Hello everyone, I am Wei Xue AI. Today I will introduce to you the application of computer vision 21-implementation of image classification task based on the attention mechanism CoAtNet model, loading data for model training. In this article, we will introduce the principles of the CoAtNet model in detail, and use an example based on the PyTorch framework to show how to load data, train the CoAtNet model containing the attention mechanism, and understand the model operationally.
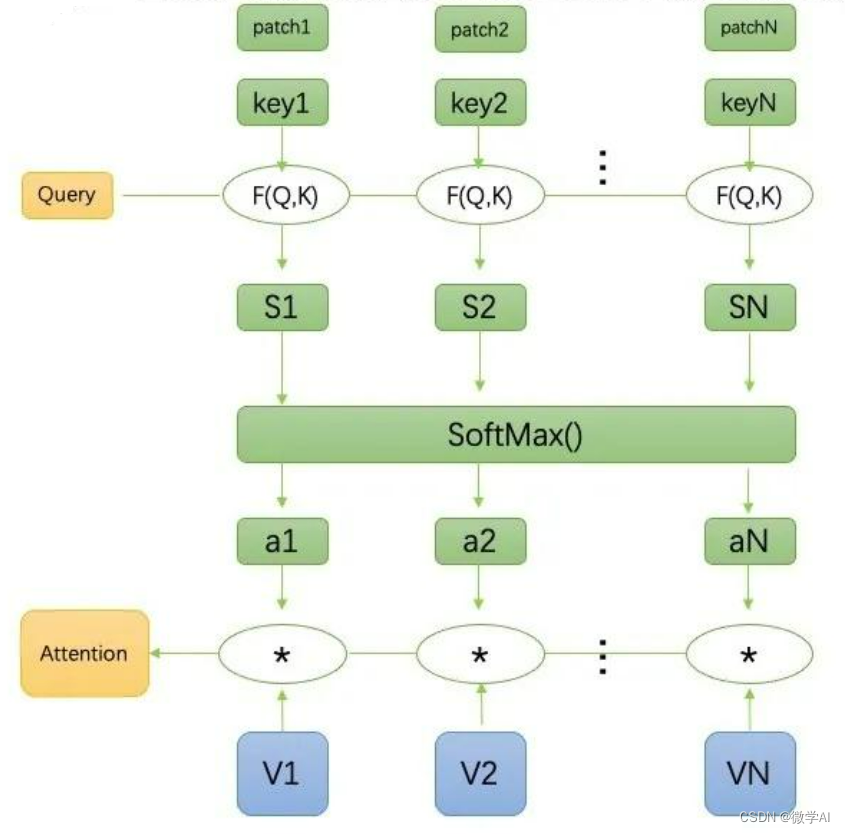
Table of contents
- CoAtNet model introduction
- CoAtNet model principle
- CSV data sample
- Data loading and preprocessing
- Implementing the CoAtNet model using the PyTorch framework
- Model training
- Summarize
1. Introduction to CoAtNet model
CoAtNet (Collaborative Attention Network) is a network model based on a combination of convolutional neural network (CNN) and self-attention mechanism (Self-Attention). CoAtNet combines the advantages of these two technologies and aims to improve the feature expression ability of the model to achieve better performance in computer vision tasks.
2. CoAtNet model principle
The core principle of CoAtNet is to combine a convolutional neural network and a self-attention mechanism. The following are the main components of the CoAtNet model:
1.Convolutional Layer: The convolutional layer is used to extract local features in the image and can capture the spatial information.
2.Self-Attention Mechanism: The self-attention mechanism is used to calculate the relationship between input features , which can capture long-distance dependencies.
3.Collaborative Attention Module (CAM): CAM is the core module of CoAtNet, which combines convolutional layers and The combination of the self-attention mechanism allows the model to capture long-distance dependencies while extracting local features.
4.Residual Connection: In order to avoid the problems of gradient disappearance and gradient explosion, CoAtNet uses residual connection, so that Models can learn features more deeply.
CoAtNet is a convolutional neural network model based on the attention mechanism. It combines convolutional operations and self-attention mechanisms to achieve efficient and accurate feature extraction in image classification tasks.
Let us represent the CoAtNet model in mathematical notation.
Suppose the input image is x ∈ R H × W × C x \in \mathbb{R}^{H \times W \times C} x∈RH×W×C , inside H H H、 W W Wsum C C C represents the height, width and number of channels of the input image respectively. First, the input image is extracted through a convolutional layer to obtain the feature map V ∈ R H ′ × W ′ × D V \in \mathbb{R}^{H' \times W' \times D} IN∈RH′×W′×D, inside H ′ H� 39;H′、 W ′ W' IN′sum D D D represents the height, width and number of channels of the feature map respectively.
Next, use the self-attention mechanism to process the feature map. Assume that the input of the attention mechanism is Q ∈ R H ′ × W ′ × D Q \in \mathbb{R}^{H' \times W' \times D} a>Q∈RH′×W′×D、 K ∈ R H ′ × W ′ × D K \in \mathbb{R}^{H' \times W' \times D} K∈RH′×W′×D和 V ∈ R H ′ × W ′ × D V \in \mathbb{R}^{H' \times W' \times D} IN∈RH′×W′×D, inside Q Q Q、 K K Ksum V V V represents query, key and value respectively. The output of the attention mechanism is:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)IN
inside d k d_k dk represents the query and key dimensions. In CoAtNet, we can use the convolution operation to convert V V V转换为Q Q Q、 K K Ksum V V V。
Process the output of the attention mechanism, including operations such as residual connection, layer normalization, and feed-forward neural network. These operations help improve the representation ability and stability of the model.
3. CSV data sample
To facilitate demonstration, we provide the following CSV data samples:
filename,label
image_001.jpg,0
image_002.jpg,1
image_003.jpg,0
image_004.jpg,1
image_005.jpg,0
4. Data loading and preprocessing
First, we need to load the data in the CSV file and preprocess the image. We will use the pandas library to read the CSV file and the PIL library and torchvision.transforms to preprocess the image.
import pandas as pd
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor, Normalize
# 读取CSV文件
data = pd.read_csv("books.csv")
# 定义图像预处理操作
transform = Compose([
Resize((224, 224)),
ToTensor(),
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 加载图像数据
images = []
labels = []
for index, row in data.iterrows():
filename, label = row["filename"], row["label"]
image = Image.open(filename)
image = transform(image)
images.append(image)
labels.append(label)
images = torch.stack(images)
labels = torch.tensor(labels, dtype=torch.long)
5. Implement the CoAtNet model using the PyTorch framework
Next, we will implement the CoAtNet model using the PyTorch framework. First, we need to define the basic components of the model, including convolutional layers, self-attention mechanism, and collaborative attention module. We then combine these components to build the CoAtNet model.
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class SelfAttention(nn.Module):
def __init__(self, in_channels, out_channels):
super(SelfAttention, self).__init__()
self.query = nn.Conv2d(in_channels, out_channels, 1)
self.key = nn.Conv2d(in_channels, out_channels, 1)
self.value = nn.Conv2d(in_channels, out_channels, 1)
def forward(self, x):
q = self.query(x)
k = self.key(x)
v = self.value(x)
q = q.view(q.size(0), q.size(1), -1)
k = k.view(k.size(0), k.size(1), -1)
v = v.view(v.size(0), v.size(1), -1)
attention = F.softmax(torch.bmm(q.transpose(1, 2), k), dim=-1)
y = torch.bmm(v, attention)
y = y.view(x.size(0), x.size(1), x.size(2), x.size(3))
return y
class CollaborativeAttentionModule(nn.Module):
def __init__(self, in_channels, out_channels):
super(CollaborativeAttentionModule, self).__init__()
self.conv_block = ConvBlock(in_channels, out_channels, 3, 1, 1)
self.self_attention = SelfAttention(out_channels, out_channels)
def forward(self, x):
x = self.conv_block(x)
x = x + self.self_attention(x)
return x
class CoAtNet(nn.Module):
def __init__(self, num_classes):
super(CoAtNet, self).__init__()
self.stem = ConvBlock(3, 64, 7, 2, 3)
self.pool = nn.MaxPool2d(3, 2, 1)
self.cam1 = CollaborativeAttentionModule(64, 128)
self.cam2 = CollaborativeAttentionModule(128, 256)
self.cam3 = CollaborativeAttentionModule(256, 512)
self.cam4 = CollaborativeAttentionModule(512, 1024)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.stem(x)
x = self.pool(x)
x = self.cam1(x)
x = self.cam2(x)
x = self.cam3(x)
x = self.cam4(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
6. Model training
After defining the CoAtNet model, we need to train the model. First, we will define the loss function and optimizer, and then train the model using the training data.
from torch.optim import Adam
from torch.utils.data import DataLoader, TensorDataset
# 划分训练集和验证集
train_size = int(0.8 * len(images))
val_size = len(images) - train_size
train_images, val_images = torch.split(images, [train_size, val_size])
train_labels, val_labels = torch.split(labels, [train_size, val_size])
# 创建DataLoader
train_dataset = TensorDataset(train_images, train_labels)
val_dataset = TensorDataset(val_images, val_labels)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
# 初始化模型、损失函数和优化器
model = CoAtNet(num_classes=2)
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-4)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
model.train()
train_loss = 0.0
train_correct = 0
for images, labels in train_loader:
# 将数据移到GPU上(如果可用)
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 计算训练集的损失和准确率
train_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
train_correct += (predicted == labels).sum().item()
# 计算平均训练损失和准确率
train_loss = train_loss / len(train_dataset)
train_acc = train_correct / len(train_dataset)
# 打印每个epoch的损失和准确率
print('Epoch [{}/{}], Train Loss: {:.4f}, Train Accuracy: {:.2f}%'.format(epoch+1, num_epochs, train_loss, train_acc*100))
7. Summary
The CoAtNet model combines convolution operations and self-attention mechanisms to achieve efficient and accurate feature extraction. The main steps of the model include:
1. The input image is extracted through a convolutional layer to obtain a feature map.
2. The feature map is processed by the self-attention mechanism to generate an attention-weighted feature representation.
3. Process the attention-weighted feature representation, including operations such as residual connections, layer normalization, and feed-forward neural networks.
4. Finally, the processed feature representation is obtained, which can be used for tasks such as image classification.
The CoAtNet model combines convolution and attention mechanisms, uses convolution operations to extract local features, and uses self-attention mechanisms to capture global relationships, thereby obtaining richer feature representations. This combination makes CoAtNet efficient and accurate in tasks such as image classification.