Shared todayAI seriesIn-depth research report: "AI large model special report: AI large The accelerated implementation of models and applications continues to drive the development of the computing industry chain》.
(Report produced by: Great Wall Securities)
Total report: 23 pages

1. Industry perspective
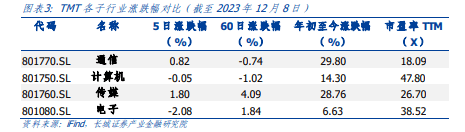
Among the TMT sub-sectors: electronics, communications, media and computers, communications ranked second in terms of weekly growth.
1.1 A quick overview of this week’s strategic views
1.1.1 Google AI large model Gemini has not been released yet, and continues to be optimistic about investment opportunities in the computing power industry chain
On December 6, Google CEO Pichai and DeepMind CEO Hassabis jointly issued a document on Google's official website saying that they would officially launch the large AI model Gemni, and launch three different sizes of optimized models for Gemini1.0: GeminiUtraGeminiPro and Gemini Nano, Gemini As a multi-modal large model rebuilt by Ge, it can summarize and seamlessly understand, operate and combine different types of information, including text, code, audio, images and video, and can satisfy a variety of terminals from data centers to mobile devices. efficient operation. Google is actively promoting the application of Gemini, working hard to further expand various functions in future versions, and accelerating the launch of Bard, Pixel 8 Pro and other products. It is expected to provide Gemini Ultra to developers and enterprise customers in early 2024. In addition, my country is responding to multi-mode In response to this technology development trend, cloud vendors, innovative companies, AI companies, big data companies, and traditional software companies are all actively deploying multi-modal technology research and development and application.
We believe that computing power is the key cornerstone of multi-modality. As manufacturers at home and abroad actively promote multi-modal technology, the current demand for computing power is expected to continue, driving the development of the computing power infrastructure industry, and related industry chains are expected to continue. benefit
1.1.2 AMD releases chips specially designed for sharp-walled artificial intelligence, and the domestic AI chip industry continues to develop
On December 6, AMD released two products, Instinct MI300X and Instinct M300A, a series of chips specially designed for cutting-edge artificial intelligence, marking the world's first data center-level APU accelerated processing unit at the "Advancing Artificial Intelligence" event. Launched to seize the growing opportunities in the field of generative artificial intelligence and high-performance computing, the MI300 series of products is a multi-chip combination created by AMD using cutting-edge production technology and innovative "3.5D" packaging technology. . The company claims that the performance of this series of products exceeds that of competitor Nvidia when performing various artificial intelligence tasks. During the event, AMD and a number of partners jointly emphasized the strong application and performance of the AMD Instinct data center artificial intelligence accelerator during the event. Growth momentum, among which partners include: Microsoft, Meta, Oracle, Dell, Lenovo and other technology giants.
We believe that as domestic and foreign technology giants accelerate the progress of large-scale multi-modal capabilities, domestic manufacturers continue to accelerate the delivery of product technology capabilities and are expected to solve the current supply problem of strong computing power demand from the upstream. Localized substitution may continue to labor computing power. Infrastructure industry development.
2. Analysis of this week’s topic
2.1 Google AI large model Gemini is released, continuing to be optimistic about investment opportunities in the computing power industry chain
2.1.1 Google Gemini capabilities are progressing rapidly, and multi-modal capabilities have been greatly improved.
On December 6, Google CEO Pichai and DeepMind CEO Hassabis jointly issued a document on Google’s official website saying that they would officially launch the large AI model Gemni, and launch three different sizes of optimized models for Gemini1.0: GeminiUltra.GeminiPro and GeminiNanoGemini as Google's rebuilt multi-modal large model can summarize and seamlessly understand, operate and combine different types of information, including text, code, audio, images and video, and can meet the needs of multiple terminals from data centers to mobile devices. Business efficiency operation.
Founded in 2010, DeepMind takes an interdisciplinary approach to building general artificial intelligence systems, bringing together new ideas and advances in machine learning, neuroscience, engineering, mathematics, simulation and computational infrastructure, as well as new ways of organizing scientific work . DeepMind's mission is to responsibly build artificial intelligence to benefit humanity. Its vision is to create breakthrough technologies that advance science, change the way work is done, serve diverse communities, and improve billions of people by solving the tough scientific and engineering challenges of our time. human life. In 2015, DeepMind released the first computer program AhaGo to defeat the world champion of Go, ushering in a new era of artificial intelligence. Its subsequent versions AhaZero and MuZero are becoming more and more versatile, capable of compressing videos and even discovering new and more efficient ones. Computer algorithms, in addition, the company's use of large language models in robotic systems through PaLMSayCan and the creation of more general visual language action models through RT-2 have promoted the development of robotics. Today DeepMind is actively leveraging its advanced computing infrastructure , continue to promote the creation of the next wave of research breakthroughs and transformative products, and continue to create the realization of the company's vision.
Gemini is the result of a collaboration between teams across Google, including Google Research. The model was created from the beginning as a multi-modal model that can inductively and fluently understand, manipulate and combine different types of information, including text, Code, audio, images and video. Gemini can run efficiently from the data center to mobile devices, and its advanced capabilities will significantly improve the way developers and enterprise customers build and scale with AI. The company optimized the first-generation Gemini 1.0 for three different sizes:
✓ Gemini Ultra — Google’s largest and most powerful model, suitable for highly complex tasks.
✓ Gemini Pro — Google’s best model for a variety of tasks.
✓ Gemini Nano — the most efficient model on Google’s end-to-end devices.

The standard approach to creating multimodal models is to train components of different modalities separately and then stitch them together to roughly simulate some functionality. These models sometimes work well at specific tasks such as describing images, but fail at more conceptual and complex reasoning. Google designed Gemini to be natively multi-modal and pre-trained on different modalities from the beginning. Fine-tuning it with additional multimodal data to further improve its effectiveness helps Gemini understand and reason smoothly from the earliest stages of input. Gemini 1.0 mainly has the following three major highlights:
1. Complex multi-modal reasoning capabilities:Gemini 1.0 can help understand complex written and visual information, and can discover difficult-to-discern knowledge content in massive data. The ability to read, filter, and understand information to extract insights from hundreds of thousands of documents will help enable new breakthroughs at digital speed in fields ranging from science to finance.
2. Ability to understand text, images, audio, etc.:Gemini 1.0 is trained to recognize and understand text, images, audio, etc. at the same time, so it can better understand subtle Differentiate information, answer questions related to complex topics, and are particularly good at explaining reasoning in complex subjects such as mathematics and physics.

3. Advanced coding skills:Gemini can understand, interpret and generate high-quality code in programming languages, including Python, Java, C++ and Go, and can work across languages and Reasoning about complex information makes it one of the world's leading coding foundation models. Gemini Ultra performs well on several coding benchmarks, including HumanEval (an important industry standard for evaluating performance on coding tasks) and Natural2Code (Google's internal set-out dataset), where Natural2Code uses author-generated information as a source rather than Web-based information. Gemini can also be used as an engine for more advanced encoding systems. Using a specialized version of Gemini, Google created AlphaCode 2, a more advanced code generation system that excels at solving competitive programming problems that require not only coding skills but also knowledge of complex mathematics and theoretical computer science.
When evaluated on the same platform as the original AlphaCode, AlphaCode 2 showed huge improvements, solving nearly twice as many problems as AlphaCode, and Google projected that it would outperform 85% of entrants, outperforming AlphaCode. Nearly 50%. AlphaCode 2 performs even better when programmers work with AlphaCode 2 and define certain properties for the sample code.

2.1.2 Google continues to improve its self-research capabilities and steadily promotes the application of Gemini large models
Gemini 1.0 is trained at scale on Google-designed TPUs v4 and v5e on AI-optimized infrastructure. On TPUs, Gemini runs significantly faster than earlier smaller, weaker models, and its custom-designed AI accelerator has been at the core of Google's AI-enabled products that serve billions of users, including search, YouTube, Gmail, Google Maps, Google Play, and Android help companies around the world cost-effectively train large-scale AI models. The company also released one of the most powerful, efficient and scalable TPU systems to date: Cloud TPU v5p, designed to support training cutting-edge AI models. The new generation of TPU will accelerate the development of Gemini and help developers and enterprise customers train large-scale generative AI models faster, thereby launching new products and features faster.

Google is actively promoting the application of Gemini and working hard to further expand various functions in future versions:
➢ Gemini is implemented in various Google products: Bard will use a fine-tuned version of Gemini Pro for more advanced reasoning, planning and understanding, etc., and will provide English services in more than 170 countries and regions. Google plans to expand different products in the next few months. Modalities, and support for new languages and regions. In addition, Google also ships Gemini on Pixel. Pixel 8 Pro is the first smartphone equipped with Gemini Nano, which can support new functions such as "summary" in the recording application, and launch the "smart reply" function in Gboard. Google expects to launch more messaging applications in 2024. In the coming months, Gemini will be used in more Google products and services, such as search, ads, Chrome browser and Duet AI. The company has begun experimenting with Gemini in search to provide users with a faster search generation experience.

✓ Gemini helps developers build their own products: Starting December 13, developers and enterprise customers can get Gemini Pro through the Gemini API in Google AI Studio or Google Cloud Vertex AI. Google AI Studio is a free web-based developer tool that allows you to quickly prototype and launch applications using API keys. When a fully managed AI platform is required, Vertex AI allows Gemini to be customized to provide comprehensive data control while benefiting from the capabilities of Google Cloud for enterprise security, confidentiality, privacy, and data governance and compliance. . Android developers can also use Gemini Nano, Google’s most efficient model for end-to-end tasks, through AICore, a new system feature in Android 14.

✓ Continue to promote the implementation of Gemini Ultra: Google is currently completing a series of security checks, including red team testing by an external team, and further improving the model through fine-tuning and reinforcement learning with human feedback (RLHF) before it is widely used. As the model is refined, the company will make Gemini Ultra available to select customers, developers, partners, and security experts for early testing and feedback. Google expects to make the model available to developers and enterprise customers in early 2024. . In addition, the company will launch Bard Advanced, a new, cutting-edge AI experience that gives users access to the company’s best models and features, starting with Gemini Ultra.
2.1.3 AI is transforming towards multi-modality, and computing power continues to be in demand
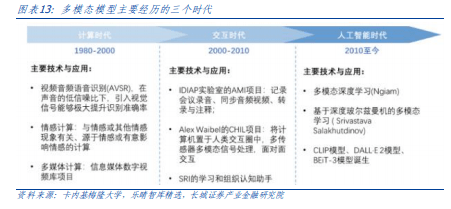
Three major factors lead to the inevitability of AI models becoming multimodal: cross-modal task requirements + cross-modal data fusion + simulation of human cognitive abilities. According to Le Jing Think Tank, multi-modal learning is based on multi-modal large-scale data, and uses multiple senses to learn at the same time, providing richer information. In addition to the traditional interaction of language and images, it combines sound, sensory and multi-dimensional information such as actions for deep learning to form a more accurate and expressive multi-modal representation. Compared with single-modality, multi-modal models handle multiple data inputs and are more complex in structure. They may involve using multiple sub-networks and then combining their outputs. The core of multi-modal models is to process and integrate these different types of data. Data sources, such models can capture complex relationships across modalities, enabling machines to more fully understand and analyze information to perform better in a variety of tasks.
Multimodal models can be divided into three main development stages based on technical iterations. From 2010 to the present, deep learning has brought huge impetus to multimodal research, and multimodal models have reached unprecedented accuracy and complexity. This stage benefits from four key factors:
1) Large-scale multi-modal data sets;
2) More powerful computing power;
3) Researchers have also begun to master more advanced visual feature extraction technology; 4) Powerful language feature extraction models have emerged including the Transformer architecture.
In 2023, according to data from the Financial Associated Press, a number of multi-modal AI applications have made stunning debuts, including Pika and three major photo-to-video applications: Animate Anyone by Alibaba, Magic Animate by ByteDance, and GAIA by Microsoft. On November 29, according to the official website of Electronic Enthusiasts, American AI startup Pika labs released a new Vincent video product Pika 1.0. This product can generate and edit 3D animation, animation, cartoons and movies. Making videos with Pika 1.0 requires almost no threshold. Users only need to enter a sentence to generate videos of various styles they want, and change the image and style in the video through a simple description.

In addition, a number of technology companies have also made new progress in the field of Wensheng video, including: Meta publishing tool EmuVideo, which can generate video clips based on text and image input; Runway launched the Motion Brush dynamic brush function in Gen2, which simply touches the Just swipe anywhere on the image to make all stationary objects move; Stable AI launches Stable Video Dffusion, which can generate high-quality video clips from images.
According to IDC data, in response to the technology development trend of multi-modality in my country, cloud vendors, innovative companies, AI companies, big data companies and traditional software companies are actively deploying multi-modal technology research and development and application. These companies and institutions are actively developing multi-modal technologies. Modal manufacturers play different roles in the ecosystem and jointly promote the development of multi-modal technology through mutual cooperation and complementary advantages.

According to IDC data, the scale of my country’s intelligent computing power is growing rapidly. In 2021, the scale of my country's intelligent computing power will reach 155.2 exascale floating-point operations per second (EFLOPS). In 2022, the scale of intelligent computing power will reach 268.0 EFLOPS. It is expected that by 2026, the scale of intelligent computing power will reach 10 trillion EFLOPS. Floating point calculation (ZFLOPS) level, reaching 1,271.4 EFLOPS. It is expected that the compound annual growth rate of my country's intelligent computing power will reach 52.3% during 2021-2026, and the compound annual growth rate of general computing power during the same period will be 18.5%.

2.2 AMD releases chips designed specifically for cutting-edge artificial intelligence, and the domestic AI chip industry continues to develop
2.2.1 AMD releases MI300 series chips, surpassing Nvidia in many performance tests
On December 6, AMD released two products, Instinct MI300X and Instinct MI300A, during the “Advancing Artificial Intelligence” event, marking the launch of the world’s first data center-level APU (accelerated processing unit), aiming to capture Seize the growing opportunities in generative artificial intelligence and high-performance computing. The MI300 series of products is a multi-chip combination created by AMD using cutting-edge production technology and innovative "3.5D" packaging technology. The company claims that the performance of this series of products exceeds that of rival Nvidia when performing various artificial intelligence tasks.
AMD Instinct MI300A APU: APU designed for high-performance computing (HPC)
The AMD Instinct MI300A APU is designed to handle large data sets and is ideal for compute-intensive modeling and advanced analytics. The MI300A uses an innovative 3D chipset design that integrates 3D stacked "Zen 4" x86 CPU and AMD CDNA 3 GPU XCD into the same package and is equipped with high-bandwidth memory (HBM). The AMD Instinct MI300A APU has 24 CPU cores and 14,592 GPU stream processors. This advanced architecture delivers breakthrough performance, density and energy efficiency to the MI300A accelerator, which is ideally suited to accelerating high-performance computing (HPC) and artificial intelligence applications and is expected to be used by the world's largest and most scalable data centers and supercomputers. Utilized to advance discovery, modeling and forecasting in healthcare, energy, climate science, transportation, scientific research and more, including for the upcoming 200 petaflops, expected to be one of the fastest in the world Powered by the El Capitan supercomputer.

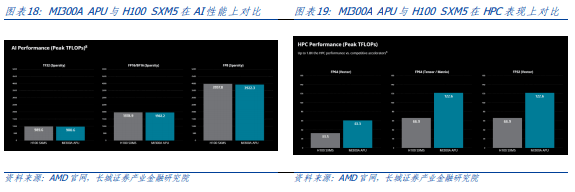
From a performance perspective, although the AMD MI300A APU's AI performance is slightly lower than its competing product, the Nvidia H100 SXM5, from the HPC performance results, it is significantly higher than the H100 SXM5, up to 1.8 times.
AMD Instinct MI300X Accelerator: Designed for Cutting-Edge Artificial Intelligence
AMD Instinct MI300X accelerator is designed for large language models and other cutting-edge artificial intelligence applications that require training on large-scale data sets and inference at scale. To achieve this, the MI300X builds on the MI300A by replacing three "Zen 4" CPU chipsets with two additional AMD CDNA 3 XCD chipsets and adding 64GB of HBM3 memory. With up to 192GB of memory, an optimized GPU is created capable of running larger AI models. Running larger language models directly in memory allows cloud service providers and enterprise users to run more inference tasks on each GPU than ever before, thereby reducing the total number of GPUs required, accelerating inference performance, and helping reduce overall ownership costs. cost (TCO).

Total report: 23 pages