Article directory
module < package < library
module
A file with the suffix py defines some constants and functions, and the module name is the name of the py file.
import 模块
Bag
Structural management of modules combines many module files with related functions into packages. The package file consists of _init_.py and module files. Use the init file to identify whether it is a package file.
import 包.模块
Library
Modules and packages with certain functionality can be called libraries.
math
Provides mathematical operation functions for floating point numbers. The return values of functions under the math module are all floating point numbers.
import math
dir(math)
# 包含54个常量/方法
random
| function | describe |
|---|---|
| choice(seq) | Randomly select an element from the elements of the sequence, such as random.choice(range(10)), randomly select an integer from 0 to 9 |
| randrange ([start,] stop [,step]) | Gets a random number from a set in the specified range that increases by the specified base. The default base value is 1 |
| random() | Randomly generate the next real number, which is in the range [0,1) |
| seed([x]) | Change the seed of the random number generator |
| shuffle(lst) | Randomly sort all elements of a sequence |
| uniform(x, y) | Randomly generate the next real number, which is in the range [x,y] |
screaming
The urllib library is used to operate web page URLs and crawl and process the content of web pages.
module
request
Open and read URLs
urlopen method
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
- url, web address
- data, other data objects sent to the server, defaults to none
- timeout, set access timeout
- cafile, capath, the former is the CA certificate, the latter is the path of the CA certificate, which is required to use HTTPS
- casefault, deprecated
- context, ssl.SSLContext type, used to specify SSL settings
Reading web content
read(), read the entire web page content, you can specify the read length
readline(), read one line of the file
readlines(), read the entire content of the file, and assign the read content to a list variable
from urllib.request import urlopen
url = urlopen("http://c.biancheng.net/view/2397.html")
print(url.read(100))
print(url.readline())
lines = url.readlines()
for line in lines:
print(line)
Web page status code
getcode(), get the web page status code
Save web page locally
from urllib.request import urlopen
myURL = urlopen("https://www.runoob.com/")
f = open("runoob_urllib_test.html", "wb")
content = myURL.read() # 读取网页内容
f.write(content)
f.close()
Locally generate the runoob_urllib_test.htm file, which contains all the content of the web page
file processing, https://www.runoob.com/python3/python3-file-methods.html
encode decode
quote(),encode
unquote()decode
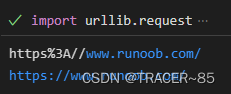
import urllib.request
encode_url = urllib.request.quote("https://www.runoob.com/") # 编码
print(encode_url)
unencode_url = urllib.request.unquote(encode_url) # 解码
print(unencode_url)
String encoding sequence: gbk, unicode, utf16, url decoding
String decoding sequence: url decoding, utf16, unicode, gbk
error
Contains exceptions thrown by urllib.request
parse
Parse URL
robotparser
Parse robots.txt file