[Image Segmentation] [Deep Learning] PFNet official Pytorch code-PFNet network FM focus module analysis
Article directory
Preface
Before analyzing the PFNet code in detail, the first task is to successfully run the PFNet code [Reference tutorial under win10], so that subsequent learning is meaningful. This blog explains the FM focus module code of the PFNet neural network module and does not involve other functional module codes.
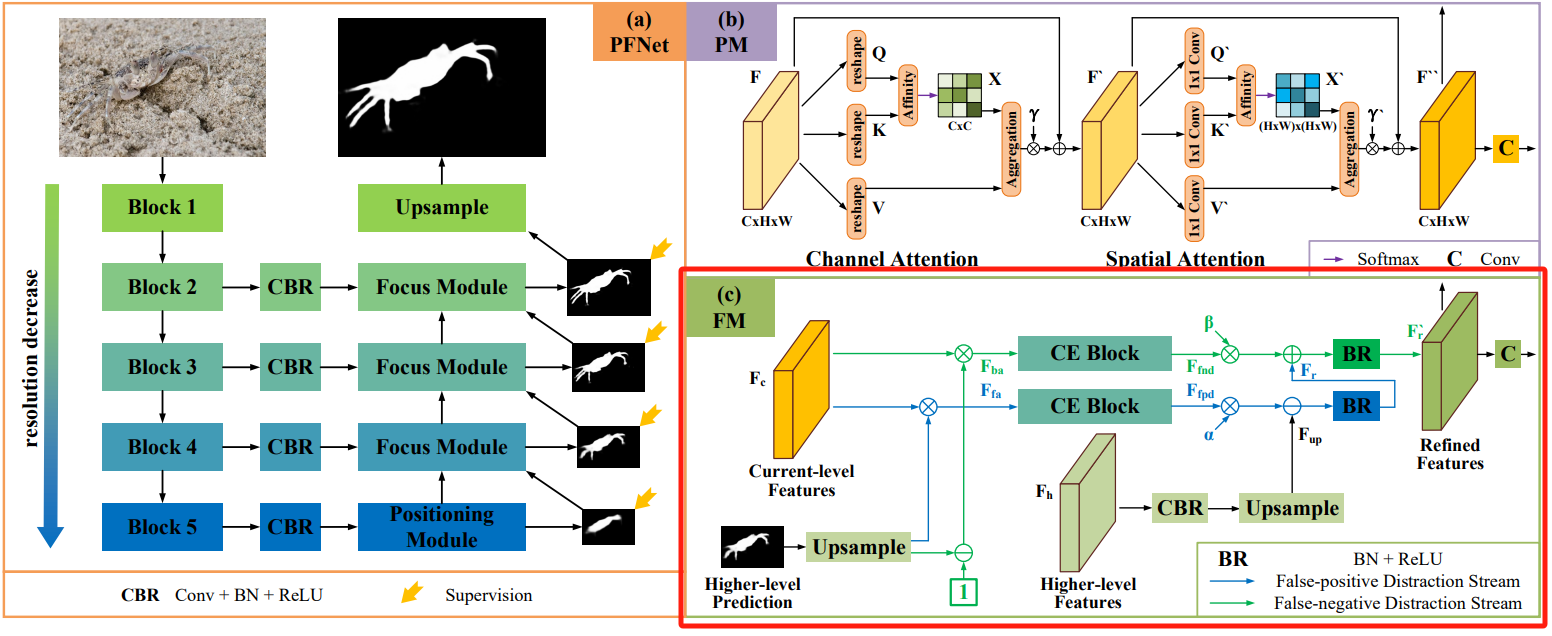
The blogger has analyzed the codes of each functional module in detail in different blog posts. Click [Reference Tutorial under Win10], and the directory link of the blog post is placed in the preface.
Focus Module Focus Module
The structure of the Focus Module (FM) in the original paper is shown below:
Since the camouflage object usually has a similar appearance to the background, there will be false alarms in the initial prediction. Positive (FP) and False Negative (FN) predictions, the design uses the FM focusing module to find and remove these false predictions.
- Upsample the Higher-level Prediction and use the sigmoid layer to normalize it to generate it F h p F_{ {\rm{hp}}} Fhp,并将 F h p F_{ {\rm{hp}}} Fhpgiven ( 1 − F h p ) (1 -{F_{ {\rm{hp}}}}) (1−Fhp) and current-level features (Current-level Features) F c F_c FcMultiply to generate foreground attention features respectively F f a F_{ {\rm{fa}}} FfaJapanese background caution special expedition F b a F_{ {\rm{ba}}} Fba;
- General types of special expedition F f a F_{ {\rm{fa}}} Ffasum F b a F_{ {\rm{ba}}} Fba is input into two parallel context exploration blocks (CE Block) to perform contextual reasoning and find false positive interference respectively F f p d F_{ {\rm{fpd}}} Ffpdand false negative interference F f n d F_{ {\rm{fnd}}} Ffnd;
- For Higher-level Features F h F_h Fh进行CBR并上采样 F u p = U p ( C B R ( F h ) ) {F_{up}} = {\rm{ }}Up\left( {CBR\left( { {F_h}} \right)} \right) Fup=Up(CBR(Fh)),分别进行 F r = B R ( F u p − α F f p d ) {F_r}{\rm{ }} = {\rm{ }}BR\left( { {F_{up}}{\rm{ }} - {\rm{ }}\alpha {F_{fpd}}} \right) Fr=BR(Fup−αFfpd)Feature-pixel pixel subtraction operation to suppress blurred background (i.e. false positive interference) and F r ′ = B R ( F r + β F f n d ) F_r^\prime {\rm{ }} = {\rm{ }}BR\left( { {F_r}{\rm{ }} + {\rm{ }}\beta {F_{fnd}}} \right) Fr′=BR(Fr+βFfnd) Feature pixel-by-feature addition operation to add missing foreground (i.e. false negative interference);
- Finally pass the pair F r ′ F_r^\prime {\rm{ }} Fr′Perform convolution to obtain a more accurate prediction map.
CBR is the abbreviation of convolution layer, BN layer and ReLU activation layer; BR is the abbreviation of BN layer and ReLU activation layer; α \alpha αsum β \beta β is a trainable parameter.
Code location: PFNet.py
class Focus(nn.Module):
def __init__(self, channel1, channel2):
super(Focus, self).__init__()
self.channel1 = channel1
self.channel2 = channel2
# 对higher-level features上采样保持与current-level features通道一致
self.up = nn.Sequential(nn.Conv2d(self.channel2, self.channel1, 7, 1, 3),
nn.BatchNorm2d(self.channel1), nn.ReLU(), nn.UpsamplingBilinear2d(scale_factor=2))
# 对higher-level prediction上采样,nn.Sigmoid()将所以小于0的值都当作背景
self.input_map = nn.Sequential(nn.UpsamplingBilinear2d(scale_factor=2), nn.Sigmoid())
self.output_map = nn.Conv2d(self.channel1, 1, 7, 1, 3)
# CE block
self.fp = Context_Exploration_Block(self.channel1)
self.fn = Context_Exploration_Block(self.channel1)
# 可训练参数
self.alpha = nn.Parameter(torch.ones(1))
self.beta = nn.Parameter(torch.ones(1))
self.bn1 = nn.BatchNorm2d(self.channel1)
self.relu1 = nn.ReLU()
self.bn2 = nn.BatchNorm2d(self.channel1)
self.relu2 = nn.ReLU()
def forward(self, x, y, in_map):
# x; current-level features
# y: higher-level features
# in_map: higher-level prediction
# 对higher-level features上采样
up = self.up(y)
# 对higher-level prediction上采样
input_map = self.input_map(in_map)
# 获得current-level features上的前景
f_feature = x * input_map
# 获得current-level features上的背景
b_feature = x * (1 - input_map)
# 前景
fp = self.fp(f_feature)
# 背景
fn = self.fn(b_feature)
# 消除假阳性干扰
refine1 = up - (self.alpha * fp)
refine1 = self.bn1(refine1)
refine1 = self.relu1(refine1)
# 消除假阴性干扰
refine2 = refine1 + (self.beta * fn)
refine2 = self.bn2(refine2)
refine2 = self.relu2(refine2)
# 卷积精化
output_map = self.output_map(refine2)
return refine2, output_map
Contextual Exploration Block CE Block
The structure of the Context Exploration (CE) block in the original paper is shown in the figure below:
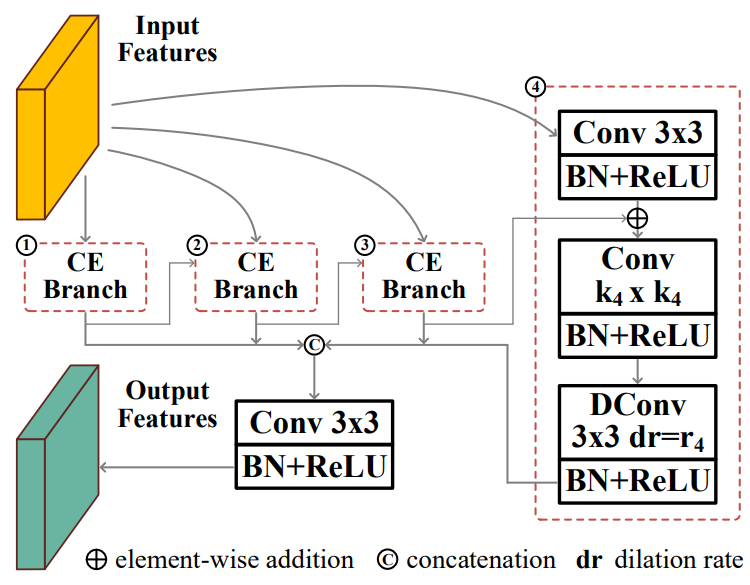
The CE block consists of four context exploration branches, each branch includes channels for Reduced (dimensionality reduction) 1×1 convolution, used for local feature extraction k i k_i ki× k i k_i kiConvolution, and dilation rate for context awareness r i r_i ri3×3 dilated convolution (or dilated convolution). Through such a design, CE Block gains the ability to perceive rich context in a wide range, so it can be used for contextual reasoning and separately discover false positive interference and false negative interference.
The original paper description uses 3×3 convolution for dimensionality reduction, but the code uses 1×1 convolution. The blogger shall refer to the code; k i k_i < /span>kiThe convolution kernel sizes in the four branches are 1, 3, 5, 7, r i r_i riThen it is 1, 2, 4, 8.
The blogger combined the paper and code flow to redraw the context exploration block structure diagram:

- The order of the four branches is sorted according to the size of the convolution kernel in the local feature extraction layer. The former branch will feed back the output features to the latter branch for further processing in a larger receptive field, and the latter branch will feed the output features of the previous branch to the latter branch. The output features and the output features of its own dimensionality reduction process are fused and added to output its own features;
- The outputs of all four branches are connected and then fused through 3×3 convolution to obtain the ability to perceive rich context in a wide range.
Code location: PFNet.py
class Context_Exploration_Block(nn.Module):
def __init__(self, input_channels):
super(Context_Exploration_Block, self).__init__()
self.input_channels = input_channels
self.channels_single = int(input_channels / 4)
# 1×1卷积用减少通道数降维
self.p1_channel_reduction = nn.Sequential(
nn.Conv2d(self.input_channels, self.channels_single, 1, 1, 0),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p2_channel_reduction = nn.Sequential(
nn.Conv2d(self.input_channels, self.channels_single, 1, 1, 0),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p3_channel_reduction = nn.Sequential(
nn.Conv2d(self.input_channels, self.channels_single, 1, 1, 0),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p4_channel_reduction = nn.Sequential(
nn.Conv2d(self.input_channels, self.channels_single, 1, 1, 0),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
# k×k用于局部特征提取
self.p1 = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, 1, 1, 0),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
# 使用空洞卷积用于上下文感知
self.p1_dc = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, kernel_size=3, stride=1, padding=1, dilation=1),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p2 = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, 3, 1, 1),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p2_dc = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, kernel_size=3, stride=1, padding=2, dilation=2),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p3 = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, 5, 1, 2),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p3_dc = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, kernel_size=3, stride=1, padding=4, dilation=4),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p4 = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, 7, 1, 3),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
self.p4_dc = nn.Sequential(
nn.Conv2d(self.channels_single, self.channels_single, kernel_size=3, stride=1, padding=8, dilation=8),
nn.BatchNorm2d(self.channels_single), nn.ReLU())
# 综合考虑所有的特征
self.fusion = nn.Sequential(nn.Conv2d(self.input_channels, self.input_channels, 1, 1, 0),
nn.BatchNorm2d(self.input_channels), nn.ReLU())
def forward(self, x):
p1_input = self.p1_channel_reduction(x)
p1 = self.p1(p1_input)
p1_dc = self.p1_dc(p1)
# 融合前一个分支输出和自身降维输出
p2_input = self.p2_channel_reduction(x) + p1_dc
p2 = self.p2(p2_input)
p2_dc = self.p2_dc(p2)
# 融合前一个分支输出和自身降维输出
p3_input = self.p3_channel_reduction(x) + p2_dc
p3 = self.p3(p3_input)
p3_dc = self.p3_dc(p3)
# 融合前一个分支输出和自身降维输出
p4_input = self.p4_channel_reduction(x) + p3_dc
p4 = self.p4(p4_input)
p4_dc = self.p4_dc(p4)
# 四个分支融合
ce = self.fusion(torch.cat((p1_dc, p2_dc, p3_dc, p4_dc), 1))
return ce
Summarize
Introduce the structure and code of the FM focusing module in the PFNet network as simply and in detail as possible.