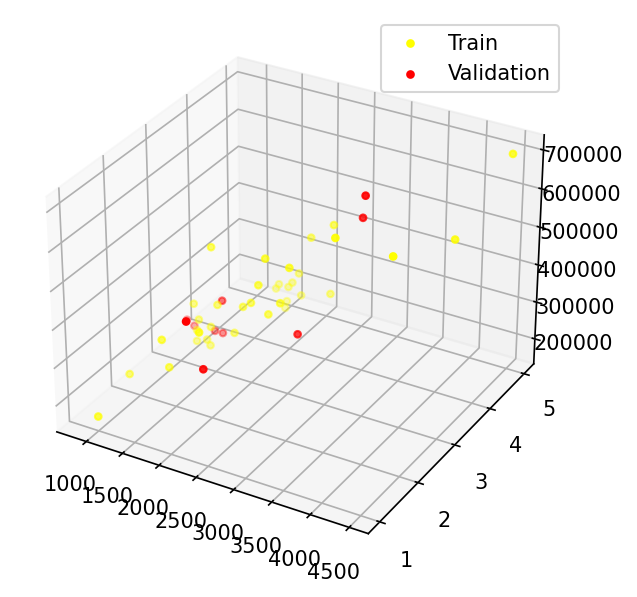
from LinearRegression import LinearRegression
alpha = 0.1
epochs = 1000
multi_lr = LinearRegression(train_x,train_y_ex,val_x=val_x,val_y=val_y_ex, epoch=epochs,lr=alpha)
start_time = time.time()
theta, loss, val_loss = multi_lr.train()
end_time = time.time()
Train Time: 0.1209s
Val Loss: 4.187(采用归一化后数据计算损失)
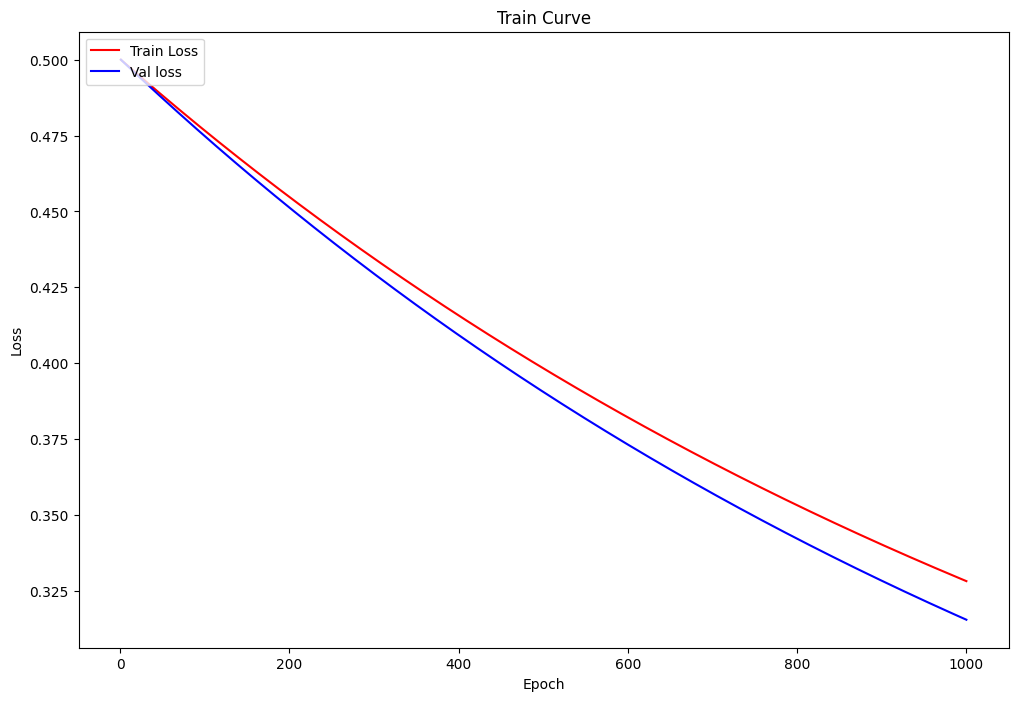
Visualization of the training process
Prediction plane (compared with sk-learn)
where blue is the prediction plane of this algorithm and gray is the prediction plane of sk-learn
Experiment summary
For the implementation of linear regression algorithm to achieve better performance, you can try to adjust the learning rate or the number of iterations to obtain better performance. Since matrix operations are used instead of loops, the training time is greatly shortened, but it has not yet reached the level of the sk-learn library function.