The Huffman tree is a variable-length encoding method. Since elements with large weights are placed close to the root node and elements with small weights are placed far away from the root, the Huffman tree is very efficient, and a The encoding will not be prefixed with another encoding to avoid encoding ambiguity. This article will take you to explore how to create and use Huffman trees.

Construct Huffman tree
Constructing a Huffman tree with n elements requires 2n-1 nodes. Why is this result? Next, let’s take a look at the construction principle of the Huffman tree
- Select the two elements with the smallest weight from all elements (undetermined parent nodes)
- The sum of the weights of the selected elements is the weight of the new element (the new element will be the parent node of these two elements), and then the new element is put into the original element set (the parent node has been determined Then there is no need to put it back into the set). Now the number of elements in the set is -1, but the total number of elements is +1, because a new element is generated.
- Repeat steps 1 and 2 until there is only 1 element in the element set.
It is easy to see that a total of n-1 operations 1 and 2 need to be repeated (because the number of collection elements after each operation is -1, when the number of collection elements is 2, it is the last operation, and a total of n-1 operations) Each operation will generate a new element, so a total of n-1 new elements are generated, plus the original elements, a total of 2n-1
This conclusion can also be derived from the properties of binary trees: the Huffman tree is a binary tree without a node with degree 1, and there are n leaf nodes with degree zero. Since the binary tree The number of nodes with degree 2 is equal to the number of nodes with degree zero -1, so the node tree with degree 2 of the Huffman tree is n-1, so the summary point tree of the Huffman tree is n+n-1 =2n-1;
Here we use a structure array to maintain the Huffman tree. After knowing the principle, let’s take a look at the specific code:

#include <iostream>
using namespace std;
//最大元素个数
const int N=1e5;
typedef struct{
int parent;
int lchild,rchild;
int weight;
}HuffNode,*HUffTree;
//第0个位置不使用,下标从1开始
HuffNode tree[N*2];
void HuffMan(HuffNode tree[],int w[],int n){
//p1最小的权值的结点索引,p2第二小的结点的索引
int i,j,p1,p2;
int small1,small2;
//要求最小值,所以初始化要赋很大的值
small1=small2=0x3fff;
//初始化每个结点
for(i=1;i<=n;i++){
tree[i].weight=w[i];
tree[i].parent=0;
tree[i].lchild=0;
tree[i].rchild=0;
}
//初始化其他结点
for(;i<2*n;i++){
tree[i].parent=0;
tree[i].lchild=0;
tree[i].rchild=0;
}
for(i=n+1;i<2*n;i++){
for(j=1;j<i;j++){
//如果结点的双亲结点为0,说明改结点还在元素集合中
if(tree[j].parent==0){
if(tree[j].weight<small1){
//已经找到一个比原来最小的元素还小的元素,那原来最小的现在成了第二小
small2=small1;
p2=p1;
//更新最小元素
small1=tree[j].weight;
p1=j;
}
else if(tree[j].weight<small2){
small2=tree[j].weight;
p2=j;
}
}
}
//找到权值最小的两个结点后,要生成新的结点
tree[i].weight=small1+small2;
tree[i].lchild=p1;
tree[i].rchild=p2;
//更新最小的两个结点的双亲为新结点
tree[p1].parent=tree[p2].parent=i;
}
}
Huffman tree coding
On the Huffman tree that has been built, start from the leaf node and find the root along the parent node. Each step back will reach a branch, thereby obtaining a Huffman code value. Because the Huffman code of each character is a sequence of 0 and 1 on the path branch from the root node to the leaf node, the code obtained first is the low code, and the code obtained later is the high code. You can set a two-dimensional character array to save each Huffman code.
char HuffManCode[N][N];
void huffmancodding(HuffNode tree[],int n){
//存储每次循环后字符的哈夫曼编码
char * tem = (char*)malloc(n*(sizeof(char)));
int parent;
//结束标志
tem[n-1] = '\0';
//叶子结点是前n个结点
for(int i =1;i<=n;i++){
int idx=n-1;
for(int j =i;tree[j].parent!=0;j=tree[j].parent){
//得到双亲结点
parent = tree[j].parent;
//左分支为 0,右分支为 1
if(tree[parent].lchild==j){
tem[--idx]='0';
}
else{
tem[--idx]='1';
}
}
//在C语言中,数组是一个连续存储的数据结构,其中每个元素都有一个固定的地址。数组名实际上是指向数组第一个元素的指针。
//对于二维数组b[n][m],它实际上是按行优先或列优先的方式在内存中进行存储的一维数组。
// 因此,b[i]实际上是代表了第i+1行(如果从0开始计数)的首地址,也就是指向这一行第一个元素的指针。
strcpy(HuffManCode[i],&tem[idx]);
}
free(tem);
for(int i =1;i<=n;i++)
printf("%d: %s\n",i,HuffManCode[i]);
}
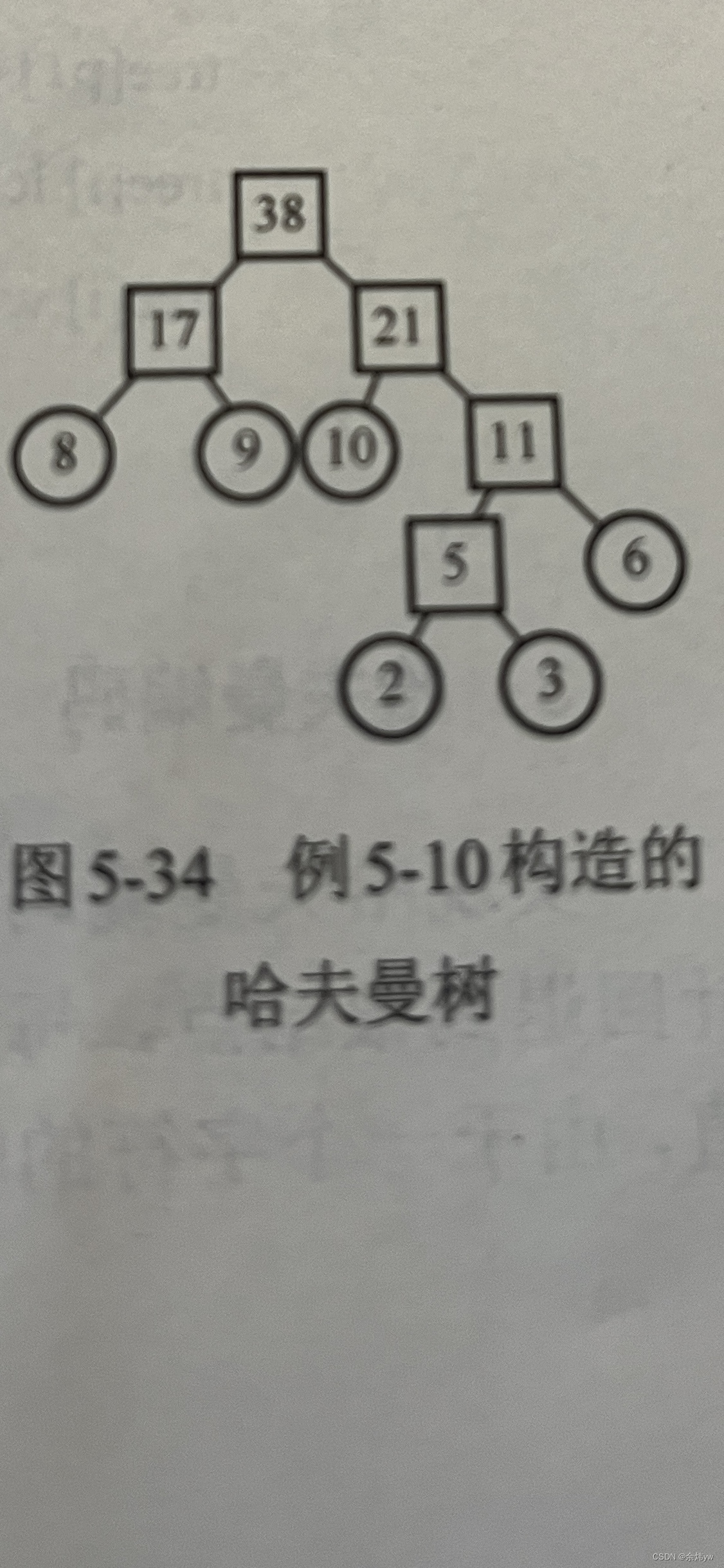
test
Check our code according to this picture

#include <iostream>
#include <cstring>
using namespace std;
//最大元素个数
const int N=100;
typedef struct{
int parent;
int lchild,rchild;
int weight;
}HuffNode;
//第0个位置不使用,下标从1开始
HuffNode tree[N*2];
void HuffMan(HuffNode tree[],int w[],int n){
//p1最小的权值的结点索引,p2第二小的结点的索引
int i,j,p1,p2;
int small1,small2;
//要求最小值,所以初始化要赋很大的值
small1=small2=0x3fff;
//初始化每个结点
for(i=1;i<=n;i++){
tree[i].weight=w[i];
tree[i].parent=0;
tree[i].lchild=0;
tree[i].rchild=0;
}
//初始化其他结点
for(;i<2*n;i++){
tree[i].parent=0;
tree[i].lchild=0;
tree[i].rchild=0;
}
for(i=n+1;i<2*n;i++){
small1=small2=0x3fff;
for(j=1;j<i;j++){
//如果结点的双亲结点为0,说明改结点还在元素集合中
if(tree[j].parent==0){
if(tree[j].weight<small1){
//已经找到一个比原来最小的元素还小的元素,那原来最小的现在成了第二小
small2=small1;
p2=p1;
//更新最小元素
small1=tree[j].weight;
p1=j;
}
else if(tree[j].weight<small2){
small2=tree[j].weight;
p2=j;
}
}
}
//找到权值最小的两个结点后,要生成新的结点
tree[i].weight=small1+small2;
tree[i].lchild=p1;
tree[i].rchild=p2;
//更新最小的两个结点的双亲为新结点
tree[p1].parent=tree[p2].parent=i;
}
}
char HuffManCode[N][N];
void huffmancodding(HuffNode tree[],int n){
//存储每次循环后字符的哈夫曼编码
char * tem = (char*)malloc(n*(sizeof(char)));
int parent;
//结束标志
tem[n-1] = '\0';
//叶子结点是前n个结点
for(int i =1;i<=n;i++){
int idx=n-1;
for(int j =i;tree[j].parent!=0;j=tree[j].parent){
//得到双亲结点
parent = tree[j].parent;
//左分支为 0,右分支为 1
if(tree[parent].lchild==j){
tem[--idx]='0';
}
else{
tem[--idx]='1';
}
}
//在C语言中,数组是一个连续存储的数据结构,其中每个元素都有一个固定的地址。数组名实际上是指向数组第一个元素的指针。
//对于二维数组b[n][m],它实际上是按行优先或列优先的方式在内存中进行存储的一维数组。
// 因此,b[i]实际上是代表了第i+1行(如果从0开始计数)的首地址,也就是指向这一行第一个元素的指针。
strcpy(HuffManCode[i],&tem[idx]);
}
free(tem);
for(int i =1;i<=n;i++)
printf("%d: %s\n",i,HuffManCode[i]);
}
int main(){
int w[7]={
0,6,2,3,9,10,8};
HuffMan(tree,w,6);
huffmancodding(tree,6);
}

Summarize
This article introduces the creation of Huffman trees and how to code them. I hope this article can help readers who are learning Huffman trees.