data driven
In unittest, is it possible to use reading data files to implement parameterization? sure. Here to read CSV
file as an example. Create a baidu_data.csv file, as shown in the figure:
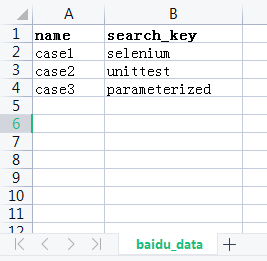
The first column of the file is the test case name, and the second column is the search keyword. Next create the test_baidu_data.py file.
# _*_ coding:utf-8 _*_
"""
name:zhangxingzai
date:2023/3/19
"""
import csv
import codecs
import unittest
from time import sleep
from itertools import islice
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestBaidu(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Firefox()
cls.base_url = "https://www.baidu.com"
@classmethod
def tearDownClass(cls):
cls.driver.quit()
def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element(By.ID, "kw").send_keys(search_key)
self.driver.find_element(By.ID, "su").click()
sleep(3)
def test_search(self):
with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f:
data = csv.reader(f)
for line in islice(data, 1, None):
search_key = line[1]
self.baidu_search(search_key)
if __name__ == '__main__':
unittest.main(verbosity=2)There seems to be no problem with this. It is indeed possible to read the three pieces of data in the baidu_data.csv file and test it.
The test results are as follows:
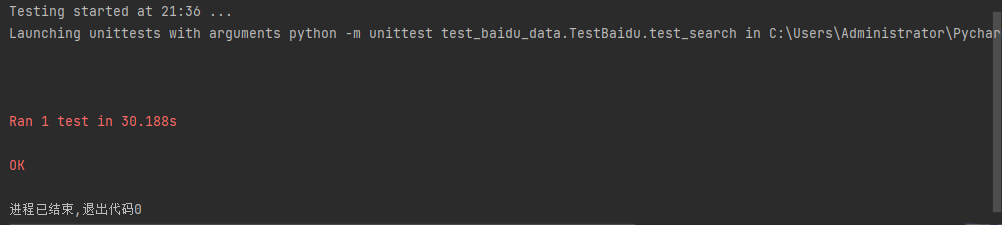
Based on the results, this division is unreasonable. For example, if there are 10 pieces of data, as long as one piece of data fails to execute, then the entire test will use
The execution of the example failed. Therefore, it is more appropriate for 10 pieces of data to correspond to 10 test cases, even if the test case for 1 piece of data
If the test case execution fails, it will not affect the execution of the other 9 data test cases, and when locating the test case failure
The reasons for failure will be simpler. Modify the code as follows:
# _*_ coding:utf-8 _*_
"""
name:zhangxingzai
date:2023/3/19
"""
import csv
import codecs
import unittest
from time import sleep
from itertools import islice
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestBaidu(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Firefox()
cls.base_url = "https://www.baidu.com"
cls.test_data = []
with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f:
data = csv.reader(f)
for line in islice(data, 1, None):
cls.test_data.append(line)
@classmethod
def tearDownClass(cls):
cls.driver.quit()
def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element(By.ID, "kw").send_keys(search_key)
self.driver.find_element(By.ID, "su").click()
sleep(3)
def test_search_selenium(self):
self.baidu_search(self.test_data[0][1])
def test_search_unittest(self):
self.baidu_search(self.test_data[1][1])
def test_search_parameterized(self):
self.baidu_search(self.test_data[2][1])
if __name__ == '__main__':
unittest.main(verbosity=2)After optimization, use the setUpClass() method to read the baidu_data.csv file and store the data in the file to
test_data array. Create different test methods using the data in test_data. The test results are as follows:
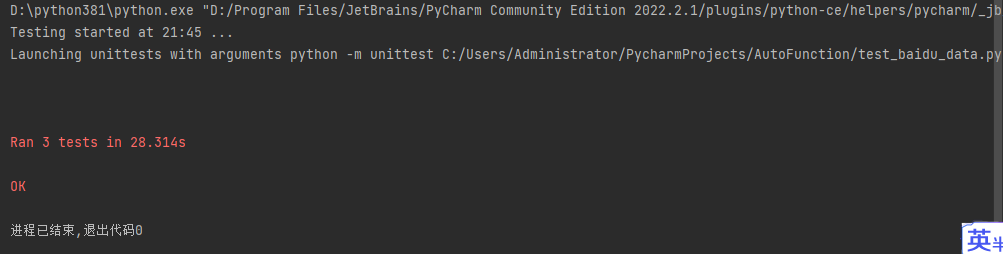
From the test results, we can see that 3 pieces of data were executed as 3 test cases. So is it a perfect solution?
What about the previous question? Next, you need to think about what problems are caused by reading data files?
(1) Increased reading cost. No matter what kind of data file, you need to convert it before running the automated test case.
This step is indispensable when the data in the file is read into the program.
(2) Inconvenient to maintain. Reading data files is to facilitate maintenance, but in fact it is just the opposite. In CSV data file
In the software, the test cases corresponding to each piece of data cannot be intuitively reflected. And in the test case pass test_data[0][1]
There are also many problems in obtaining data. If a piece of data is inserted in the middle of the CSV file, then the test case obtains
The test data received is likely to be wrong.
What if a lot of data is needed during testing? We know that the test script is not used to store data
If there is a lot of data to be tested, it is obviously not appropriate to put it all in the test script.
Before answering this question, first think about what is UI automation testing? UI automation testing is based on the user
The angle simulates the user's operation. So in what scenarios do users enter a large amount of data? In fact, inputting a lot of data
There are very few functions. If the entire system requires users to enter data repeatedly or in large quantities, then it is likely that the user experience is poor.
Not good! Most of the time, the system only allows users to enter their username, password and personal information, or search for some keywords
wait.
Suppose we want to test the function of users posting articles, which will indeed use a lot of data.
So is reading the data file completely unnecessary? Of course not, such as the configuration of some automated tests
It can be placed in data files, such as the operating environment, running browsers, etc., and it will be more convenient to manage if placed in the configuration file.
DDT(Data-Driven Tests)
DDT is an extension library designed for the unittest unit testing framework. Allows running a test case with different test data and displaying it as multiple test cases.
GitHub 地址:https://github.com/datadriventests/ddt。
DDT supports pip installation.
pip install ddtTake Baidu search as an example to see how DDT is used. Create test_baidu_ddt.py file
# _*_ coding:utf-8 _*_
"""
name:zhangxingzai
date:2023/3/19
"""
import unittest
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from ddt import ddt, data, file_data, unpack
@ddt
class TestBaidu(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Firefox()
cls.base_url = "https://www.baidu.com"
def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element(By.ID, "kw").send_keys(search_key)
self.driver.find_element(By.ID, "su").click()
sleep(3)
# 参数化使用方式一
@data(["case1", "selenium"], ["case2", "ddt"], ["case3", "python"])
@unpack
def test_search1(self, case, search_key):
print("第一组测试用例:", case)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")
# 参数化使用方式二
@data(("case1", "selenium"), ("case2", "ddt"), ("case3", "python"))
@unpack
def test_search2(self, case, search_key):
print("第二组测试用例:", case)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")
# 参数化使用方式三
@data({"search_key": "selenium"}, {"search_key": "ddt"}, {"search_key": "python"})
@unpack
def test_search3(self, search_key):
print("第三组测试用例:", search_key)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")
@classmethod
def tearDownClass(cls):
cls.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2)When using DDT, you need to pay attention to the following points:
First, the test class needs to be decorated with the @ddt decorator.
Second, DDT provides different forms of parameterization. Three groups of parameterizations are listed here. The first group is a list, and the second group is a list.
The first group is a tuple, and the third group is a dictionary. It should be noted that the key of the dictionary must be consistent with the parameters of the test method.
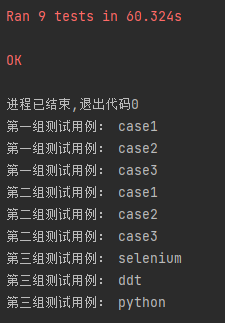
The execution results are as follows:
DDT also supports parameterization of data files. It encapsulates the reading of data files, allowing us to focus more on data files.
The content in the file and its use in test cases, without caring about how the data file is read.
First, create the ddt_data_file.json file:
{
"case1": {"search_key": "python"},
"case2": {"search_key": "ddt"},
"case3": {"search_key": "Selenium"}
}Use the test_data_file.json file to parameterize the test case in the test case, in the test_baidu_ddt.py file
Add test case data. code show as below:
# _*_ coding:utf-8 _*_
"""
name:zhangxingzai
date:2023/3/19
"""
import unittest
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from ddt import ddt, data, file_data, unpack
@ddt
class TestBaidu(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Firefox()
cls.base_url = "https://www.baidu.com"
def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element(By.ID, "kw").send_keys(search_key)
self.driver.find_element(By.ID, "su").click()
sleep(3)
# 参数化使用方式一
@data(["case1", "selenium"], ["case2", "ddt"], ["case3", "python"])
@unpack
def test_search1(self, case, search_key):
print("第一组测试用例:", case)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")
# 参数化使用方式二
@data(("case1", "selenium"), ("case2", "ddt"), ("case3", "python"))
@unpack
def test_search2(self, case, search_key):
print("第二组测试用例:", case)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")
# 参数化使用方式三
@data({"search_key": "selenium"}, {"search_key": "ddt"}, {"search_key": "python"})
@unpack
def test_search3(self, search_key):
print("第三组测试用例:", search_key)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")
# 参数化读取 JSON 文件
@file_data('ddt_data_file.json')
def test_search4(self, search_key):
print("第四组测试用例:", search_key)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")
@classmethod
def tearDownClass(cls):
cls.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2)Note that the ddt_data_file.json file needs to be placed in the same directory as test_baidu_ddt.py, otherwise it needs to be pointed out
Determine the path of the ddt_data_file.json file.
In addition, DDT also supports data files in yaml format. Create the ddt_data_file.yaml file:
case1:
- search_key: "python"
case2:
- search_key: "ddt"
case3:
- search_key: "unittest"Add test cases in the test_baidu_ddt.py file:
以上省略。。。
# 参数化读取 yaml 文件
@file_data('ddt_data_file.yaml')
def test_search5(self, case):
search_key = case[0]["search_key"]
print("第五组测试用例:", search_key)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")The value here is different from the JSON file above because each use case is parsed as [{'search_key':
'python'}], so if you want to get the search keyword, you need to get it through case[0]["search_key"].
Note: It is possible that reading the yaml folder fails and an error is reported during program execution. You can install the PyYAML library to fix it.
pip install PyYAML