

Recommendation systems (recommendation engines) are a type of application that predict and push items (services) that users currently need or are interested in based on information such as user behavior and points of interest. Common recommendation systems include movie, book, music or news article recommendation systems.
Based on different algorithms or technologies, there are many types of recommendation systems, such as collaborative filtering recommendation systems, content-based recommendation systems, hybrid recommendation systems and vector-based recommendation systems. Among them, vector-based recommendation systems use vector space to find (i.e., recommend) the most similar products or content in the database. The most effective way to store vector data is to use the world's leading vector database like Milvus.
This article will introduce how to use Milvus and Python to build a movie recommendation system. During the construction process, we will use SentenceTransformers to convert text information into vectors and store these vectors in Milvus. Once set up, users can enter a description and search for similar movies in the recommendation system. For all the code in this tutorial, refer to:
Milvus Bootcamp repository on GitHub (https://github.com/milvus-io/bootcamp)
Jupyter Notebook(https://github.com/milvus-io/bootcamp/blob/master/solutions/nlp/recommender_system/recommender_system.ipynb)

01.
Set up the environment
Before you begin, please install:
Python 3.x
Python Package Manager (PIP)
Jupyter Notebook
Docker
Hardware system with at least 32 GB RAM or Zilliz Cloud account
Install required tools and software using Python
$ python -m pip install pymilvus pandas sentence_transformers kaggleVector database Milvus
In this tutorial we will use Milvus to store the Embedding vector converted from the movie information. Since the data set used is large, it is recommended that you create a Zilliz Cloud (https://cloud.zilliz.com.cn/signup) cluster to store the vector database. But if you still want to install a local instance, you can download the docker-compose configuration file and run the file.
$ wget https://github.com/milvus-io/milvus/releases/download/v2.3.0/milvus-standalone-docker-compose.yml -O docker-compose.yml
$ docker-compose up -d
Once everything is ready, you can build a movie recommendation system!
02.
Prepare and preprocess data
First, we chose to use the movie dataset (https://www.kaggle.com/datasets/rounakbanik/the-movies-dataset) on Kaggle (https://www.kaggle.com/), which contains 45,000 Movie metadata information. You can download the data set directly or use the Kaggle API through Python to download the data set. If you want to download via Python, please first download the kaggle.json file in Kaggle.com's Profile (https://www.kaggle.com/docs/api). Notice! Be sure to store this file in a path that is accessible to the API.
Next, set environment variables to authenticate to Kaggle. Open Jupyter Notebook and enter the following code:
%env KAGGLE_USERNAME=username
%env KAGGLE_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
%env TOKENIZERS_PARALLELISM=true
Use Kaggle's Python dependency to download the movie data set on Kaggle:
import kaggle dependency
import kaggle
kaggle.api.authenticate()
kaggle.api.dataset_download_files('rounakbanik/the-movies-dataset', path='dataset', unzip=True)
After the data set is downloaded, use pandas read_csv()to read the data set:
import pandas
import pandas as pd
read csv data
movies=pd.read_csv('dataset/movies_metadata.csv',low_memory=False)
check shapeof data
movies.shape

The above figure shows that 45466 pieces of movie metadata were read. Each piece of movie data contains 24 columns. Use the following command to view information for all columns:
check column names
movies.columns

When building a movie recommendation system, you don't need to use all the columns. Filter the columns we need with the following code:
filter required columnstrimmed_movies = movies[["id", "title", "overview", "release_date", "genres"]]
trimmed_movies.head(5)
Additionally, some fields are missing from some data. Delete data for these missing fields:
unclean_movies_dict = trimmed_movies.to_dict('records')
print('{} movies'.format(len(unclean_movies_dict)))
movies_dict = []for movie in unclean_movies_dict:if movie["overview"] == movie["overview"] and movie["release_date"] == movie["release_date"] and movie["genres"] == movie["genres"] and movie["title"] == movie["title"]:
movies_dict.append(movie)
03.
Building process
Connect with Milvus
After processing the data, connect to the Milvus cluster to import the data. We need to use URI and token to connect to the Milvus cluster, this information can be found on the Zilliz Cloud interface.
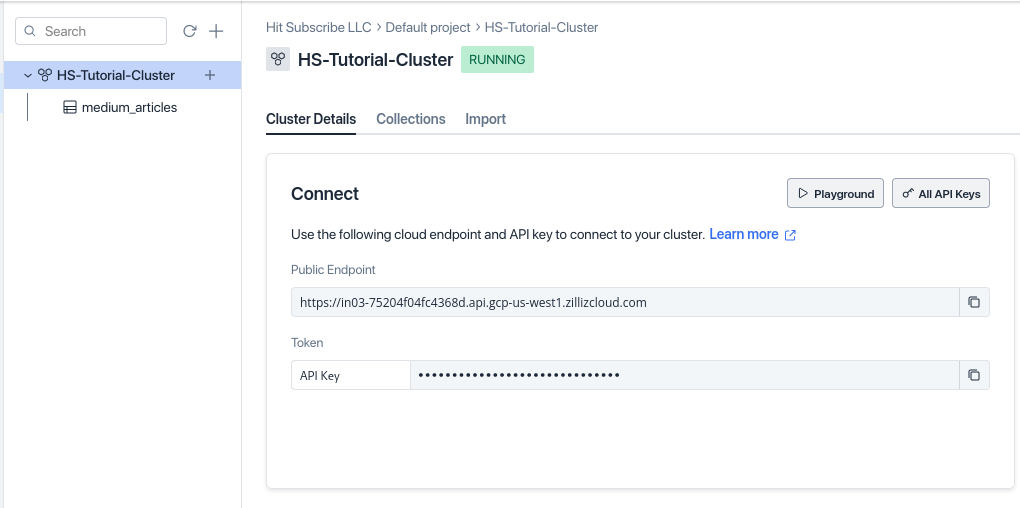
Use the following command to connect to the Milvus server through PyMilvus (https://pypi.org/project/pymilvus/):
import milvus dependencyfrom pymilvus import *
connect to milvusmilvus_uri="YOUR_URI"token="YOUR_API_TOKEN"
connections.connect("default", uri=milvus_uri, token=token)
print("Connected!")
Convert movie information into Embedding vectors
Next, convert the movie data set into Embedding vectors. First, create a Collection to store movie IDs and movie information vectors. Indexes can also be added when creating a Collection to make subsequent searches more efficient:
COLLECTION_NAME = 'film_vectors'
PARTITION_NAME = 'Movie'Here's our record schema"""
"title": Film title,
"overview": description,
"release_date": film release date,
"genres": film generes,
"embedding": embedding
"""
id = FieldSchema(name='title', dtype=DataType.VARCHAR, max_length=500, is_primary=True)
field = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=384)
schema = CollectionSchema(fields=[id, field], description="movie recommender: film vectors", enable_dynamic_field=True)
if utility.has_collection(COLLECTION_NAME): # drop the same collection created before
collection = Collection(COLLECTION_NAME)
collection.drop()
collection = Collection(name=COLLECTION_NAME, schema=schema)
print("Collection created.")
index_params = {"index_type": "IVF_FLAT","metric_type": "L2","params": {"nlist": 128},
}
collection.create_index(field_name="embedding", index_params=index_params)
collection.load()
print("Collection indexed!")
After the Collection is created, you need to write a function to generate vectors. The movie vector will contain information such as movie introduction, movie type, release date, etc. Use SentenceTransformer to generate vectors:
from sentence_transformers import SentenceTransformer
import ast
function to extract the text from genre columndef build_genres(data):
genres = data['genres']
genre_list = ""
entries= ast.literal_eval(genres)
genres = ""for entry in entries:
genre_list = genre_list + entry["name"] + ", "
genres += genre_list
genres = "".join(genres.rsplit(",", 1))return genres
create an object of SentenceTransformer
transformer = SentenceTransformer('all-MiniLM-L6-v2')
function to generate embeddingsdef embed_movie(data):
embed = "{} Released on {}. Genres are {}.".format(data["overview"], data["release_date"], build_genres(data)) embeddings = transformer.encode(embed)return embeddings
The above function uses build_genres()clear movie style and extracts text. Then a SentenceTransformer object is created to generate text vectors. Finally, encode()the movie vector is generated using the method.
Import vectors into Milvus
Because the data set is too large, inserting data into Milvus one by one is inefficient and will result in increased network traffic. Therefore, we recommend importing data into Milvus in batches, with 5,000 pieces of data imported in one batch.
Loop counter for batching and showing progressj = 0batch = []
for movie_dict in movies_dict:
try:
movie_dict["embedding"] = embed_movie(movie_dict)batch.append(movie_dict)
j += 1
if j % 5 == 0:
print("Embedded {} records".format(j))
collection.insert(batch)
print("Batch insert completed")batch=[]
except Exception as e:
print("Error inserting record {}".format(e))
pprint(batch)
break
collection.insert(movie_dict)
print("Final batch completed")
print("Finished with {} embeddings".format(j))Note: You can adjust the amount of data uploaded in batches according to your preferences and needs. At the same time, some movies may fail to import because their IDs cannot be converted to integers. We can adjust the Schema accordingly or check the data format to avoid import failures .

04.
Search and recommend movies with Milvus
To use Milvus' near-real-time vector search capabilities to recommend suitable movies to users, create the following two functions:
embed_search()Use Transformer to convert user search text (string) into Embedding vector. Transformer is the same as before.search_for_movies()Used to perform vector similarity searches.
load collection memory before search
collection.load()
Set search parameters
topK = 5
SEARCH_PARAM = {
"metric_type":"L2",
"params":{"nprobe": 20},
}
convertsearch string to embeddings
def embed_search(search_string):
search_embeddings = transformer.encode(search_string)return search_embeddings
search similar embeddings for user's query
def search_for_movies(search_string):
user_vector = embed_search(search_string)
return collection.search([user_vector],"embedding",param=SEARCH_PARAM, limit=topK, expr=None, output_fields=['title', 'overview'])
In the above code, we set the following parameters:
Top-K :
topK = 5, stipulates that the search will return the 5 most similar vectorsSimilarity type :
metric_typeSet to Euclidean distance (Euclidean/L2) https://iq.opengenus.org/euclidean-distance/nprobe : Set to 20, specifying the search for 20 data clusters
Finally, use search_for_movies()the function to recommend related movies based on user searches:
from pprint import pprint
search_string = "A comedy from the 1990s set in a hospital. The main characters are in their 20s and are trying to stop a vampire."
results = search_for_movies(search_string)
check resultsfor hits in iter(results):for hit in hits:print(hit.entity.get('title'))print(hit.entity.get('overview'))print("-------------------------------")

The picture above shows that 5 similar movies were found. So far, we have successfully built a movie recommendation system using Milvus.
This article was originally published on The New Stack and has been reproduced with permission.


本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。