Huffman Tree
Related concepts
Weighted path length of binary tree:
Suppose a binary tree has n weighted leaf nodes, the sum of the product of the length of the path from the root node to each leaf node and the weight of the corresponding leaf node. Recorded as:

Example:
Given 4 leaf nodes, their weights are {2, 3, 4, 7} respectively, and binary
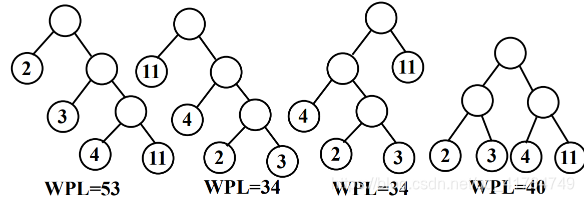
trees with different shapes can be constructed. Huffman trees with different shapes : Given a set of leaves with certain weights The node, the binary tree with the smallest weighted path length, is called the Huffman tree, also known as the optimal binary tree.
The characteristics of the Huffman tree:
- The leaf node with a larger weight is closer to the root node, and a leaf node with a smaller weight is farther away from the root node. (The core idea of constructing Huffman tree)
- There are only nodes with degree 0 (leaf node) and degree 2 (branch node), and no node with degree 1 exists.
- The total number of nodes in a Huffman tree with n leaf nodes is 2n-1.
- The Huffman tree is not unique, but the WPL is unique.
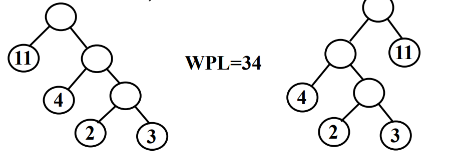
Huffman tree creation
Steps to form a Huffman tree:
- Sort from small to large, each data, each data is a node, each node can be regarded as the simplest binary tree
- Take out the two binary trees with the smallest root node weight
- To form a new binary tree, the weight of the root node of the new binary tree is the sum of the weights of the root nodes of the previous two binary trees
- Then sort this new binary tree again by the weight of the root node, and repeat the steps of 1-2-3-4 until all the data in the sequence are processed, and a Huffman tree is obtained
Illustrated example: {13, 7, 8, 3, 29, 6, 1}
Sort
{1, 3, 6, 7, 8, 13, 29} to
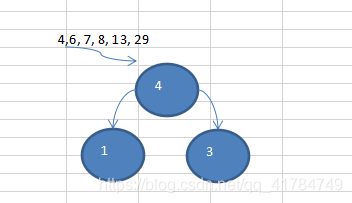
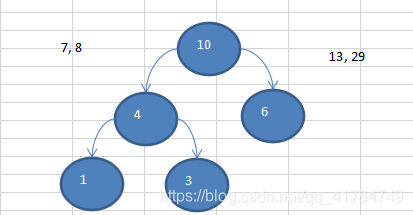
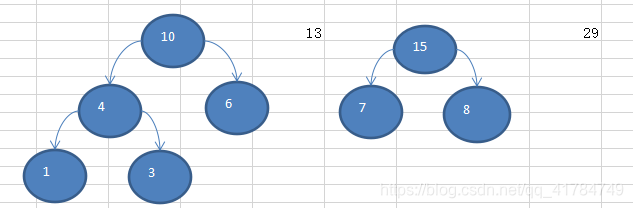
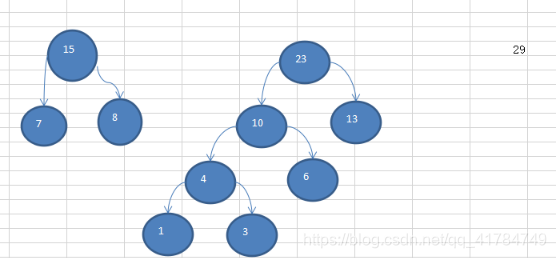
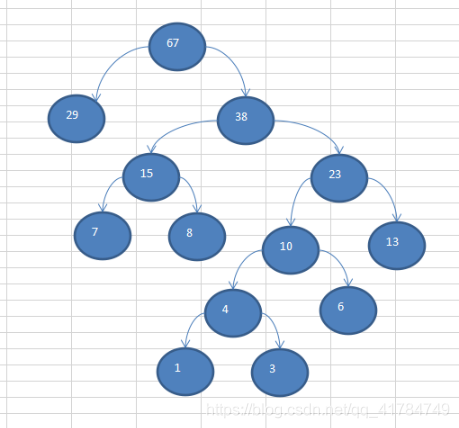
create a Huffman tree code implementation
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class HuffmanTree {
public static void main(String[] args) {
int arr[] = {
13, 7, 8, 3, 29, 6, 1 };
Node root = createHuffmanTree(arr);
//测试一把
preOrder(root); //
}
//编写一个前序遍历的方法
public static void preOrder(Node root) {
if(root != null) {
root.preOrder();
}else{
System.out.println("是空树,不能遍历~~");
}
}
// 创建赫夫曼树的方法
/**
*
* @param arr 需要创建成哈夫曼树的数组
* @return 创建好后的赫夫曼树的root结点
*/
public static Node createHuffmanTree(int[] arr) {
// 第一步为了操作方便
// 1. 遍历 arr 数组
// 2. 将arr的每个元素构成成一个Node
// 3. 将Node 放入到ArrayList中
List<Node> nodes = new ArrayList<Node>();
for (int value : arr) {
nodes.add(new Node(value));
}
//我们处理的过程是一个循环的过程
while(nodes.size() > 1) {
//排序 从小到大
Collections.sort(nodes);
// System.out.println("nodes =" + nodes);
//取出根节点权值最小的两颗二叉树
//(1) 取出权值最小的结点(二叉树)
Node leftNode = nodes.get(0);
//(2) 取出权值第二小的结点(二叉树)
Node rightNode = nodes.get(1);
//(3)构建一颗新的二叉树
Node parent = new Node(leftNode.value + rightNode.value);
parent.left = leftNode;
parent.right = rightNode;
//(4)从ArrayList删除处理过的二叉树
nodes.remove(leftNode);
nodes.remove(rightNode);
//(5)将parent加入到nodes
nodes.add(parent);
}
//返回哈夫曼树的root结点
return nodes.get(0);
}
}
// 创建结点类
// 为了让Node 对象持续排序Collections集合排序
// 让Node 实现Comparable接口
class Node implements Comparable<Node> {
int value; // 结点权值
char c; //字符
Node left; // 指向左子结点
Node right; // 指向右子结点
//写一个前序遍历
public void preOrder() {
System.out.println(this);
if(this.left != null) {
this.left.preOrder();
}
if(this.right != null) {
this.right.preOrder();
}
}
public Node(int value) {
this.value = value; }
@Override
public String toString() {
return "Node [value=" + value + "]"; }
@Override
public int compareTo(Node o) {
// TODO Auto-generated method stub
// 表示从小到大排序
return this.value - o.value;
}
}
Huffman coding
basic introduction
Huffman coding is also translated as Huffman coding (Huffman Coding), also known as Huffman coding, coding is a way, is a kind of program algorithm
Huffman coding is Hehafuman tree classic telecommunications Communication One of the applications.
Huffman coding is widely used for data file compression. The compression rate is usually between 20% and 90%.
Huffman code is a type of variable word length coding (VLC). Huffman proposed a coding method in 1952, called the best coding
Related terms
Prefix of code : If any code in a group of codes is not a prefix of any other code, it is said that this code has prefix property, which is called prefix code for short.
- Prefix encoding guarantees uniqueness during decoding (decoding).
- The equal length coding has a prefix;
- Variable-length coding may cause ambiguity in decoding, that is, it does not have prefixes. For example, E(00), T(01), W(0001), it is impossible to determine whether the binary string 0001 is ET or W during decoding.
Average code length:
- For a given character set (a set of objects), there may be multiple encoding schemes, but the optimal one should be selected.
- Average encoding length: Set the probability of occurrence of each (object) character cj as pj, and its binary bit string length (code length) as lj, then ∑lj·pj represents the average encoding length of the group of objects (characters).
- Optimal prefix code: the prefix code that minimizes the average code length ∑lj·pj is called the optimal prefix code
Principle analysis
Information processing method in the communication field 1-fixed-length coding:
i like like like java do you like a java // A total of 40 characters (including spaces)
correspond to the Ascii code:
105 32 108 105 107 101 32 108 105 107 101 32 108 105 107 101 32 106 97 118 97 32 100 111 32 121 111 117 32 108 105 107 101 32 97 32 106 97 118 97
Corresponding binary
01101001 00100000 01101100 01101001 01101011 01100101 00100000 01101100 01101001 01101011 01100101 00100000 01101100 01101001 01101011 01100101 00100000 01101010 01100001 01101111 01100000 01100001 001101111 01101001001001001001001001001001001001001001001001001001001001001001001001001001001001001101001001001001001001101001001101001001101001001101001101001101001101001101001 00100000 01100001 00100000 01101010 01100001 01110110 01100001
The information is transmitted in binary, the total length is 359 (including spaces)
Information Processing Method in the Communication Field-Huffman Coding
i like like like java do you like a java // 40 characters in total (including spaces)
The corresponding number of each character:
d:1 y:1 u:1 j:2 v:2 o:2 l:4 k:4 e:4 i:5 a:5 :9
Construct a Huffman tree according to the number of occurrences of the above characters, and the number of times is the weight. (After the figure)
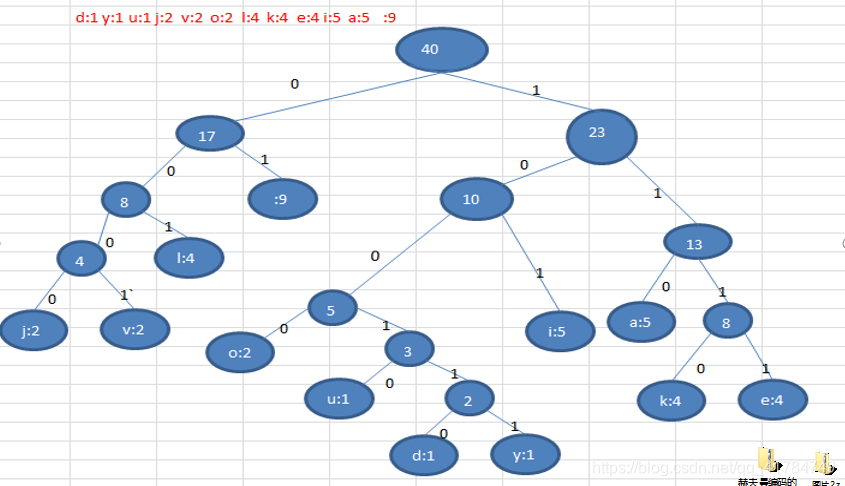
According to the Huffman tree, the code is specified for each character. The path to the left is 0 and the path to the right is 1. The encoding is as follows :
o: 1000 u: 10010 d: 100110 y: 100111 i: 101 a: 110 k: 1110 e: 1111 j: 0000 v: 0001 l: 001: 01
According to the Huffman encoding above, our "i like like like java do you like a java" string corresponds to the encoding (note the lossless compression we use here)
1010100110111101111010011011110111101001101111011110100001100001110011001111000011001111000100100100110111101111011100100001100001110
The length is: 133
Description: The
original length is 359, compressed (359-133) / 359 = 62.9%
This code satisfies the prefix code, that is, the character code cannot be the prefix of other character codes. Will not cause ambiguity in matching
Note: This Huffman tree may be different depending on the sorting method, so the corresponding Huffman codes are not exactly the same, but the wpl is the same, and they are all the smallest.
An Algorithm for Finding the Optimal Prefix Encoding of a Character Set Using Huffman Algorithm
- Make each character in the character set correspond to a binary tree with only leaf nodes, and the weight of the leaf is the frequency of use of the corresponding character----initialization
- Use the huffman algorithm to construct a huffman tree-construction algorithm
- For each node on the huffman tree, attach 0 to the left branch and 1 to the right branch (or vice versa), then the sequence of 0 and 1 on the path from the root to the leaf is the code of the corresponding character----Huff Man code
- And is the optimal prefix code
Example: The
transmitted character string
(1) i like like like java do you like a java
(2) d:1 y:1 u:1 j:2 v:2 o:2 l:4 k:4 e:4 i:5 a:5 :9 // the number of each character
(3) Construct a Huffman tree according to the number of occurrences of the above characters, with the number as the weight
Steps to form a Huffman tree:
- Sort from small to large, each data, each data is a node, each node can be regarded as the simplest binary tree
- Take out the two binary trees with the smallest root node weight
- To form a new binary tree, the weight of the root node of the new binary tree is the sum of the weights of the root nodes of the previous two binary trees
- Then sort this new binary tree again by the weight of the root node, and repeat the steps of 1-2-3-4 until all the data in the sequence are processed, and a Huffman tree is obtained
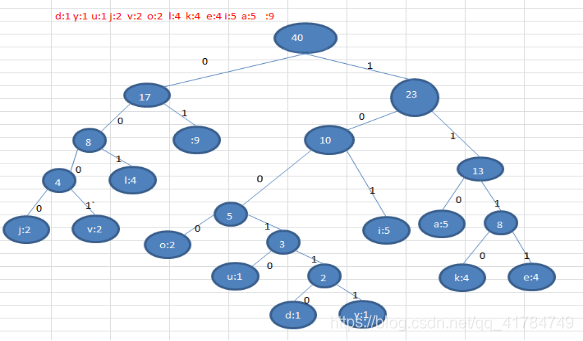
(4) According to the Huffman tree, specify the code (prefix code) for each character. The path to the left is 0 and the path to the right is 1. The codes are as follows:
o: 1000 u: 10010 d: 100110 y: 100111 i: 101 a: 110 k: 1110 e: 1111 j: 0000 v: 0001
l: 001: 01
(5) According to the Huffman encoding above, the encoding corresponding to our "i like like like java do you like a java" string is (note the lossless compression we use here)
10101001101111011110100110111101111010011011110111101000011000011100110011001111000011001111000100100100110111101111011100100001100001110 The length of the Huffman encoding process is 133
(6) The length is: 133
Description: The
original length is 359, compressed (359-133) / 359 = 62.9%
This code satisfies the prefix code, that is, the character code cannot be the prefix of other character codes. Will not cause ambiguity in matching.
Huffman coding is a lossless processing solution
Code
import java.util.*;
/**
* @anthor longzx
* @create 2021 02 04 11:25
* @Description
**/
public class HuffmanCode {
//生成赫夫曼树对应的赫夫曼编码
//思路:
//1. 将赫夫曼编码表存放在 Map<Byte,String> 形式
// 生成的赫夫曼编码表{32=01, 97=100, 100=11000, 117=11001, 101=1110, 118=11011, 105=101, 121=11010, 106=0010, 107=1111, 108=000, 111=0011}
static Map<Byte, String> huffmanCodes = new HashMap<Byte,String>();
//2. 在生成赫夫曼编码表示,需要去拼接路径, 定义一个StringBuilder 存储某个叶子结点的路径
static StringBuilder stringBuilder = new StringBuilder();
public static void main(String[] args) {
String content = "i like like like java do you like a java";
byte[] contentBytes = content.getBytes();
System.out.println(contentBytes.length); //40
List<Node> nodes = getNodes(contentBytes);
System.out.println("nodes:"+nodes);
//创建哈夫曼树
System.out.println("哈夫曼树");
Node huffmanTreeRoot = createHuffmanTree(nodes);
huffmanTreeRoot.preOrder();
//生成哈夫曼编码
getCodes(huffmanTreeRoot,"",stringBuilder);
System.out.println("生成的哈夫曼编码:" + huffmanCodes);
}
/**
* 功能:将传入的node结点的所有叶子结点的赫夫曼编码得到,并放入到huffmanCodes集合
* @param node 传入结点
* @param code 路径: 左子结点是 0, 右子结点 1
* @param stringBuilder 用于拼接路径
*/
private static void getCodes(Node node, String code, StringBuilder stringBuilder) {
StringBuilder stringBuilder2 = new StringBuilder(stringBuilder);
//将code 加入到 stringBuilder2
stringBuilder2.append(code);
if(node != null) {
//如果node == null不处理
//判断当前node 是叶子结点还是非叶子结点
if(node.data == null) {
//非叶子结点
//递归处理
//向左递归
getCodes(node.left, "0", stringBuilder2);
//向右递归
getCodes(node.right, "1", stringBuilder2);
} else {
//说明是一个叶子结点
//就表示找到某个叶子结点的最后
huffmanCodes.put(node.data, stringBuilder2.toString());
}
}
}
/**
*
* @param bytes 接收字节数组
* @return 返回的就是 List 形式 [Node[date=97 ,weight = 5], Node[]date=32,weight = 9]......],
*/
private static List<Node> getNodes(byte[] bytes) {
//1创建一个ArrayList
ArrayList<Node> nodes = new ArrayList<Node>();
//遍历 bytes , 统计 每一个byte出现的次数->map[key,value]
Map<Byte, Integer> counts = new HashMap<>();
for (byte b : bytes) {
Integer count = counts.get(b);
if (count == null) {
// Map还没有这个字符数据,第一次
counts.put(b, 1);
} else {
counts.put(b, count + 1);
}
}
//把每一个键值对转成一个Node 对象,并加入到nodes集合
//遍历map
for(Map.Entry<Byte, Integer> entry: counts.entrySet()) {
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
}
//可以通过List 创建对应的赫夫曼树
private static Node createHuffmanTree(List<Node> nodes) {
while(nodes.size() > 1) {
//排序, 从小到大
Collections.sort(nodes);
//取出第一颗最小的二叉树
Node leftNode = nodes.get(0);
//取出第二颗最小的二叉树
Node rightNode = nodes.get(1);
//创建一颗新的二叉树,它的根节点 没有data, 只有权值
Node parent = new Node(null, leftNode.weight + rightNode.weight);
parent.left = leftNode;
parent.right = rightNode;
//将已经处理的两颗二叉树从nodes删除
nodes.remove(leftNode);
nodes.remove(rightNode);
//将新的二叉树,加入到nodes
nodes.add(parent);
}
//nodes 最后的结点,就是赫夫曼树的根结点
return nodes.get(0);
}
}
//创建Node ,待数据和权值
class Node implements Comparable<Node> {
Byte data; // 存放数据(字符)本身,比如'a' => 97 ' ' => 32
int weight; //权值, 表示字符出现的次数
Node left;//
Node right;
public Node(Byte data, int weight) {
this.data = data;this.weight = weight; }
@Override
public int compareTo(Node o) {
// 从小到大排序
return this.weight - o.weight;
}
public String toString() {
return "Node [data = " + data + " weight=" + weight + "]"; }
//前序遍历
public void preOrder() {
System.out.println(this);
if(this.left != null) {
this.left.preOrder();
}
if(this.right != null) {
this.right.preOrder();
}
}
}