
The open course on elastic computing technology - CloudOps cloud operation and maintenance season has come to a successful conclusion. Zheng Dayu, an expert in elastic computing technology at Alibaba Cloud, shared a course titled "Using OOS for Automated Cloud Operation and Maintenance" in this series of courses. The course The content covers the challenges faced by resource operation and maintenance on the cloud, the secret of OOS automated operation and maintenance capabilities, and the practice of CloudOps on the cloud using OOS.
The following is a compilation of his course content for developers to learn from:

1. Challenges faced by cloud resource operation and maintenance
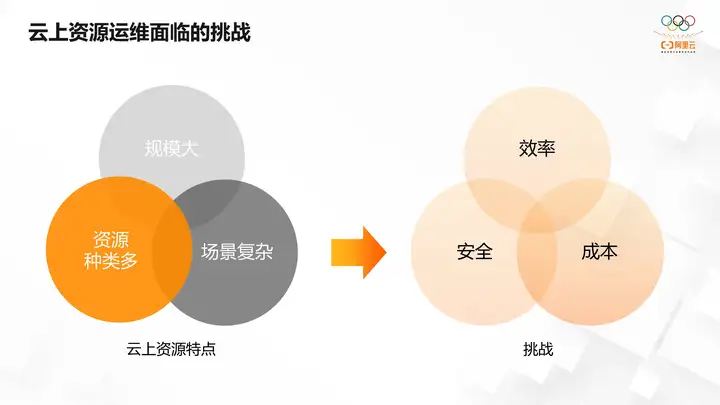
Cloud resources have the following characteristics. First, they are large in scale. Users do not need to build their own infrastructure and can theoretically purchase unlimited cloud resources. In addition, due to the elasticity of cloud resources, users can obtain the cloud resources they need anytime and anywhere according to their own needs. All of these results in cloud resources being larger in scale than self-built infrastructure. Secondly, there are many types of resources on the cloud. In addition to traditional computing, storage, and network resources, the cloud provides more diverse services. For example, databases, message queues, artificial intelligence AI, Internet of Things and other types of resources.
Users can purchase corresponding resources according to their own needs, eliminating the cumbersome process of building their own. Various types of cloud services are provided on the cloud, allowing users to focus on developing their own business logic. More and more technical architectures are sinking to the cloud resource layer. On the one hand, this eliminates the need for users to pay attention to infrastructure maintenance and management, and at the same time, it also makes the scenario of cloud resources more complex.
It is precisely because of these characteristics of cloud resources that the operation and maintenance of resources also faces corresponding challenges in terms of efficiency, cost, security, etc.
1. The scale of cloud resources is growing rapidly
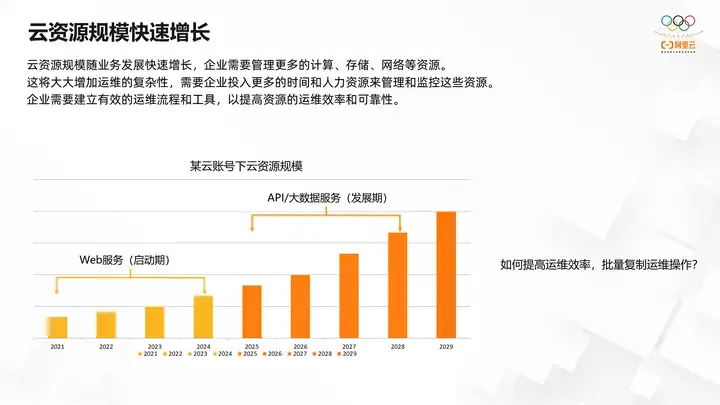
First, the scale of cloud resources is growing rapidly. The scale of cloud resources will grow rapidly with the development of business. Enterprises need to manage more computing, storage, network and other resources. This will greatly increase the complexity of operation and maintenance and require enterprises to invest more time and human resources in management and monitoring. these resources. Enterprises need to establish effective operation and maintenance processes and tools to improve the efficiency and reliability of resource operation and maintenance.
The following takes the scale of cloud resources under a certain cloud account as an example. In the initial stage, the business is in the startup period, and only a few ECS instances are needed to deploy web services to meet the demand. The growth of cloud resources during this period has been relatively stable. The management of these small amounts of resources can be completed using some manual operation and maintenance methods or simple operation and maintenance scripts. However, as the business develops and more services are provided, including API big data services, the resource scale grows exponentially. If we adopt the same operation and maintenance method as before, the manpower required is also actively increasing. At this time, how to batch copy the previous operation and maintenance experience from a small amount of resources to a large number of resources through automated means, thereby improving operation and maintenance efficiency, is a challenge.
2. Cloud resource costs are also growing rapidly.
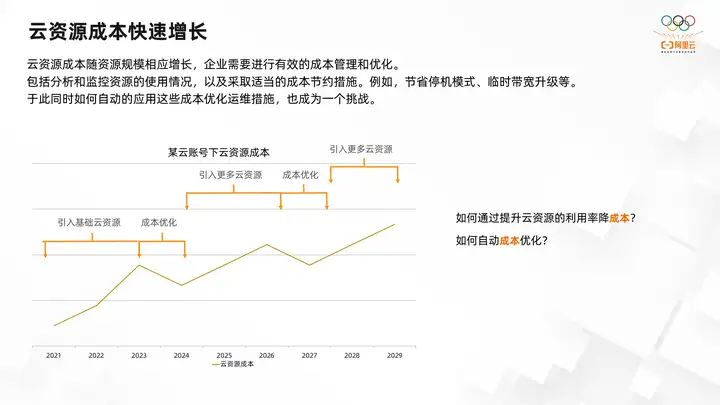
Cloud resource costs increase correspondingly with resource scale, and enterprises need to carry out effective cost management and optimization, including analyzing and monitoring resource usage, and adopting appropriate cost-saving tests, such as saving downtime mode, temporary bandwidth upgrades, etc. At the same time, how to apply these cost optimization and operation and maintenance measures automatically and culturally has also become a challenge.
Taking the cost of cloud resources under a certain cloud account as an example, in the initial stage, the enterprise only introduced a small amount of ecs cloud resources. Through some applications and some cost optimization best practices, the overall cost of cloud resources can be reduced. However, as the business develops, more ecs resources or other cloud resources are introduced, including databases, message queues, etc. It is necessary to continuously optimize the cost of the newly introduced resources. It can be seen that the cost of cloud resources has shown a fluctuating and rising trend. At this time, how to improve the utilization of cloud resources and reduce costs has naturally become another challenge. At the same time, how to avoid manual optimization by automatically extending previous cost optimization experience to newly introduced resources is also a key point.
3. Security compliance issues are increasingly important
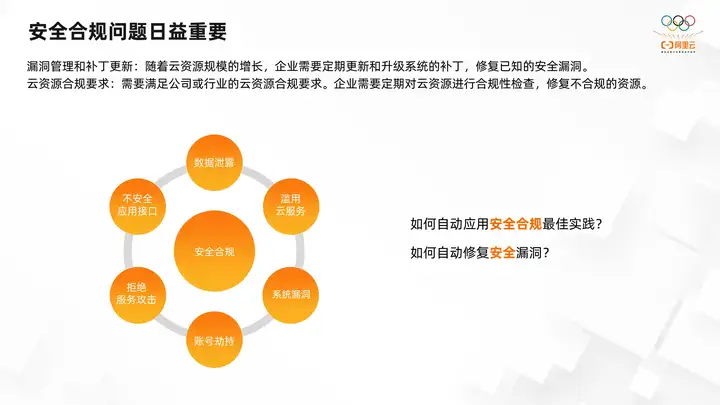
Security compliance issues on the cloud include data leaks, abuse of service system vulnerabilities, account hijacking, denial of service attacks, insecure application interfaces, etc. In fact, there have been many best events on the cloud regarding these security compliance issues.
For example, as the scale of cloud resources grows, enterprises need to regularly manage system vulnerabilities, update and upgrade system patches, and repair known security vulnerabilities. In response to the compliance requirements of some companies or industries, enterprises need to regularly conduct compliance checks on cloud resources and repair non-compliant resources.
For example, some industries have high reliability requirements and require multi-availability zones or even cross-regional disaster recovery. Enterprises need to check the corresponding cloud resources according to compliance requirements. If the resources do not meet the disaster recovery requirements, corresponding corrections will be made. The whole process is time-consuming and labor-intensive. How to automatically check some security compliance requirements and automatically correct non-compliant resources has become another challenge for cloud operation and maintenance.
4. How to implement CloudOps best practices

Although most operation and maintenance operations on the cloud have been encapsulated into open APIs, these best practice scenarios are often not a simple call to an API, or simple on-cloud operations. It is a combination of a series of operation and maintenance operations. How to automatically apply many best practices to cloud resources will become a proposition. The OOS operation and maintenance orchestration service officially provides such a platform with task orchestration capabilities.
2. Revealing the secrets of OOS automated operation and maintenance capabilities
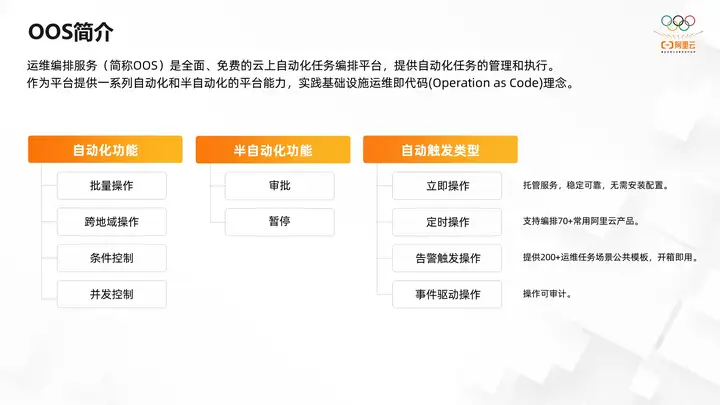
Let’s briefly introduce the OOS service. The operation and maintenance orchestration service is referred to as OOS. It is a comprehensive free cloud automation task orchestration platform that provides the management and execution of automated tasks. As a platform, it provides a series of automated and semi-automated platform capabilities and infrastructure. The concept of cloud office as Code for operation and maintenance and code.
First of all, in terms of automation capabilities, OOS provides batch operations, cross-regional operating condition control, concurrency control and other capabilities, so that operation and maintenance tasks can run efficiently and stably in complex scenarios such as multi-regional and large-volume resources. Secondly, OOS also supports semi-automated functions such as approval and suspension.
For example, for some important operation and maintenance operations, in some cases, the approval of relevant or key personnel may be required before execution. In this case, you can add an approval step to the OOS task process, notify relevant personnel for approval, and then automatically execute the operation after approval. In addition, OOS also supports pausing operations for some steps that cannot be automated. Relevant personnel must manually confirm before executing automated operations. Then OOS also supports a variety of trigger types, including immediate operations, scheduled operations, and event-driven operations close to the trigger operation.
For example, if I want to execute a command immediately, I can use the first-level operation, which is also the default method. Then if I want to execute the command at 8 o'clock tomorrow night or execute the command at 8 o'clock every night, this kind of periodic operation or delayed operation can be done by scheduled operation. If I want to target some cloud monitoring alarm conditions. For example, when the CPU usage is higher than 80%, some cleaning operations are performed, or when the disk usage is higher than 80%, some unnecessary files are deleted. At this time, you can use alarms to trigger operations and event-driven operations. It is combined with events monitored by our cloud, taking ECS events as an example.
When ECS is started to perform some initialization operations, event operations can be used. Based on these capabilities, OOS provides stable and reliable hosting services without the need for users to install and configure ECS or products. OOS supports orchestration More than 70 commonly used Alibaba products provide more than 200 operation and maintenance task scenarios, and public templates are available out of the box. In addition, all OOS operation and maintenance operations can be audited in the action trio to ensure users' auditing needs.
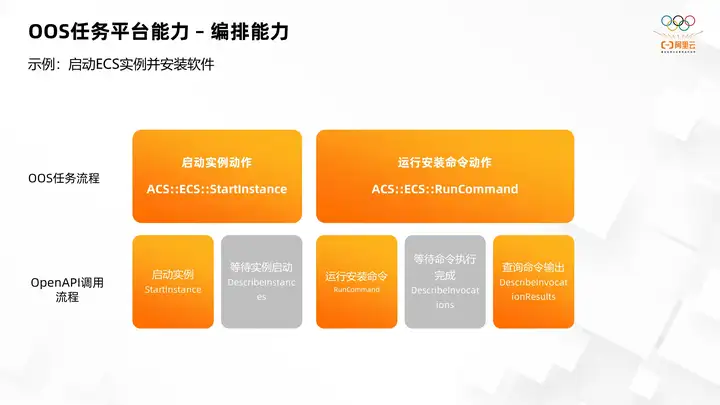
Based on the above platform capabilities, OOS has built a powerful API orchestration capability. Taking starting an ECS instance and installing software as an example, in our common operation and maintenance methods, we need to start the example through start instance first. Because the star instance centralized instance is an asynchronous process, you must wait for the instance to be in a running state before proceeding with subsequent software installation operations. Therefore, you need to check the system status of the instance by constantly describing instance. Then until the status of the instance is running, then use the come on running command API to install the software command. The installation command process is also an asynchronous process. So we need to wait for the command execution to complete through constant polling. After the command execution is completed, you need to query the result output of the command through an api described invocation result to determine whether the command was executed as we expected.
In the OOS task process, the first part of the process of starting the instance and waiting for the instance to start is divided into a cloud product action, which is ACS, ECS, StartInstance. In the process, it completes the process of startup establishment. At the same time, it will wait for the instance to be running. When the action is completed, the command can be run immediately without waiting. Then perform the installation command action at the same time, wait for the command execution to complete, and finally output the result. When these two actions are fully executed, the current results will be output to the output of the task, so that you can see at a glance whether the command is executed as expected, without having to maintain complex processes.

Based on the platform capabilities and API orchestration capabilities, rich operation and maintenance scenarios were later built. Including common operation and maintenance tasks, batch operation instances, batch management software, scheduled power on and off, temporary upgrade of bandwidth, creating and updating images, and cleaning disks. These common operation and maintenance tasks are abstracted by us based on collecting user usage scenarios. The most commonly used, these common operation and maintenance tasks are extracted and placed on the OOS console.
At the same time, some optimizations will be made to the processes of these operations. In addition, in addition to providing these basic capabilities, OOS also provides some auxiliary scenario capabilities, including software package management, parameter management, configuration list, and patch management. Software package management is to install software that can be managed by Alibaba Cloud agent or software package management tools in the instance.
At the same time, the software package also supports enterprises to upload their own software to OOS, and install it to the corresponding ecs instance through version management. Parameter management provides storage management services for parameters, supporting both text data and encrypted data formats. Encryption MS is used on the data side to ensure encryption security. The configuration list is able to obtain some internal information of the OOS of the cloud server, which cannot be obtained through the API.
For example, there is information about the installation of software packages in the system, and there is also some information about the files in the system, including the size of the files and the update time of the files. These are also not available through the API. Therefore, we can obtain this information through the configuration list. A natural scenario is to take the software installation information just now as an example. We can update it by filtering some examples where the software is not installed, or where a low version of the software is installed. Update the software to the latest version.
Patch management scans or installs patch system patches for ECS instances.
Users can flexibly set patch scanning and installation conditions according to their own needs. For example, only installing patches for a certain operating system version during installation, such as only installing Windows 2022 operating system, special patches or only installing medium and high-risk patches, can meet user-defined installation needs.
3. CloudOps practice using OOS cloud
1. Efficient operation and maintenance: batch operation ECS scenario
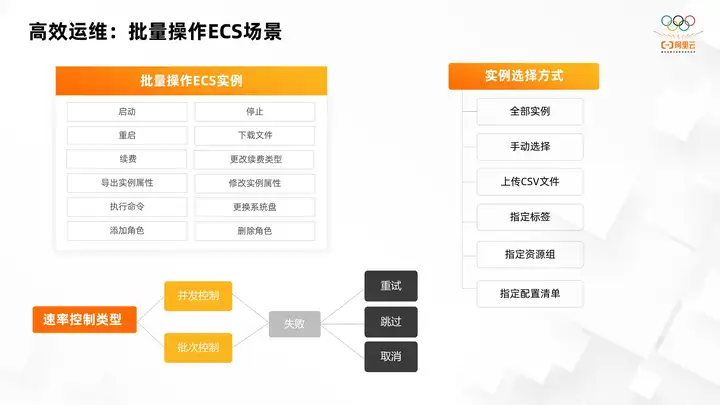
First, we abstract the most commonly used ecs operations into batch operation ECS instance scenarios. These include functions such as starting an instance, stopping an instance, restarting an instance, downloading files in the instance, renewing and changing the renewal type, exporting instance properties, modifying instance properties, executing commands, replacing the system disk, adding instance roles, and deleting example roles.
For batch operation of ECS instances, there are various methods for selecting instances. For example, you can select all instances under the account. For some cases where the number of selected instances is relatively small, you can choose to manually select the corresponding instance. When there are a large number of instances and not all instances are available, manual selection is more troublesome. We can maintain the instances in csv. Select large batches of instances by uploading csv files. Instances can support up to 5000 instances in csv, which can meet most scenarios.
If the user's resources are managed through tags or resource groups. For example, all resources in the IT department are labeled accordingly, or they belong to resource groups of the IT department. At this time, you can filter instances by specifying tags or resource groups. Finally, there is the configuration list function. For example, if I filter through the information in the configuration list, there are no instances of a certain software installed, or the change date of a certain file is in a certain time. All instances before a time point, which can support various rich instance filtering methods.
In addition, OOS also provides powerful rate control functions, supporting two forms of frequency control and batch control. For example, if there are 100 ECS instances, setting the concurrency to 10 will ensure that 10 instances are operated simultaneously each time. When the operation of one instance is completed, the next instance will come in to perform the operation to make up for its space and ensure that there are always 10 instances operating at the same time. Batch control is to ensure that there will be no more operations until the batch is completed. The next batch comes in. For example, each batch has 10 instances, that is, the 10 instances in the second batch will not come in until all 10 instances in the first batch are executed. This is the difference between concurrency control and batch control.
At the same time, OOS also provides a powerful failure suspension function. If the failure suspension mode is set, in the batch, if an instance fails, it will be suspended at the failed instance. You can choose to skip or skip as needed. Cancel.
Generally speaking, for temporary errors or errors caused by resource dependencies that are not ready, you can manually correct these dependencies after checking again and then try again. If there are some unimportant operations and some ignorable operations that do not affect the results, you can choose to skip them. At this time, the failed instance will not continue to execute, but all remaining instances will continue to execute. If it is a critical operation that cannot be ignored, you can choose to cancel it at this time. This way he won't execute all the instances below again.
2. Efficient operation and maintenance: rolling upgrade of ECS applications
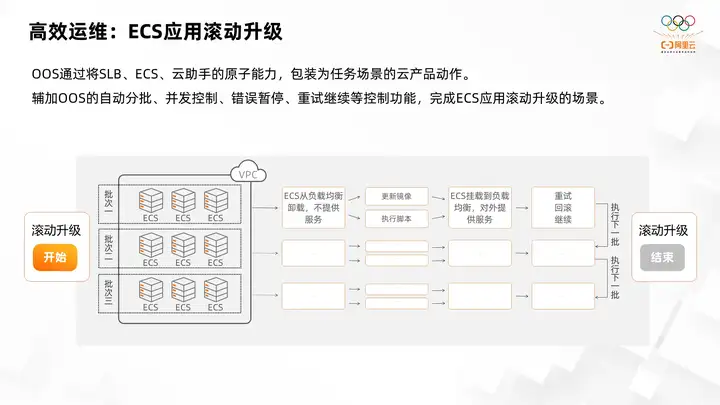
The second scenario is a rolling upgrade of ECS applications. OOS packages the atomic capabilities of the SLb ECS cloud assistant into cloud product actions in task scenarios, supplemented by OOS's automatic batch concurrency control, error suspension, retry continuation and other control functions. Complete the scenario of rolling upgrade of ECS application. During this process, the service must always be online. Therefore, during the application upgrade process, all ECX instances cannot be upgraded at once. A rolling upgrade needs to be performed in batches to ensure that at least part of the application is available at any point in time. Provide services. At this point OOS can take advantage of its powerful batching capabilities.
Taking this scenario as an example, oos divides all ECS instances into three batches, and only processes one batch of ECS instances at a time. In the process of processing a batch, the ecs instances are first repeatedly unloaded in the balance, that is, the weights of these instances are set to 0. These instances will not provide services. However, other remaining instances still provide services to ensure that the service is not offline. After uninstalling, update the ECS application by updating the image ECS image or executing the command script. After the update is completed, mount the updated ECS service. Go to the load balancer and provide services to the outside world.
Secondly, if there are instances in this batch that fail to execute, you can choose whether to retry or rollback the operation according to your needs to ensure that the service is always stable. After a batch of updates is completed, it will be mounted on some SLbs to provide external services. At this time, the second batch of ECS instances will be screened out, and the rolling upgrade operation will be performed on the second batch of ECS instances. Then the second batch of the same operations is rolled out and upgraded, and then the third batch of operations is performed. Until all ecs are updated to the latest version of the application. At this point, the rolling upgrade ends, thus taking advantage of OOS's powerful batching and task orchestration capabilities to improve the efficiency of ECS application release.
3. Efficient operation and maintenance: Use parameter warehouse to manage infrastructure configuration
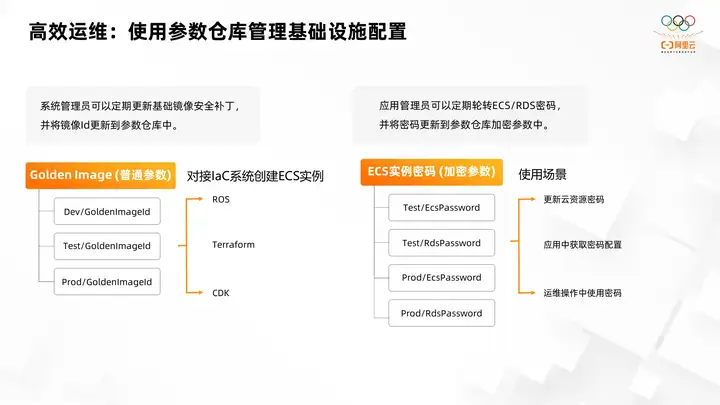
Taking two scenarios as examples, system administrators need to regularly update the security patches of the base image according to requirements. Because there will be some security vulnerabilities involved. So it needs to be updated with security patches regularly. Users create these resources by applying these mirrors to their own systems. However, in traditional scenarios, when users update images, they need to update all rOS templates at the same time and replace the old images with new images. After using the parameter warehouse, users only need to reference the corresponding parameters in the parameter warehouse in all templates. After updating the image, they only need to update the image ID to the corresponding parameters.
Next, by centrally managing these image IDs, all templates can be quickly updated to the latest images. This avoids the complexity of users manually updating all templates, because all templates are sometimes updated inconsistently or missed.
Another scenario is that for encryption parameters, the application administrator may rotate the passwords of ECS and RDS in the near future, and these passwords will be used in various scenarios. For example, update the password ECS and rds of cloud resources. Then, for example, for some rds database passwords, we obtain the password configuration in the application to connect to the database. Passwords are also used during some operation and maintenance operations. Then if it is the same traditional method, after updating the password, the application administrator will update the code and configuration in multiple places. This will cause accidents and malfunctions if there is any omission.
Then after using OOS encryption parameters to manage passwords, the application administrator only needs to put the corresponding password into the encryption parameters. For example, we can distinguish the passwords of the test environment and the production environment. Then the corresponding password will be obtained according to the name of the password during the operation of the corresponding cloud resource, operation and maintenance operation or application operation. This ensures that users do not need to update the passwords of resources scattered in various places, improving operation and maintenance efficiency.
4. Cost optimization: automated cloud resource cost optimization
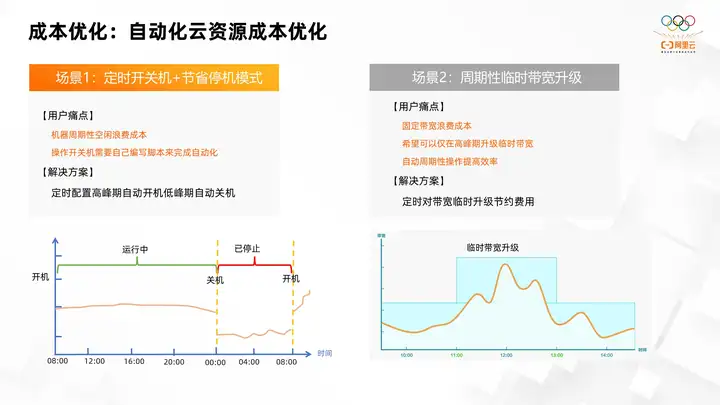
Another scenario implemented by OOS is automatic resource cost optimization. Users' resource utilization often fluctuates cyclically every day. For example, for some office services, the peak usage is from 8 am to 6 pm. After getting off work at 6 pm, the usage load will drop to a lower level. The cycle of some games or entertainment applications may be exactly opposite to that of office services. Peak times are after get off work and on weekends. At this time, by summarizing such experience, a corresponding theoretical basis is provided for automated cost optimization. The two scenarios taking computing and network resources as examples are the two scenarios in the picture.
Scenario 1, computing resources. The user's pain point is that its machines periodically cause unprecedented cost waste. First, the user's machine load peak is from 8 am to 12 pm. From 12 pm to 8 am the next morning, it is actually a low-lockdown period. When users make estimates, they estimate based on the computing resources during the peak period. If we estimate based on the resources during off-peak periods, there will be insufficient resources during peak periods, causing application denial of service and causing failures. However, estimating based on computing resources during peak periods will result in a waste of computing resources during low peak periods.
Ecs provides a downtime saving mode. Through the downtime saving mode, computing resources can not be charged during the downtime period. However, users need to write scripts to complete automation by saving average mode, which is also more complicated. Therefore, OOS provides a complete set of solutions to achieve cost optimization by regularly configuring automatic startup during peak periods and automatic shutdown during low peak periods. At 8 o'clock in the morning, oos will trigger the boot operation, and at 12 o'clock in the evening, it will trigger the shutdown operation. At this time, some idle computing resources are recycled, thereby reducing costs. Before the peak of the next day comes, it will be started again at 8 a.m., and then shut down at 12 p.m., and the automated cost optimization will be carried out over and over again.
Scenario 2 is the optimization of network resources. In fact, network resources also have peaks and valleys in usage. The peak period of bandwidth usage is from 11 am to 13 pm. The level of network usage at this time is obviously higher than at other times. Other times are off-peak periods. In this way, if the fixed bandwidth is set according to the low peak period, the bandwidth will be full during the peak period, making it impossible to provide services and causing some failures. If fixed bandwidth is estimated based on peak periods, bandwidth during off-peak periods will be greatly wasted. If some large bandwidth is used, the cost is higher because the peak period is short. At this time, users hope to temporarily upgrade bandwidth only during peak periods.
ECS provides the function of temporarily upgrading bandwidth. Users can specify how much bandwidth to upgrade during a certain period of time and for how long. Because bandwidth has a relatively fixed periodic fluctuation, users hope to be able to perform operations regularly. Therefore, OOS also provides scheduled bandwidth and an upgrade solution to save costs. The bandwidth is upgraded to a higher level at a short time preset by the user, such as 11 o'clock, and then lasts for two hours.
During the off-peak period of users, the bandwidth can be reduced, and on this basis, further operations can be carried out. If, for example, the user's estimation of the arrival time of the peak period is not very accurate, cloud monitoring alarm triggering can be used to perform temporary bandwidth upgrades. For example, if the bandwidth usage exceeds 70%, it is predicted that the bandwidth is about to arrive. During usage peaks, the temporary bandwidth will be increased at this time. Once the peak period is over, the temporary bandwidth will be reduced again. Through this operation, some things that are not so cyclical can be done, and the resource usage can be optimized.
5. Security compliance: system patch scanning and repair
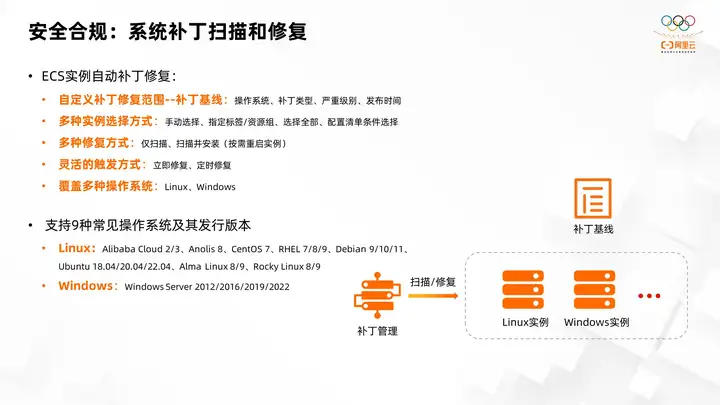
OOS also has many best practices in security compliance scenarios. One of the best practices is the patch management function provided: it can support the scanning and repair of system patches, and achieve automatic fixed repair of ECS instances.
First, patch management provides an out-of-the-box default fixed limit for each operating system, allowing more than 80% of users to achieve an out-of-the-box effect without configuration. For those users who have special requirements for installing patches, OOS also provides the option of using customized variable limits instead of the default fixed limits. You can do some filtering and filtering on the type, level, and release time of these operating system-level patches. filter. For example, if users have relatively high stability requirements, they may only install security operating systems and security-related patches. However, if the risk level is high, optimized patches such as enhancement or low-dimensional patches will not be installed. .
At the same time, users can also have requirements for the release time, which is relatively stable more than one week after installation and release. Because some patches are released and tested and found to have problems, they will be recycled. At this time, installing the patch immediately after it is released will bring some hidden dangers. When a patch is released and tested for a relatively long period of time, its stability is actually guaranteed to a certain extent.
In addition, patch management is also like some basic capabilities of OOS, supporting a variety of instance selection methods. Through this manual selection of tags, resource group selection, configuration list selection, and patch management are all supported. For this scenario, for example, in the resources, the user may have resources for the test environment and resources for the production environment.
The two resources may require different configuration and testing. Because its stability requirements may not be very high. So we can upgrade it every day. Install suitable patches as soon as they become available. The production environment has higher requirements on resource stability, so it needs to be done regularly every week. These can be achieved by selecting instances. In addition, patch management also supports a variety of repair methods, including scanning only. That is, it only scans out which ones are fixed and which ones need to be installed, but they are not actually installed. First check the specific patch installation status in the current instance.
In addition, it is to scan and install. At this time, it will not only scan for patches, but also install system patches with complex indefinite limits. For the more critical patches, they are windows patches or Linux and kernel patches. In some cases, it also requires restarting the instance to take effect. Users can say that after I install it, I will not restart the instance as needed. At this time, the patch has been installed, but it has not taken effect. Then the user can schedule a more appropriate time and an operation and maintenance window to restart the instance to make the patch take effect or restart the instance immediately after fixed installation to make it take effect. This can all be set in patch management.
Patch management also supports flexible punishment methods, such as immediate repair or scheduling periodic repairs. Patch management comes with a variety of current server operating systems, including Linux and Windows, which support 9 common operating systems. In addition to windows server, it also supports 8 types of linux servers. Its several versions include Alibaba Cloud, Anolis, CentOS, RHEL, Debian, Ubuntu, Alma Linux, Rocky Linux.
Through the patch management function, users can formulate and repair a batch of ecs instances, which can include Linux instances and Windows instances. Then the installation script of patch management will pull the corresponding patches according to the type of operating system in the instance. For example, Alibaba Cloud will take the corresponding patch period. If it is a Windows patch instance, the corresponding Windows patch machine will be pulled to install the patch and configure the scan.
6. Security compliance: Automatic repair of security compliance combined with configuration audit
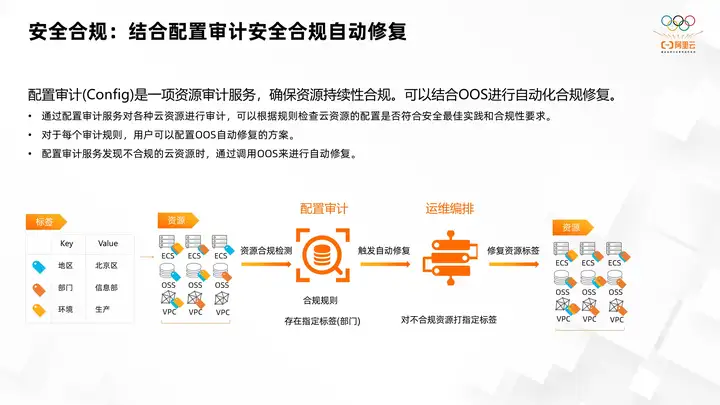
In addition, configuration audit is a resource audit service to ensure continued compliance of resources. Automated compliance remediation that can be combined with OOS is a resource-intensive service. Configure the audit service to discover non-compliant resources. By configuring audit services to audit various cloud resources, you can check whether the configuration of cloud resources complies with security best practices and compliance requirements based on these preset rules. For each audit rule, users can configure OOS's automatic repair scheme. Because by default, configuration audit will detect which of your resources are non-compliant and require you to manually repair them. Through the OOS automatic repair solution, manual repair can be avoided. Users can immediately trigger automatic repair when the configuration audit detects resource non-compliance.
Take the picture in the figure as an example. This is an innovation of cloud resource tags. You can see it on cloud resources. In fact, we have three types of labels, one is the regional label, the other is the department label, that is, the information department, and the other is the environmental label, such as the test environment and the production environment. You can see that each resource on ECS OOS and VPC is labeled differently. In configuring auditing, you can configure some compliance rule requirements.
For example, a rule was assigned today, which means that a designated label department must exist. Because the company will divide the costs according to departments. If you are not labeled as a department, I will not include you in the department when I divide the accounts. This will lead to inaccurate accounting, and it will be impossible to divide all costs into various departments. Therefore, the configuration audit will detect all resources and find that some resources are not labeled with departments. At this time he will record these resources. OOS triggers automatic repair, and according to preset rules, assigns specified labels to non-compliant resources and repairs the labels on the resources. At the same time, ecs labels all resources with department-related labels, which can ensure reasonable and accurate accounting.
4. Summary
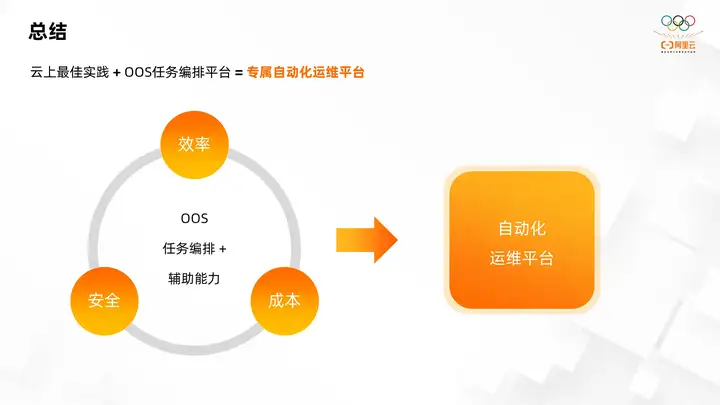
The cloud actually provides a variety of best practices, including the best time for resource operation and maintenance efficiency, resource cost, and resource security and security compliance. The OOS platform uses its powerful task orchestration capabilities and added assistance. Operation and maintenance capabilities can automate best practices on the cloud in many aspects. Users can create their own automated operation and maintenance platform based on OOS, the task orchestration platform and the best practices of each product on the cloud. The final development direction of OOS is to build its own platform capabilities, support more cloud resources by lowering the threshold of use, and automatically apply best practices to more cloud resource scenarios. Then users can build their own automated operation and maintenance platform more conveniently and efficiently based on the OOS platform.
This article is original content from Alibaba Cloud and may not be reproduced without permission.
Bilibili crashed twice, Tencent’s “3.29” first-level accident... Taking stock of the top ten downtime accidents in 2023 Vue 3.4 “Slam Dunk” released MySQL 5.7, Moqu, Li Tiaotiao… Taking stock of the “stop” in 2023 More” (open source) projects and websites look back on the IDE of 30 years ago: only TUI, bright background color... Vim 9.1 is released, dedicated to Bram Moolenaar, the father of Redis, "Rapid Review" LLM Programming: Omniscient and Omnipotent&& Stupid "Post-Open Source "The era has come: the license has expired and cannot serve the general public. China Unicom Broadband suddenly limited the upload speed, and a large number of users complained. Windows executives promised improvements: Make the Start Menu great again. Niklaus Wirth, the father of Pascal, passed away.