Contents of this article:
- 1. What are the characteristics of convolution?
- 2. What types of features are extracted by different levels of convolution?
- 3. How to select the convolution kernel size
- 4. Related concepts of convolution receptive field
- 5. Whether each layer of the network can only use one size of convolution kernel?
- 6.The role of 1*1 convolution
- 7. The role of transposed convolution
- 8. The role of atrous convolution
- 9. What is the checkerboard effect of transposed convolution?
- 10.What is the effective receptive field?
- 11. Related knowledge of group convolution
1. What are the characteristics of convolution?
Convolution has three main characteristics :
-
Local connection . Compared with full connection, partial connection will greatly reduce the parameters of the network. In two-dimensional images, local pixels are highly correlated, and designing local connections ensures the convolutional network's strong response to local features of the image.
-
Weight sharing . Parameter sharing can also reduce the overall parameter amount and enhance the efficiency of network training. The parameter weight of a convolution kernel is shared by the entire image, and the parameter weight within the convolution kernel will not change due to different positions in the image.
-
Downsampling . Downsampling can gradually reduce the image resolution, achieve dimensionality reduction of data, and combine shallow local features into deep features. Downsampling can also reduce the consumption of computing resources, speed up model training, and effectively control overfitting.
2. What types of features are extracted by different levels of convolution?
-
Shallow convolution → \rightarrow→ Extract edge features
-
Middle layer convolution → \rightarrow→ Extract local features
-
Deep convolution → \rightarrow→ Extract global features
3. How to select the convolution kernel size
The most commonly used is 3 × 3 3\times33×3 size convolution kernel, two3 × 3 3\times33×3 convolution kernels and a5 × 5 5\times55×The receptive fields of the 5 convolution kernels are the same, but the amount of parameters and calculations are reduced, speeding up model training. At the same time, due to the increase in convolution kernels, the nonlinear expression ability of the model is greatly enhanced.

However, large convolution kernels ( 7 × 7, 9 × 9 7\times7, 9\times97×7,9×9 ) There is also room for use. There are still many applications in GAN, image super-resolution, image fusion and other fields. You can check out relevant papers in the fields of interest as needed.
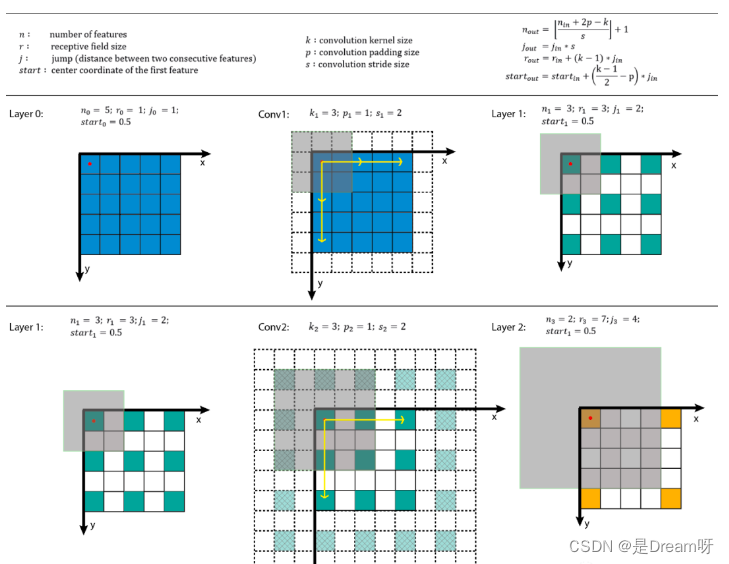
4. Related concepts of convolution receptive field
Many models of target detection and target tracking use the RPN layer. The anchor is the basis of the RPN layer, and the receptive field (RF) is the basis of the anchor.
The role of receptive fields:
-
Generally speaking, the larger the receptive field, the better. For example, the receptive field of the last convolutional layer in a classification task should be larger than the input image.
-
When the receptive field is large enough, less information is ignored.
-
In the target detection task, the anchor must be aligned with the receptive field. If the anchor is too large or deviates from the receptive field, it will have a certain impact on performance.
Receptive field calculation:
Ways to increase the receptive field:
-
Use atrous convolution
-
Use pooling layer
-
Increase the convolution kernel
5. Whether each layer of the network can only use one size of convolution kernel?
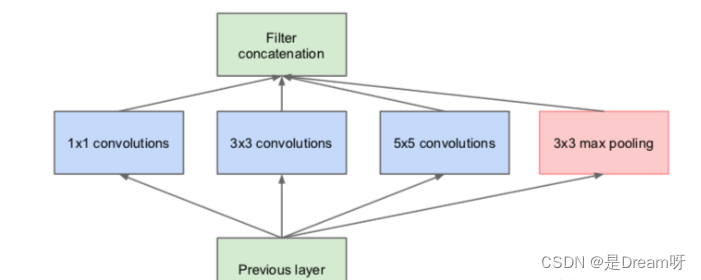
Conventional neural networks generally use only one size of convolution kernel for each layer, but the feature map of the same layer can use multiple convolution kernels of different sizes to obtain features of different scales , and then combine these features to obtain Features are often better than those using a single size convolution kernel. For example, GoogLeNet and Inception series networks use multiple different convolution kernel structures in each layer. As shown in the figure below, the input feature map passes through
1 × 1 1\times 1 in the same layer.1×1,3 × 3 3\times33×3 and5 × 5 5\times55×5 Three different sizes of convolution kernels, and then integrating their respective feature maps, the new features obtained can be regarded as a combination of features extracted from different receptive fields, which will have stronger expressive power than a single size convolution kernel.
6.The role of 1*1 convolution
1 ∗ 1 1 * 1 1∗1The main functions of convolution are as follows:
-
Realize the interaction and integration of feature information.
-
Dimensionally increase and decrease the number of feature map channels. When reducing the dimensionality, the number of parameters can be reduced.
-
1 ∗ 1 1*1 1∗1 convolution + activation function→ \rightarrow→ Increase nonlinearity and improve network expression capabilities.
1 ∗ 1 1 * 11∗1 Convolution was first used in NIN (Network in Network), and was later used in networks such as GoogLeNet and ResNet. Interested friends can track the details of these paper studies.
7. The role of transposed convolution
Transposed convolution learns the optimal upsampling method through the training process to replace the traditional interpolation upsampling method to improve the performance of specific tasks such as image segmentation, image fusion, and GAN.
Transpose convolution is not the reverse operation of convolution. From the perspective of information theory, the convolution operation is irreversible. Transposed convolution can restore the output feature map size to the feature map size before convolution, but does not restore the original value.
The calculation formula of transposed convolution:
We set the convolution kernel size to be K × KK\times KK×K , the input feature map isi × ii \times ii×i 。
(1)当 s t r i d e = 1 , p a d d i n g = 0 stride = 1,padding = 0 stride=1,padding=0 hours:

The input feature map is equivalent to padding = K − 1 when performing a transposed convolution operation. padding = K − 1padding=K−1 padding, followed by standard convolution operations after normal convolution transposition.
The size of the output feature map = i + ( K − 1 ) i + (K − 1)i+(K−1)
(2)当 s t r i d e > 1 , p a d d i n g = 0 stride > 1,padding = 0 stride>1,padding=0 hours:
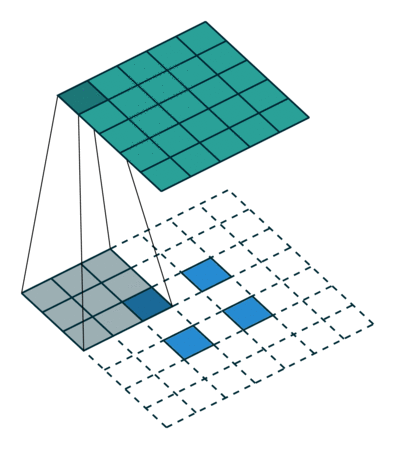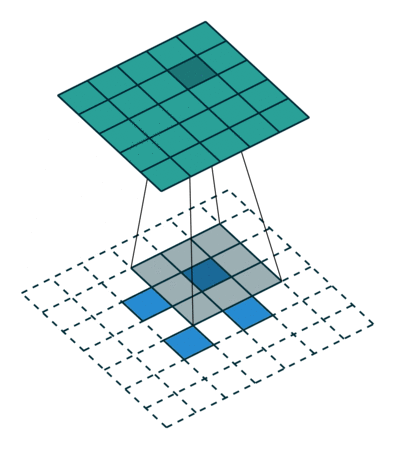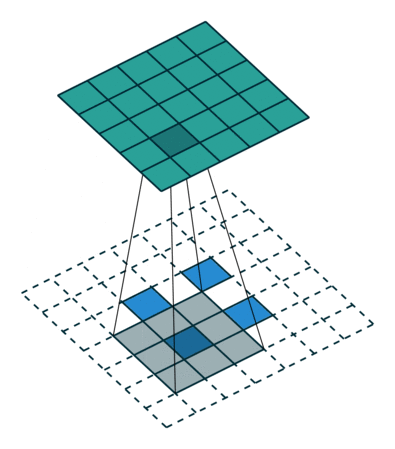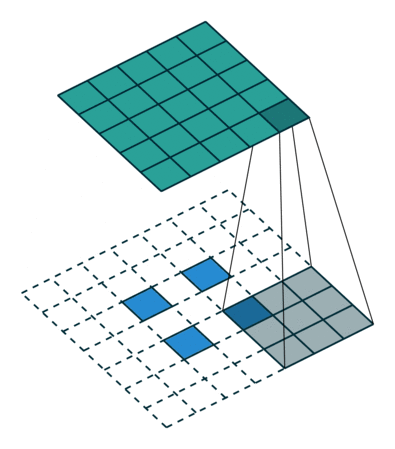
The input feature map is equivalent to padding = K − 1 when performing a transposed convolution operation. padding = K − 1padding=K−1 padding, the size of the hole between adjacent elements isstride − 1 stride − 1stride−1 , and then perform the standard convolution operation after the normal convolution transpose.
The size of the output feature map = stride ∗ ( i − 1 ) + K stride * (i − 1) + Kstride∗(i−1)+K
8. The role of atrous convolution
The function of dilated convolution is to increase the receptive field without losing information through pooling operations, so that each convolution output contains a larger range of information .
Atrous convolution has a parameter to set the dilation rate, which fills the dilation rate with zeros in the convolution kernel. Therefore, when different dilation rates are set, the receptive fields will be different, and multi-scale information is obtained.
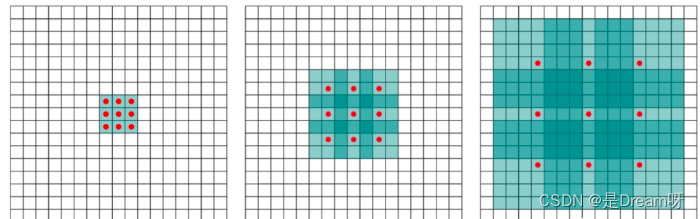
(a) The picture corresponds to 3 × 3 3\times33×The 1-dilated conv of 3 is the same as the ordinary convolution operation. (b) The picture corresponds to3 × 3 3\times33×For 2-dilated conv of 3 , the actual convolution kernel size is still3 × 3 3\times33×3 , but the hole is1 11 , that is, for a7 × 7 7\times77×Image patch for 7 , only 9 99 red dots and3 × 3 3\times33×The convolution operation occurs in kernel 3 , and the weights of the remaining points are0 00 . ©Figure is a 4-dilated conv operation.
9. What is the checkerboard effect of transposed convolution?

The cause of the checkerboard effect is the uneven overlap of transposed convolutions. This overlap causes some parts of the image to be darker than others.
The figure below shows the formation process of the checkerboard effect. The dark part represents the uneven overlap:
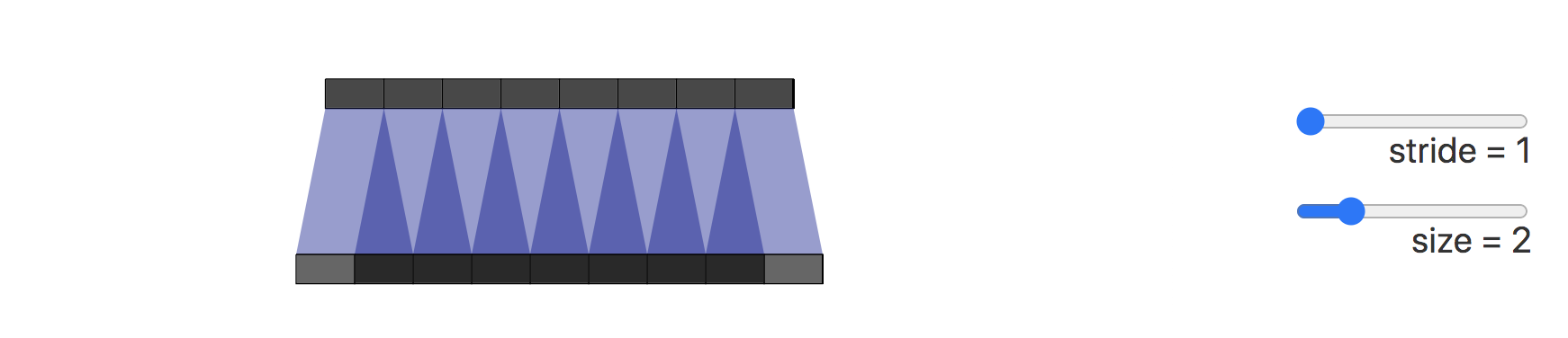
Next, we change the convolution step size to 2. We can see that all pixels on the output image receive the same amount of information from the input image. They all receive one pixel of information from the input image, so there is no conversion. The overlapping area caused by volume placement.

We can also directly perform the interpolation Resize operation, and then perform the convolution operation to eliminate the checkerboard effect. This method is more common in super-resolution reconstruction scenarios. For example, methods such as bilinear interpolation and nearest neighbor interpolation are used for upsampling.
10.What is the effective receptive field?
Relevant knowledge about receptive fields was introduced in Section 4 above.
Let's take a look at the relevant knowledge of the effective receptive field (ERF).
Generally speaking, the effective receptive field on the feature map is smaller than the actual receptive field. Its effectiveness, based on the center point, decreases toward the edges like a Gaussian distribution.
In general, the receptive field mainly describes the maximum amount of information in the feature map, and the effective receptive field mainly describes the effectiveness of the information.
11. Related knowledge of group convolution
Group Convolution (Group Convolution) first appeared in the AlexNet network. Group Convolution is used to split the network so that it can run in parallel on multiple GPUs.

When performing ordinary convolution operations, if the input feature map size is C × H × WC\times H \times WC×H×W , there are N convolution kernels, then the output feature map is the same as the number of convolution kernels, which is also N. The size of each convolution kernel isC × K × KC\times K \times KC×K×K , the total parameters of N convolution kernels areN × C × K × KN \times C \times K \times KN×C×K×K 。
Grouped convolution mainly groups the input feature maps, and then each group is convolved separately. If the input feature map size is C × H × WC\times H \times WC×H×W , the number of output feature maps isNNN , if we set it to be divided into G groups, the number of input feature maps for each group isCG \frac{C}{G}GC, then the number of output feature maps in each group is NG \frac{N}{G}GN, the size of each convolution kernel is CG × K × K \frac{C}{G} \times K \times KGC×K×K , the total number of convolution kernels is still N, and the number of convolution kernels in each group isNG \frac{N}{G}GN, the convolution kernel only convolves with the input map of the same group. The total parameter amount of the convolution kernel is N × CG × K × KN \times \frac{C}{G} \times K \times KN×GC×K×K ,it is easy to get that the total number of parameters is reduced to the original 1 G \frac{1}{G}G1 。
The role of grouped convolution:
- Grouped convolution can reduce the number of parameters.
- Grouped convolution can be regarded as a sparse operation, which can sometimes achieve better results with a smaller number of parameters (equivalent to a regularization operation).
- When the number of groups is equal to the number of input feature map channels and the number of output feature maps is also equal to the number of input feature maps, group convolution becomes Depthwise convolution, which can further reduce the amount of parameters.