Basics of Parallel Programming Basics of Parallel Programming

The core has reached the upper limit and cannot be made faster and faster. The problem can only be solved by using more cores

Process process
has independent storage Units, managed by the system, need to exchange information through special mechanisms
Thread threads
share memory within the process. Threads share a lot of memory, and these memories are channels for data exchange. 
Methods of managing Tasking
Preemptive Multitasking:
When this thread/task is running, the scheduler Determine interruption and return. The task itself cannot decide
Non-preemptive Multitasking Non-preemptive multitasking:
In turn, let the task itself decide when to end. The advantage is that if the tasks are all given by yourself, the control ability is stronger. But it's easy to get stuck. Relatively rarely used, mostly used in some operating systems with very high real-time performance

Thread switching is very expensive:
If a thread is interrupted, it is very expensive, at least It requires more than 2,000 CPU cycles
and the data of the newly transferred threads is not in the cache at all levels, so it has to be re-called from the memory, which may take more than 10,000 ~ 1,000,000 CPU cycles
Job System is used to solve these problems
Two problems of parallel programming:
1. Embarrassing Parallel Problem
Let the threads run independently without interrupting the threads. There is no problem of swapping threads. It's just a bunch of independent questions, each of them has to be solved and then closed. For example, Monte Carlo integral algorithm
2.Non-Embarrassing Parallel Problem
However, in real game cases, the simulation required for a game cannot be divided so clearly. There are many data dependencies between various systems

Data Race data preemption. When reading and writing occur in the same data but in different threads, it will cause data inconsistency after reading and during operation
Locking Primitives lock algorithm
Critical Section : This code can only be executed by the current thread, and the relevant data only belongs to the current thread and cannot be modified by other threads.
is blocking programming 
Blocking programming
may cause deadlock. If the thread is not unlocked, it will be stuck, and subsequent related threads will also be stuck.
In a large system with hundreds of tasks, there is no guarantee that each task will succeed. The failure of one task may cause Deadlock of the entire system
When a high-priority task comes in, it cannot interrupt the running low-priority task, and the task priority loses its meaning
Therefore Use lock as little as possible
Atomic operations:
Implemented at the bottom of the hardware to ensure that read and write operations on variables will not be preempted by multiple tasks
Load: Load from memory to a Thread-safe storage space, and then check the value
Store: Write data into memory
The core idea of is to avoid locking the entire code. Ensure that the memory operation of this value in the executed instruction is atomic
The hole means that the CPU is waiting
lock free programming: avoid deadlock What often happens is that the operation on the PC simulator and the actual machine are completely inconsistent Each CPU and each Different architectures will lead to different sequences This is where parallel development is very prone to problems This When thread 2 sees that b is equal to 0, it is not true that a is equal to 2 It is possible that b is assigned to a temporary variable in thread 1, then b is assigned the value 0, a has not been assigned the value 2, and then a is assigned the value 2 using the temporary variable But after the actual compiler optimization, a and b are two unrelated variables, In thread 2, when monitoring b equals 0, a should be equal to 2 In thread 1, a is equal to 2 first, and b is equal to 0 The expected logic is: High-level language cannot know the specific assembly language sequence after the compiler compiles it. It only guarantees that the result is consistent, but it will A big problem occurs in multi-threading Strict mathematical deduction is required to prove It is almost impossible to achieve 100% cpu utilization. But for specific operations, such as stack or queue operations, wait free can be achieved. For example, high-frequency communication protocols.
wait free: Theoretically, a set of mathematical methods are used to avoid cpu waiting as much as possible


In C++11 it is possible to explicitly require execution order, but the performance is lower
Reasons for out-of-order: There is a large amount of data storage and reading, because the CPU is usually hungry for data, and does not wait for instructions to be executed one by one, and reads data according to the instructions. Instead, the entire instruction and data are mixed together in the CPU. running in
This is also the reason why debug is normal but release fails. Because debug is often sequential, but release is out of order.
Parallel Framework of Game Engine Parallel Framework of Game Engine


Fixed Multi-Thread Fixed multi-thread
The approach of most traditional engines is to classify threads into fixed threads based on tasks, do not infringe on each other, and exchange at the beginning of each Frame data.
is better in the case of 2-4 cores.
But it is difficult to ensure that the workload of the four threads is the same. Some are light and some are heavy. It is a barrel effect. All threads have to wait for the slowest thread to complete the task.
And it is difficult to offload heavily loaded tasks to other idle threads. Because usually the data accessed by a thread is in one place as much as possible. To ensure that the data is safe. Another reason is that the load of different threads in different scenes is different. In landscape scenes, the rendering pressure is high, and in combat scenes, the simulation thread pressure is high. About 1/3 of the resources will be wasted > If the number of fixed threads is higher than the number of cores configured on the computer, thread preemption problems will still occur. An 8-core or 16-core computer will be wasteful Thread Fork-Join The consistency in the extracted game is very high, but the amount of calculation is very large, such as animation, For some operations of physical simulation, at a certain time, these fixed threads will Fork some subtasks and pass them to the Work Thread (applied in advance), and then the results of the Task will be recycled after calculation Work threads can be generated dynamically Many games based on unity and unreal use this method but it will still cause the CPU to become idle Two types of Thread are provided in Unreal: Named Thread: explicitly told to Game, Logic, Render, etc. Worker Thread: used to handle physics, animation , particles, etc. A more complex architecture You can create many tasks, set the dependencies of the tasks, and throw them all to the core for processing, and the core will automatically follow the tasks The dependency between them determines the execution sequence and parallel tasks The game has a strong dependencyTask Graph specific implementation: Add Link directly to the code, and automatically generate Graph after the dependency is built Problem: The construction of the task tree is opaque The dependency of tasks in real game engines is dynamic, not static (the dynamic generation of nodes in the task graph is very complicated, and there was no wait function in the early days)





Job System

Coroutine
is a very lightweight way of multi-thread execution
Actually it is: any stage of function execution through Yield Jump out of suspension and give up execution rights. Then you can activate Invoke to continue execution from the jumped node
The core is that in the middle of task execution, the channel can be allowed to go out and come back
There are many modern high-level languages Native support, such as c#, go. But it is difficult to implement coroutines in C++
A thread is an interrupt that adjusts the hardware, that is, the entire environment context and stack will be reset, so the cost of creation and interruption is very high, and it is a direct notification To the OS
of the operating system, the coroutine is defined by the program itself. In one thread, you can switch back and forth among many coroutines. From the CPU point of view, it is still in one thread, through the program. Define switching and activation, and do not activate core switching
Stack coroutine
The key is that after exiting and reactivating, the local variables will not be contaminated or Cleared

stackless coroutine
is equivalent to clearing local variables directly. Implementation in c++ is equivalent to Go To in assembly. The requirements for the implementer are very high. Once it is not written well, a lot of bugs will occur
. The biggest advantage is that there is no need to save and restore the state of the entire stack, and the switching cost is very low. Generally, Stackful may be used at the very lowest level. It is a coroutine more suitable for more developers. Stackless is used at the lower level and is only used by a few people. , people who need more knowledge and experience
A big difficulty with coroutines is that different operating systems, including native languages c, c++, assembly language and other underlying languages, do not support the coroutine mechanism. Different platforms require different mechanisms
Fiber-based task system
High-speed thread pipeline, which can load various jobs at high speed and freely switch coroutines. At the same time, Job can also set dependency and priority. 
How many Work Threads should be applied for?
As much as possible, one work thread corresponds to one core, which can be a logical core or a physical core, usually a logical core< /span> The specific underlying engineering is very complex Different OS implementations The methods are different C++ cannot be supported natively, you can refer to the Boost source code Disadvantages: There is no Thread Switch Each stack is independent of each other Easy to design dependencies Easy to implement schedule Advantages: Scheduler will allocate unexecuted tasks of heavy Work Thread to idle Work Thread through Job Stealing This leads to uneven distribution of Work Thread For example, waiting for IO, complex operations, generating a lot of dependencies, etc. Because it is not possible to estimate the time required for each job Scheduler will throw the Yield Job into a waiting list. Then execute the next task In the engineering implementation of game engines, when implementing Job System, there is usually LIFO. Because many jobs in the game are generated only halfway through the execution of the previous job, multiple different jobs may be generated. There is a dependency relationship between them. That is to say, if the new job generated by the current job is not completed, it cannot be executed. Hence the first-in-last-out model. Similar to a stack Execution model: first in, first out, first in last out The difference from Fork-join is here, it is a Full parallelization method Allocate jobs to working threads according to the priority of the job, dependencies and the saturation status of the Work Thread Jobs have priorities and dependencies Question The generated Jobs are directly loaded into Thread and then processed
Let the swap of thread be almost 0 





Programming Paradigms Programming Paradigms

In the early days, POP was the main one.
In modern times, it is basically OOP.
OOP question 1:
There are many ambiguities. sex. That is a design issue,
As shown in the example above, should it be written that the player is attacking the enemy or that the enemy is being attacked? That is, which class does an action (function) belong to?
And different people have different ways of writing this
Question 2: OOP is a very deep inheritance tree .
As shown in the picture above, as for the function of receiving magic damage, is it written on the Go layer, the Monster layer, or the specific spider monster layer?
And everyone has different views on this issue. 
Problem 3: The base class will be very large and bloated, and the derived class may only need a few functions of the base class.

Problem 4: The performance of OOP is very low.
Memory is dispersed, and data will be dispersed into various objects.
Virtual functions jump in various ways on the memory, and there will be many pointers in the overloading of functions. Causes the code to jump around during execution
Question 5: OOP testability.
OOP testing needs to create all environments and all objects. to test whether one of the functions is correct. Because all data is contained in the object. Objects are nested one layer inside another, making it difficult to write unit tests
Data-Oriented Programming Data-Oriented Programming

CPUs are getting faster and faster, but memory access speeds cannot keep up, resulting in modern computers having very complex caching mechanisms
Cache cache
L1 Cache is the cache closest to the CPU and is the fastest
L2 Cache is slightly further away and is slightly slower than L1
L3 Cache is a direct link In memory, the speed is also the slowest in the Cache
The CPU starts querying data layer by layer from L1
If you want to be cache-friendly, you must respect the data compactness. That is, the data should be kept together as much as possible
SIMD: The addition, subtraction, multiplication and division of 4 floats are regarded as a vector. It is done at one time, reading 4 spaces at one time and writing 4 spaces at one time. Most hardware supports 
LRU: after the Cache is filled → retain the recently used items → remove the recently unused items,
There is another Random eviction algorithm, based on probability
, each read and write takes a cache line.
Suppose there is data, and this data is between caches at all levels. Each cache and memory has a section, and the CPU must ensure that the data in the three caches and memories are consistent. Therefore, it is read layer by layer and written to the memory layer by layer. This is why the efficiency of reading data row by row is many times faster than the efficiency of reading data column by column. Reading down will cause Cache Line to jump and cause Cache Miss
This is why the efficiency of reading data row by row is many times faster than the efficiency of reading data column by column. Reading down will cause Cache Line to jump and cause Cache Miss
The core idea of DOP: All expressions in the game world are data

The code itself is also data a> So the best practice is that workers and corresponding workers can handle them Materials enter the factory together, which is what DOP wants to achieve If the materials produced in the factory cannot be processed by the workers in the factory, it is necessary Workers who can handle the materials come in; or the workers in the factory cannot handle the materials currently in the factory, so they need to wait for new materials to come in Think of Cache as a factory In terms of code, the code is the worker, and the data is the material of the product. Each worker can only process specific materials Example: Equivalent to the data processor and the data to be processed are together In DOP, data and code will be regarded as a whole, and the data and code will be kept as close as possible in the cache. together (may be separate in memory). Make sure that after the code is executed, the data can just be processed.
The main consideration is to minimize the problem of Cache Miss
Performance-Sensitive Programming Performance-Sensitive Programming

Reduce the dependency on the execution order, so that there is as little dependency between the execution of codes as possible

There are two functions, one is reading and the other is writing the same variable. Variables read and written by two threads at the same time in the same cache line will increase the system load
Therefore, try to avoid two threads reading and writing a cache line at the same time. That is, do not let two threads access very fragmented data at the same time. Try to let each thread access its own piece of data
In modern CPUs, Branch statements such as If or Switch will be optimized. Directly load the code for predicted execution into the cache. If it is found that the conditions are not met, you need to swap out the pre-loaded code, which may need to be read from cold data (memory or hard disk), which will take a long time
In the above example, the if , else jumps between, resulting in repeated cache switching, resulting in very low performance degradation 1
The optimization method is to perform a sorting before execution. In this way, you only need to perform a cache switch
. Group the data in advance to avoid complex If and Else. Use different containers to group data, so that a group of containers corresponds to one processing code, thereby reducing the number of processing codes in the cache. swap in
Performance-Sensitive Data Arrangements Performance-Sensitive Data Programming


When using OOP ideas to define something, Structure is generally used to define its attributes, and each thing is defined using this entire structure. The definition of particles is shown in the figure on the left. This is the AOS architecture
If defined in this way, suppose I want to modify the position and speed of all particles, but we need to jump other attributes in the memory such as color and life cycle, which is not conducive to high performance. Performance programming
But if you use SOA, you can directly pass an entire array into the Cache, and the processing will be much more efficient. This idea is very similar to writing a Shader, because the GPU is inherently data-driven a>
Entity Component System ECS Architecture


The most natural way to implement a Component-Based system is to use OOP.
But it will cause many problems:
Too many virtual functions Pointer problem
A large amount of code is scattered in various classes
The data is also very scattered
The efficiency of such code implementation is very high Low
Entity: Very lightweight, it is an id, and the id points to a group of components. That is, what data is used
Component: a piece of data. No business logic, no excuses. Pure data (note that the Component base mentioned earlier has many interfaces, such as tick, setProperty, getProperty). It can perform read and write operations, but it does not know its meaning
System: used to process components. Where the business logic resides. Several types of data may be processed at the same time. For example, there is a moving system, the position is based on the speed. The health system will adjust the health value according to the damage.
ECS is essentially a theoretical framework that aims to make full use of the features of Cache, multi-threading and DOP to achieve high efficiency

It is a concept similar to a template or prototype< a i=2> For example, an NPC requires several specific components, Archetype is similar to type of GO
The purpose of is that when ECS checks thousands of Entities, it cannot check whether the Entity has a specific Component one by one. This access will be very slow. But Archetype saves a lot of steps. 
Chunk
Define the memory into Chunks, and then put all the Components of a type of Archetype into them one by one according to their types. A Chunk must be of the same type of Archetype
The advantage is that when you need to process this Chunk, you can directly extract the entire data and ignore other data without loss










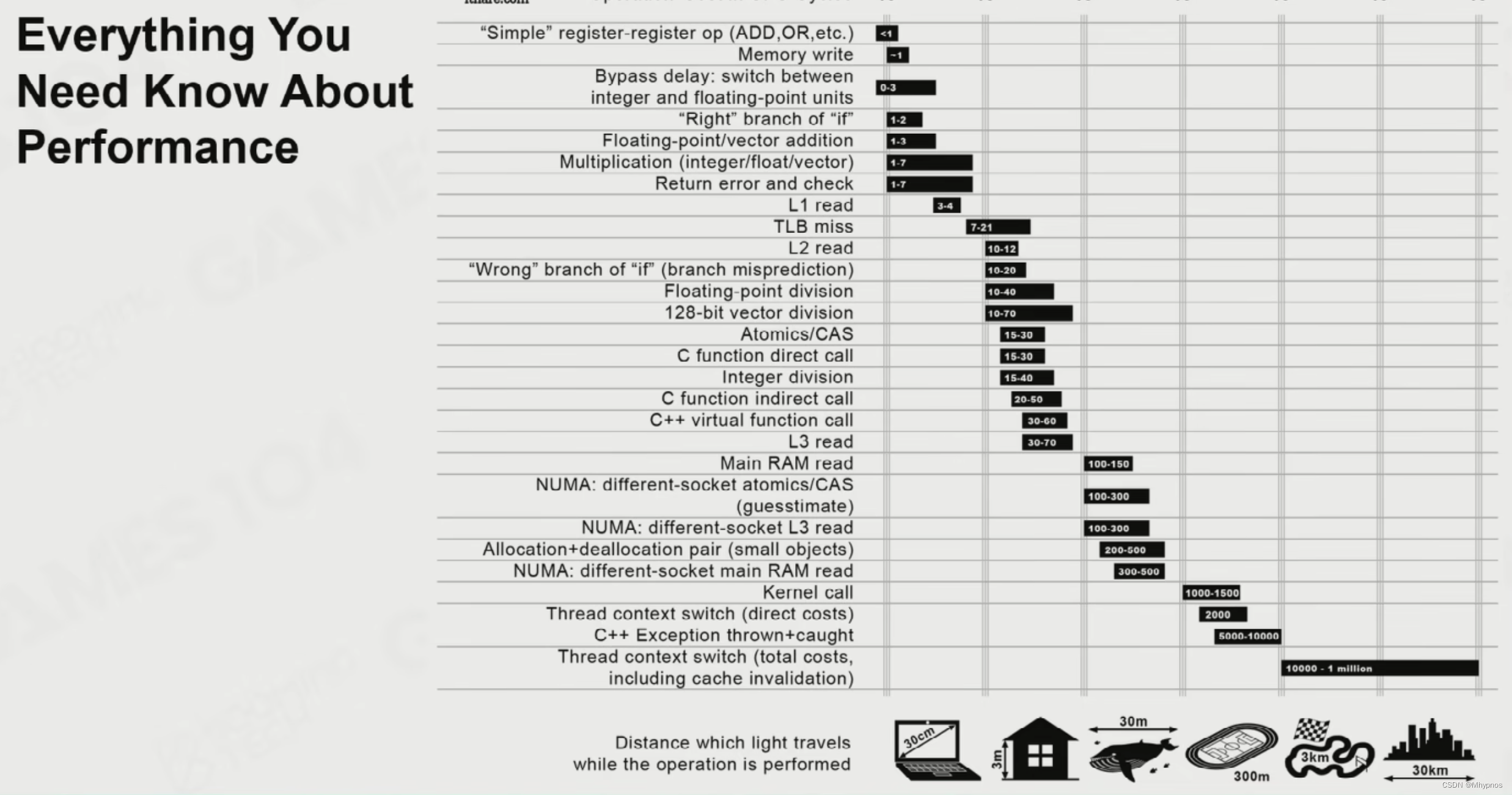
Time consuming for most CPU operations