Article directory
1. Reptile
1. Directional crawler
The feasibility of directional crawlers is too low because the website may be revised and there are many types of websites.
2. Laws
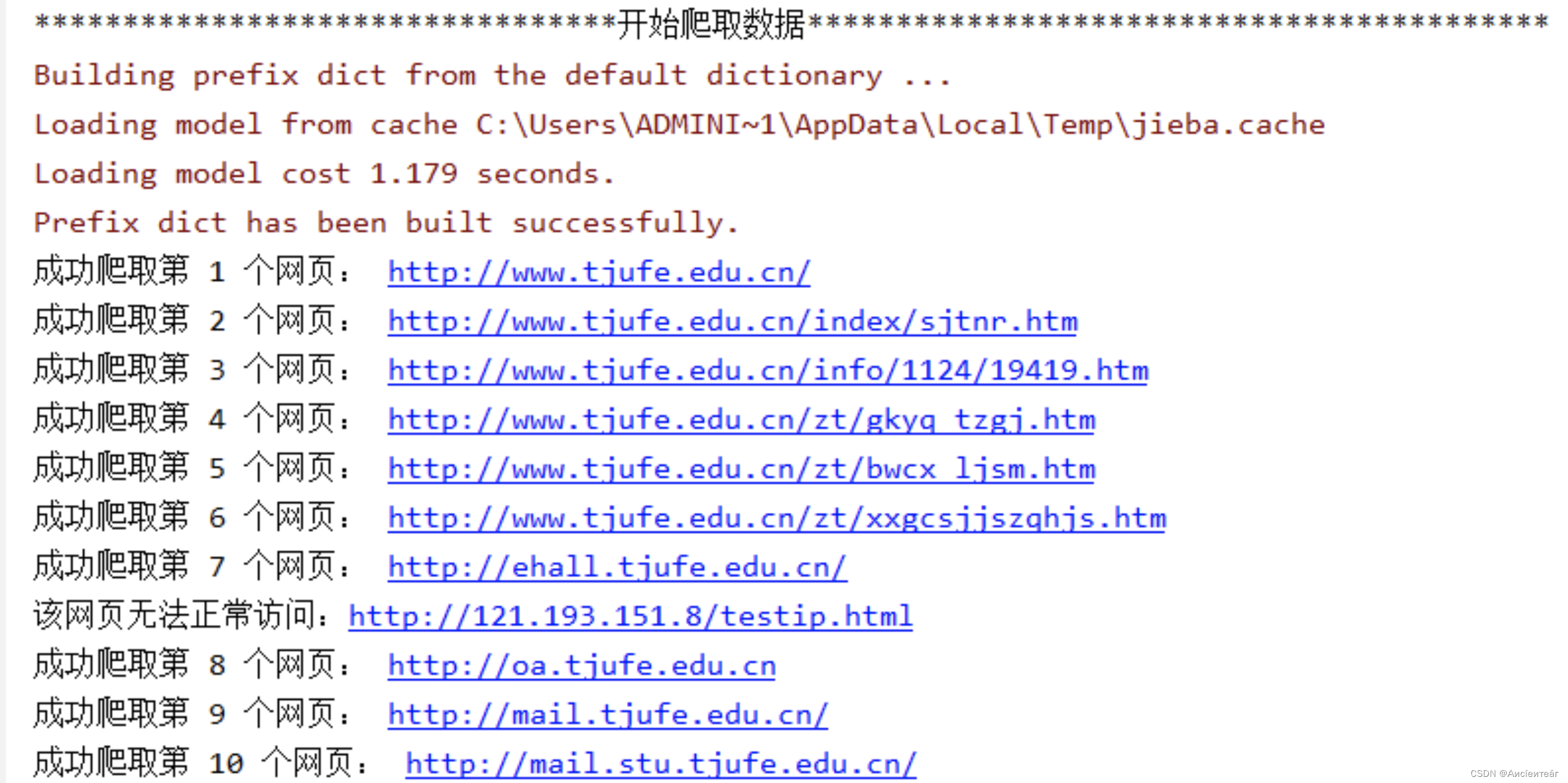
Most of the test situation analysis involves finding relevant documents. The behavior pattern of the required data is basically entered from the list page -> article page, and the specific article is where pictures are inserted to describe the
data we need. Such as the following announcement data provided by the website of China Public Education.

3. Crawling strategy
Instead of crawling a specific website, crawl all data sources.
List the announcement information networks of all provinces and cities across the country in the form of a list (or more than a thousand data sources now).
- Obtain the homepage URL address: Each entry in the announcement official website list is dynamically displayed through the template for tag. The data comes from the data source, which stores the name and URL address of each official website.
2. After confirming the establishment of a certain official website's vocabulary, query the homepage address of the portal website corresponding to the id value, and the crawler will start crawling from this address. - Crawler API to obtain web page information: There are many sub-web pages in the portal, and DFS and BFS can be used to obtain information on each sub-web page. After setting the request header, use the request.get method to capture the title, content, URL and other information of the web page.
- Parsing web pages and word segmentation: For each sub-web page, after obtaining the source code of the page, the title and content are together. You can use BeautifulSoup to parse the content of the web page, parse out the title and content of the web page, and then use Python's jieba Chinese word segmentation The library performs Chinese word segmentation to turn continuous content into words. The results of word segmentation can be placed in the list and can be used later, such as sorting test time, filtering test content, etc.
- Store in data table: After the above processing of web page information, two data tables are constructed. One stores URL, title, etc., and the other stores the Chinese words after segmentation of the web page content.
6. After successfully crawling multiple web pages, the data is summarized.
4. Full page crawling
After entering the article, it does not only capture specific fields, but the entire page, and then performs corresponding text extraction and operations.
5. Crawling plan
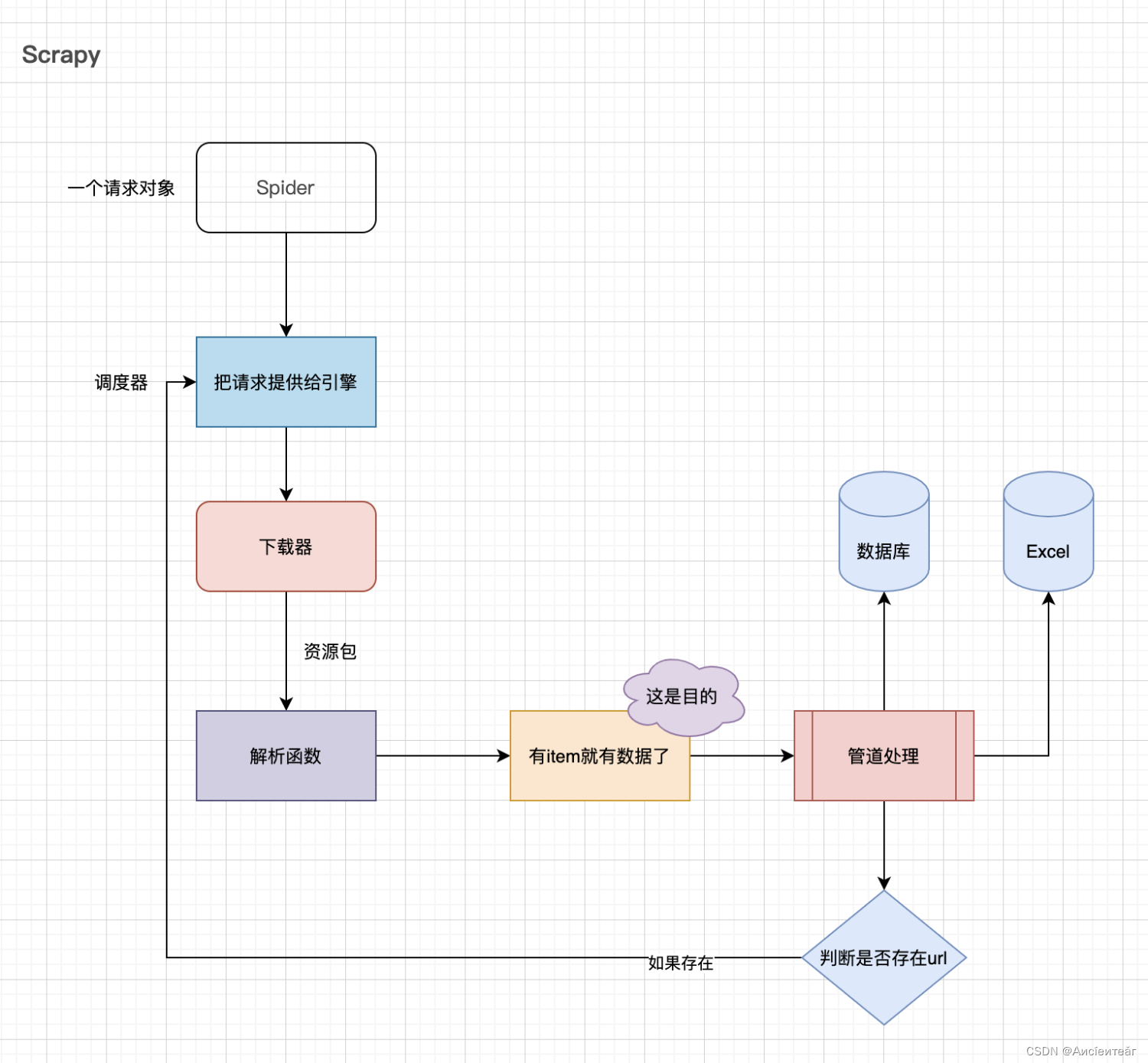
5.1 Scrapy
The scheduler here is a queue, and after dequeuing, it enters the downloader.
item is the desired data packet.
If there are still URLs after pipeline processing, you can add them to the queue. Like breadth-first search, all related pages are queued. After joining the queue, they are dequeued and entered into the downloader.
5.2 BeautifulSoup
This third party mainly uses BeautifulSoup for analysis. In fact, it contains some attributes, which are obtained through attributes, such as name, content and other information. When obtaining information, some labels or h1, h2, etc.
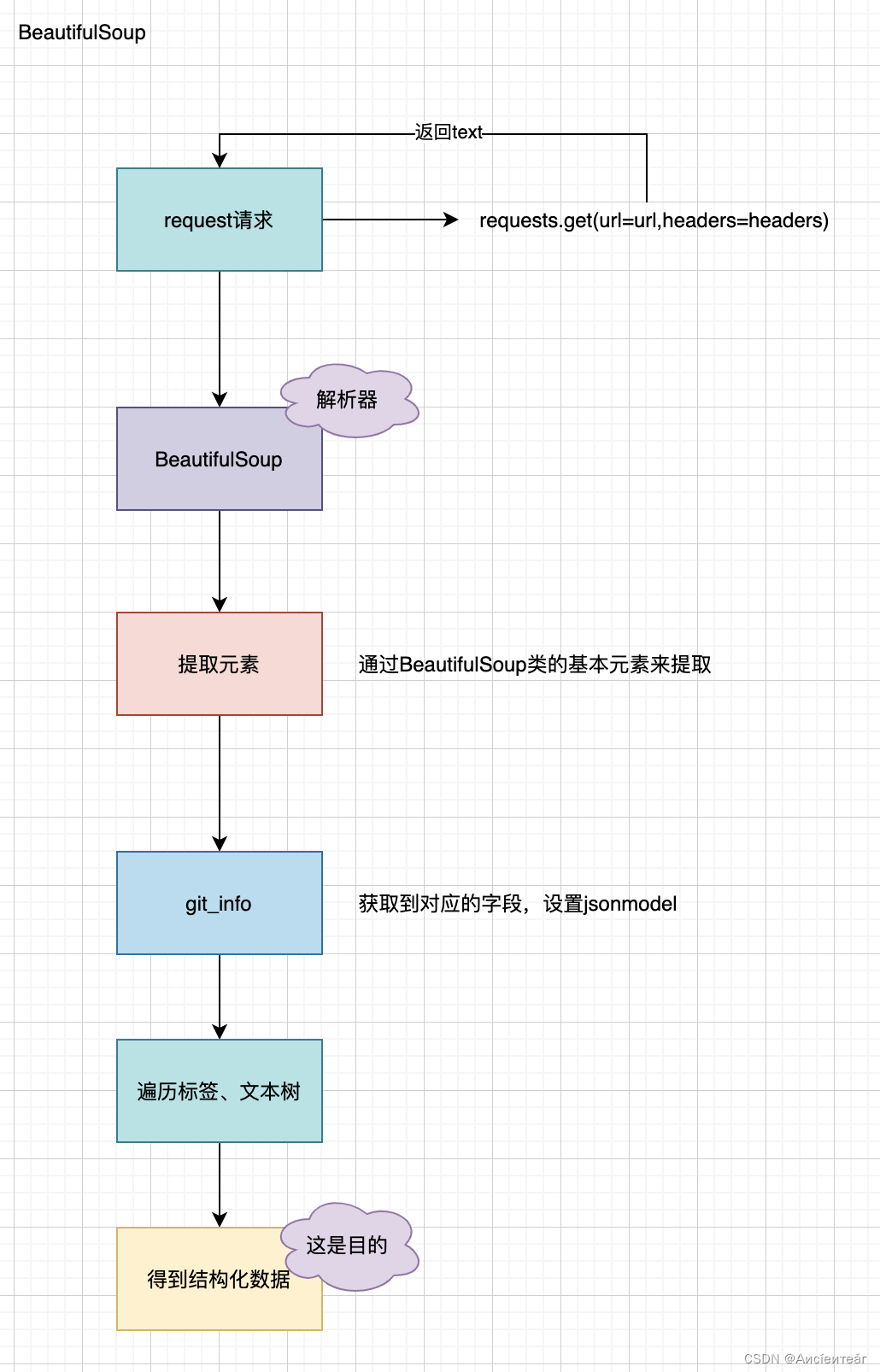
2. Text extraction
Because I am not sure exactly what data is needed in the end, I don’t have an accurate positioning.
If you are extracting information inside the announcement, you can perform text extraction. You can use xpath to obtain text information, that is, obtain text information based on the front-end text format. The idea is to traverse all the internal sub-labels and obtain the label text, and finally splice them.
If you want to obtain specific content such as registration time, you can perform Chinese word segmentation, filter out important information after word segmentation, and do other things based on the important information.
3. Questions
1. What do I want to know from the data?
2. Similar to how BOSS provides positions for users to filter, is this filtering based on region and exam time, screening exam announcements?
3. This test situation refers to the test situation or the analysis of the test situation. Do we only need to summarize the exam time and content? Or will job recommendations be made based on exam results over the years, such as the number of applicants and admission ratio?
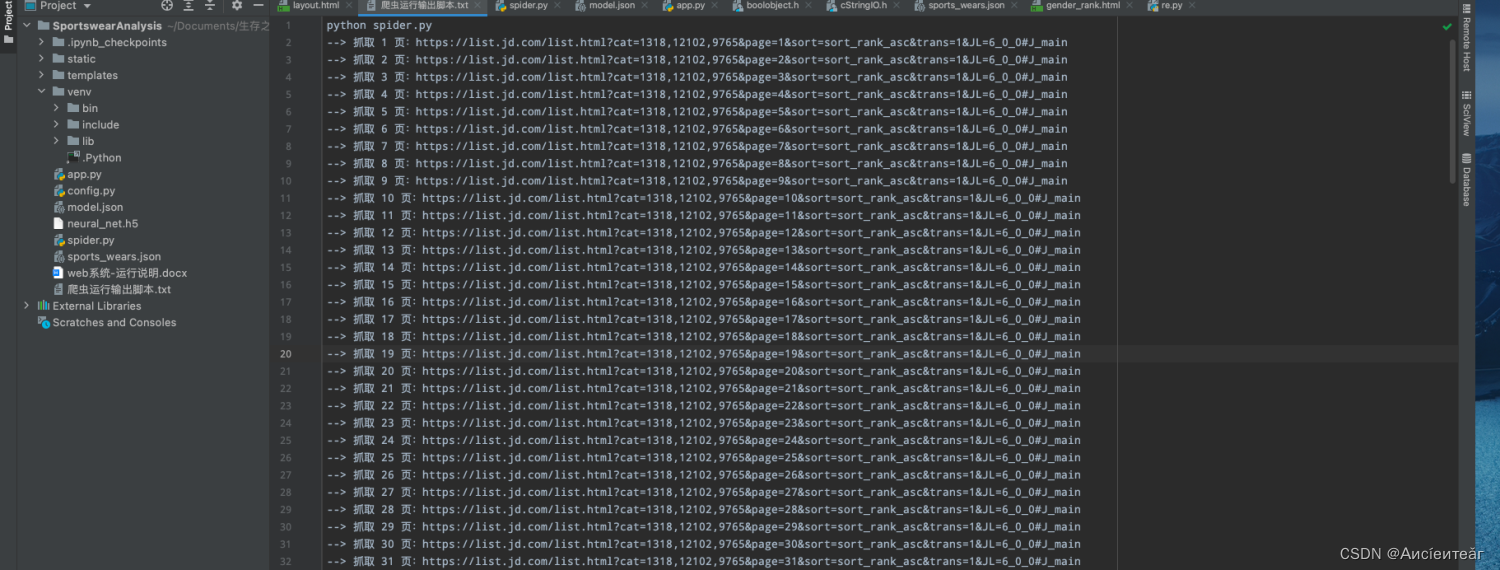
4. Currently, for the China Public Education website, the crawler content mainly includes: the update time, name, title, announcement link, etc. of the exam announcement, as shown in the figure below, and there is no extraction of specific exam data (such as exam time and exam subjects, etc.) , does it meet the current needs?
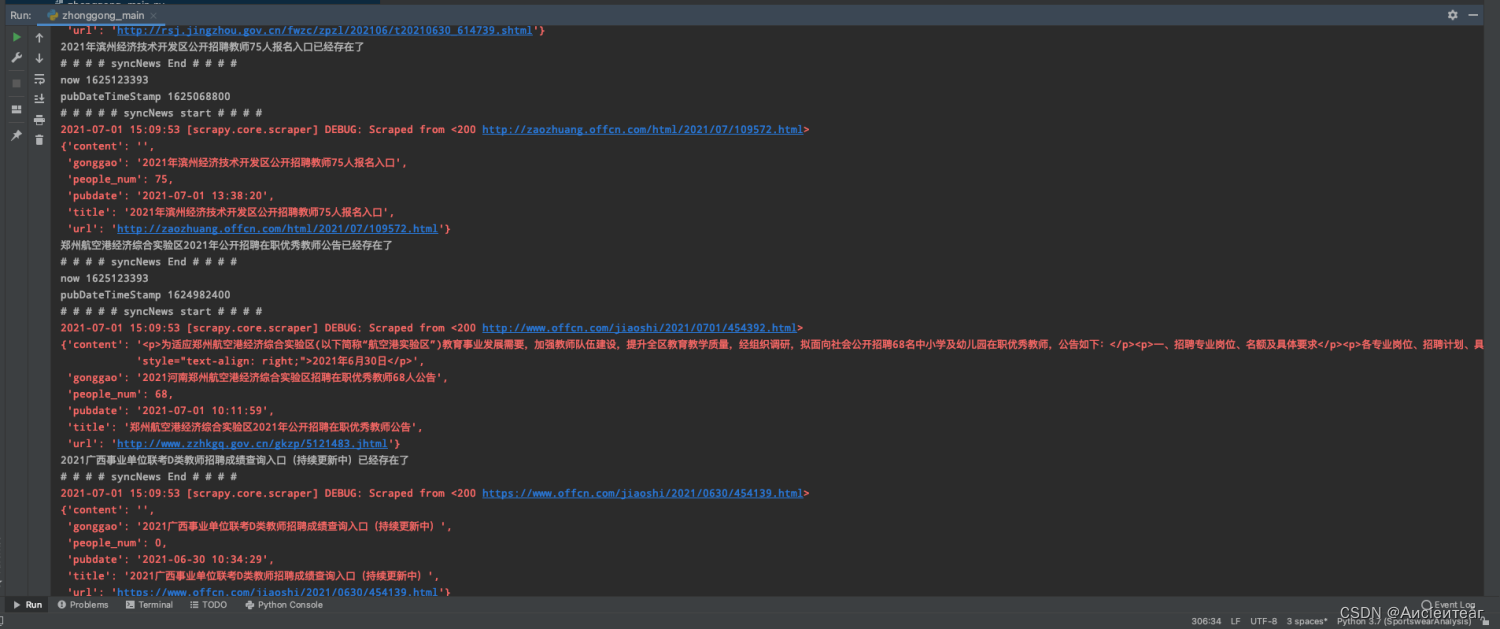
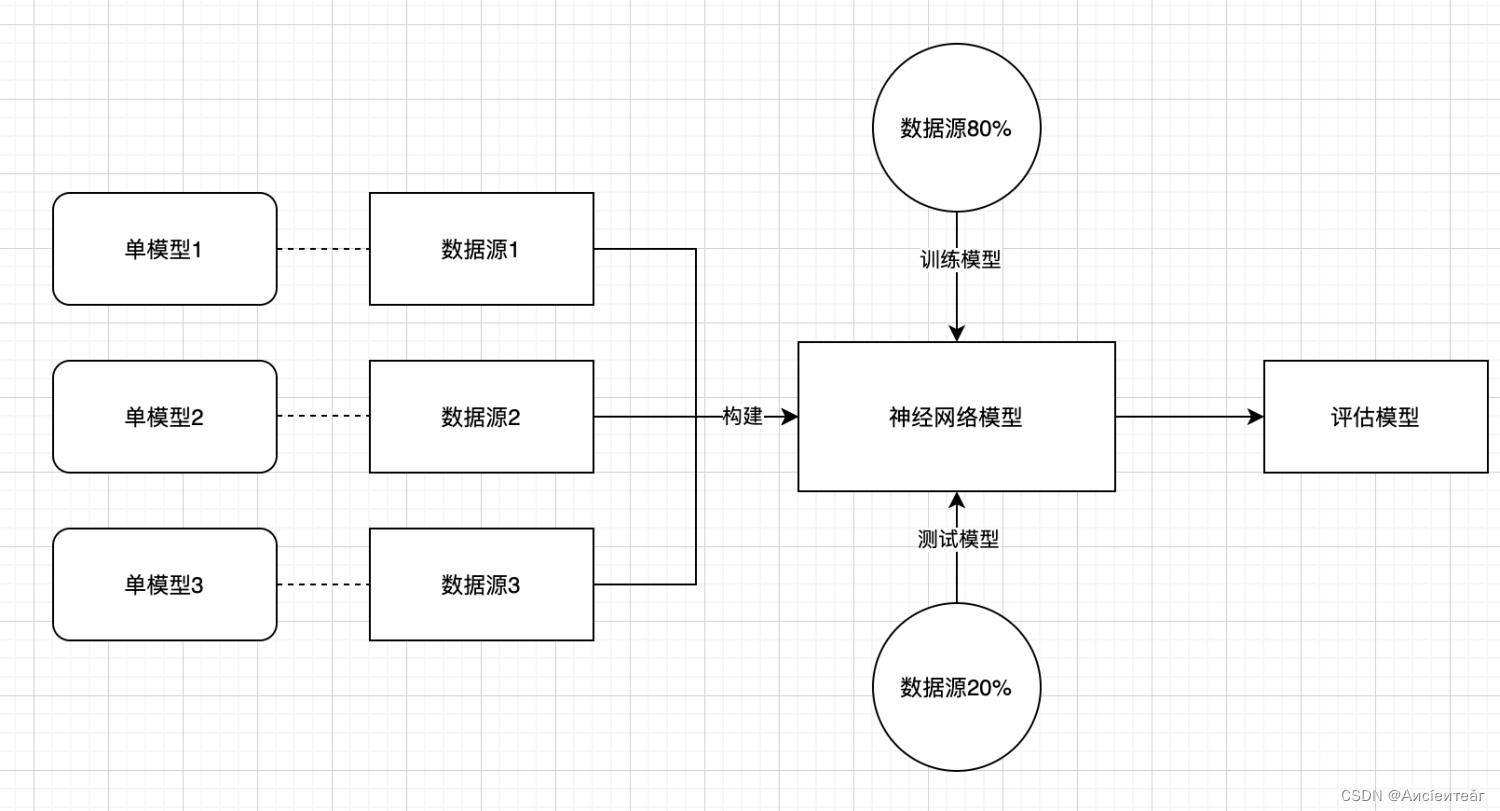
4. Data source modeling research
Background: Examination mainly relies on external data sources of platforms and models, and the algorithms among different portals are not uniform. If each data source relies on a model, the time cost is too high. Considering dynamic model fusion, a unified model is combined according to normalization and weighted fusion.
Solution: Based on existing data sources, find several typical data sources, build a model, and see which data sources the model can be covered by.
Specifically:
1. A single model for each data source.
2. Train multiple models and use machine learning to train models to diversify and adapt to different data sources. As data sources continue to be added, the model will become more and more accurate.
3. The model can be standardized with reference to a certain weight.
Not sure of feasibility yet. Need to know more later.
It feels like this: