[Backward solution and principle] There is a variable version number mechanism error in the network model during gradient update
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
Error report details
When the model is working backward, the following error is reported:

That is, RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation.
It roughly means that when calculating the gradient, a certain variable has been modified by the operation, which will cause the value of the variable to change during the subsequent process of calculating the gradient, thus causing problems in calculating the gradient.
Error background
The reason is that I want to reproduce a hierarchical multi-label classification network structure:
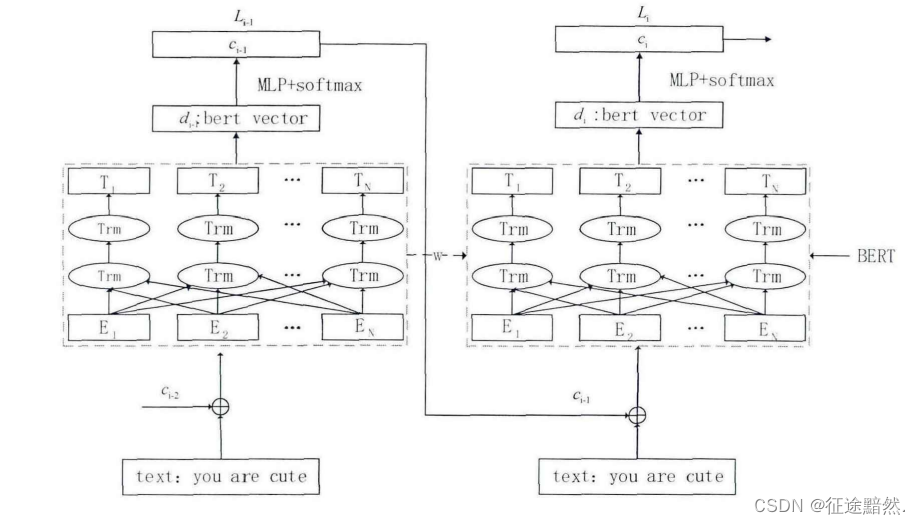
This import order x x xAfter passing through the BERT model once, the current predicted first-level label is obtained, and then spliced into the input sequence x x x, and then input it into the BERT model again to predict the secondary label.
The model structure of the faulty version is as follows:
def forward(self, x, label_A_emb):
context = x[0] # 输入的句子
mask = x[2]
d1 = self.bert(context, attention_mask=mask)
logit1 = self.fc1(d1[1]) # [batch_size, label_A_num] = [128, 34]
idx = torch.max(logit1.data, 1)[1] # [batch_size] = [128]
extra = label_A_emb[idx]
context[:, -3:] = extra
mask[:, -3:] = 1
d2 = self.bert(context, attention_mask=mask)
logit2 = self.fc2(d2[1]) # [batch_size, label_B_num] = [128, 34]
return logit1, logit2
When calculating the gradient, because the values of context and mask are modified once, an error will be reported.
principle
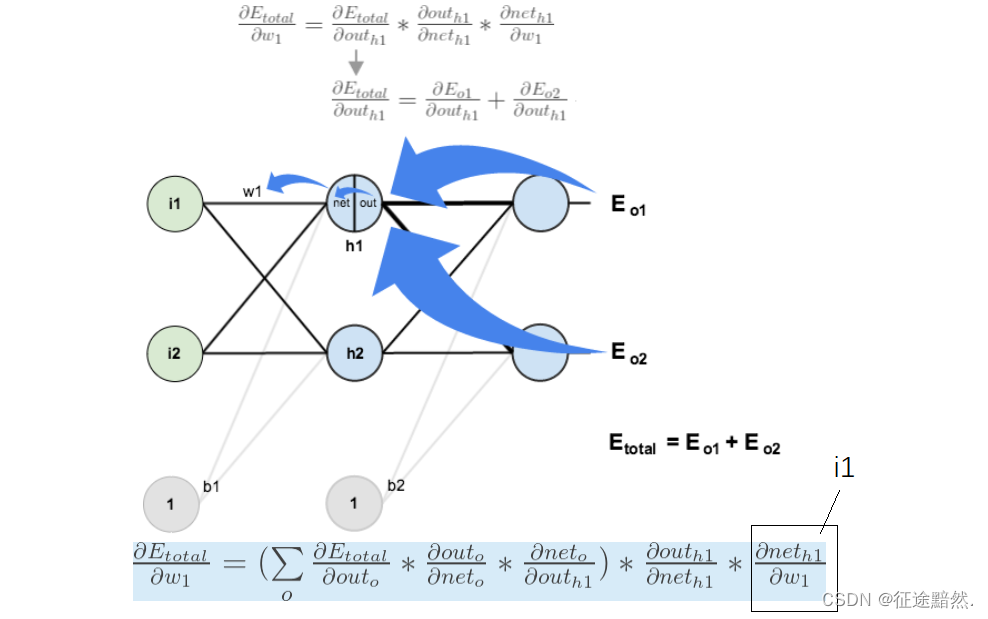
图中 w 1 w_1 In1The gradient calculation of is as shown above, and the loss function is E t o t a l E_{total} ANDtotal,End w 1 w_1 In1The gradient of needs to use the original input i 1 i_1 i1of.
So in the model structure code posted above, after the input passes through the neural network, it is changed again, and then passes through the neural network again. However, the gradient calculation will calculate the gradient twice, but it is found that the input only has the changed value, and the value before the change has been overwritten.
The version number mechanism when calculating gradients is a mechanism used in PyTorch to track the history of tensor operations. It allows PyTorch to efficiently manage and track relevant operations for automatic differentiation when gradients need to be calculated. Each tensor has a version number, which records the operation history of the tensor. When an inplace operation is performed on a tensor, such as modifying the tensor's value or rearranging the order of elements, the version number is incremented. This in-place operation can cause problems when calculating gradients, since gradient calculations rely on the history of operations.
solution
Make a deep copy of the variable that is about to be changed. The final optimized code is as follows:
def forward(self, x, label_A_emb):
context = x[0] # 输入的句子
mask = x[2]
d1 = self.bert(context, attention_mask=mask)
logit1 = self.fc1(d1[1]) # [batch_size, label_A_num] = [128, 34]
idx = torch.max(logit1.data, 1)[1] # [batch_size] = [128]
extra = label_A_emb[idx]
context_B = copy.deepcopy(context)
mask_B = copy.deepcopy(mask)
context_B[:, -3:] = extra
mask_B[:, -3:] = 1
d2 = self.bert_A(context_B, attention_mask=mask_B)
logit2 = self.fc2(d2[1]) # [batch_size, label_B_num] = [128, 34]
return logit1, logit2