Project address: https://github.com/zhulf0804/ROPNet in MVP Registration Challenge (ICCV Workshop 2021) Won the second place in (ICCV Workshop 2021). The project can be run in win10 environment.
Paper address: https://arxiv.org/abs/2107.02583
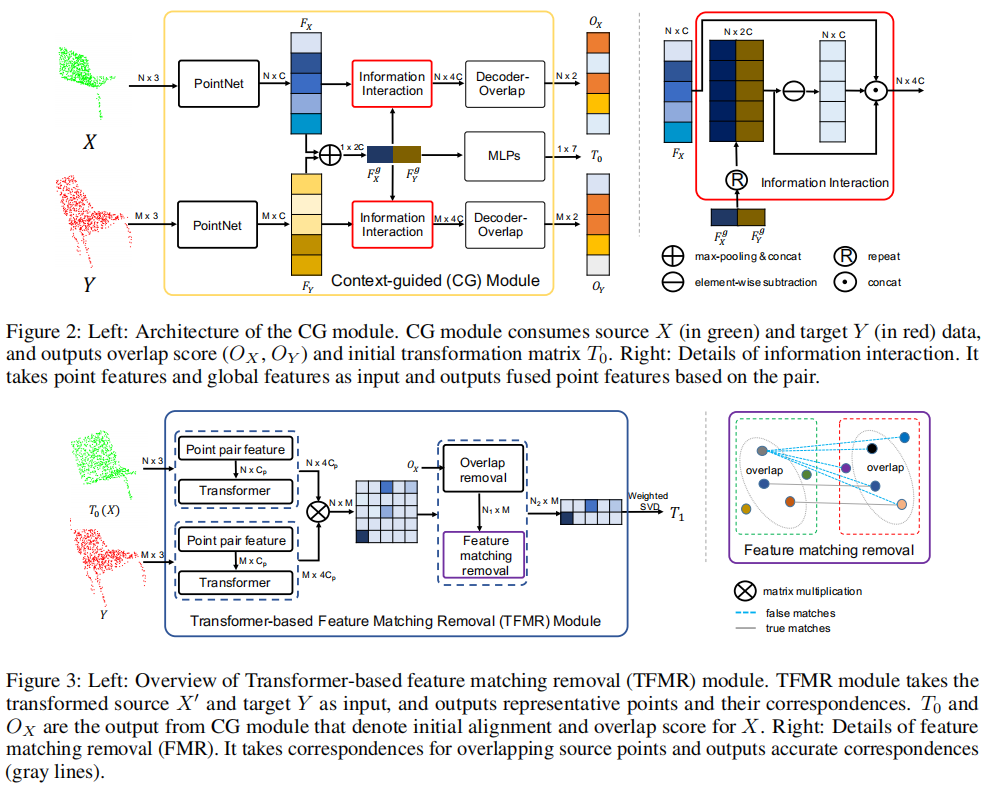
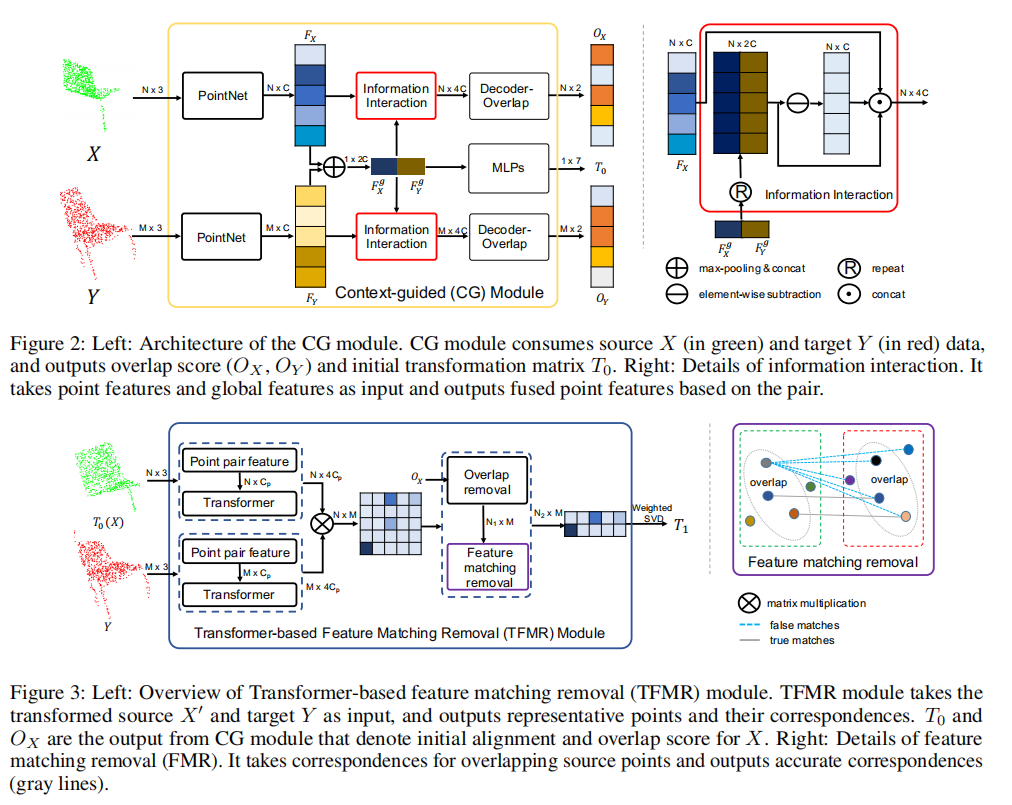
Network introduction: A new deep learning model that utilizes representative overlapping points with distinctive features for registration, converting part-to-part registration into part-complete Registration. A context guidance module is designed based on the features output by pointnet, and an encoder is used to extract global features to predict point overlap scores. To better find representative overlapping points, the extracted global features are used for coarse alignment. Then, a transformer is introduced to enrich point features and remove non-representative points based on point overlap scores and feature matching. The similarity matrix is built in partial to complete mode, and finally the weighted support vector difference is used to estimate the transformation matrix.
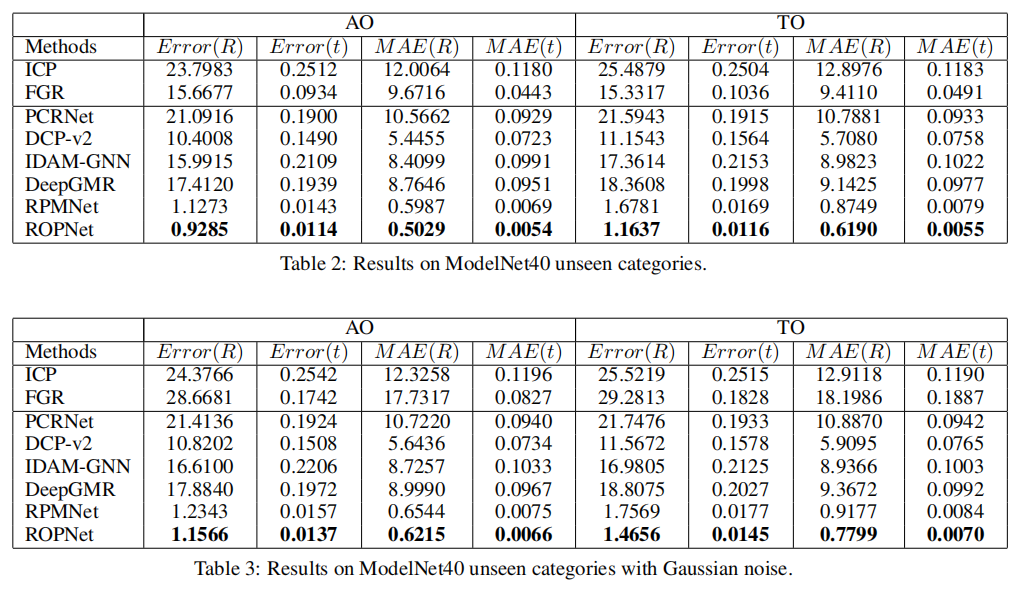
Implementation effect: From the data point of view, ROPNet and RPMNet have maintained a cliff-like leading position
1. Operating environment installation
1.1 Project download
Openhttps://github.com/zhulf0804/ROPNet, click Download ZIP and extract the code to the specified directory.
1.2 Dependency installation
In the environment terminal where pytorch is installed, enter the ROPNet-master/src directory and execute the following installation command. If you have already installed the torch environment and open3d package, there is no need to install it again.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install open3d
1.3 Model and data download
modelnet40 data set here [435M]
Just download the data set and store it in the following path.
Official website pre-trained model, none.
Third-party pre-trained model: Model trained on the modelnet40 data set using the ROPNet project
2. Key code
2.1 data loader
The dataloader provided by the author can only loadhttps://shapenet.cs.stanford.edu/media/modelnet40_ply_hdf5_2048.zip data set , the tgt_cloud and src_cloud returned are essentially based on a point cloud sample. 其中的self.label2cat, self.cat2label, self.symmetric_labels等对象代码实际上是没有任何作用的。
import copy
import h5py
import math
import numpy as np
import os
import torch
from torch.utils.data import Dataset
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOR_DIR = os.path.dirname(BASE_DIR)
sys.path.append(ROOR_DIR)
from utils import random_select_points, shift_point_cloud, jitter_point_cloud, \
generate_random_rotation_matrix, generate_random_tranlation_vector, \
transform, random_crop, shuffle_pc, random_scale_point_cloud, flip_pc
half1 = ['airplane', 'bathtub', 'bed', 'bench', 'bookshelf', 'bottle', 'bowl',
'car', 'chair', 'cone', 'cup', 'curtain', 'desk', 'door', 'dresser',
'flower_pot', 'glass_box', 'guitar', 'keyboard', 'lamp']
half1_symmetric = ['bottle', 'bowl', 'cone', 'cup', 'flower_pot', 'lamp']
half2 = ['laptop', 'mantel', 'monitor', 'night_stand', 'person', 'piano',
'plant', 'radio', 'range_hood', 'sink', 'sofa', 'stairs', 'stool',
'table', 'tent', 'toilet', 'tv_stand', 'vase', 'wardrobe', 'xbox']
half2_symmetric = ['tent', 'vase']
class ModelNet40(Dataset):
def __init__(self, root, split, npts, p_keep, noise, unseen, ao=False,
normal=False):
super(ModelNet40, self).__init__()
self.single = False # for specific-class visualization
assert split in ['train', 'val', 'test']
self.split = split
self.npts = npts
self.p_keep = p_keep
self.noise = noise
self.unseen = unseen
self.ao = ao # Asymmetric Objects
self.normal = normal
self.half = half1 if split in 'train' else half2
self.symmetric = half1_symmetric + half2_symmetric
self.label2cat, self.cat2label = self.label2category(
os.path.join(root, 'shape_names.txt'))
self.half_labels = [self.cat2label[cat] for cat in self.half]
self.symmetric_labels = [self.cat2label[cat] for cat in self.symmetric]
files = [os.path.join(root, 'ply_data_train{}.h5'.format(i))
for i in range(5)]
if split == 'test':
files = [os.path.join(root, 'ply_data_test{}.h5'.format(i))
for i in range(2)]
self.data, self.labels = self.decode_h5(files)
print(f'split: {
self.split}, unique_ids: {
len(np.unique(self.labels))}')
if self.split == 'train':
self.Rs = [generate_random_rotation_matrix() for _ in range(len(self.data))]
self.ts = [generate_random_tranlation_vector() for _ in range(len(self.data))]
def label2category(self, file):
with open(file, 'r') as f:
label2cat = [category.strip() for category in f.readlines()]
cat2label = {
label2cat[i]: i for i in range(len(label2cat))}
return label2cat, cat2label
def decode_h5(self, files):
points, normal, label = [], [], []
for file in files:
f = h5py.File(file, 'r')
cur_points = f['data'][:].astype(np.float32)
cur_normal = f['normal'][:].astype(np.float32)
cur_label = f['label'][:].flatten().astype(np.int32)
if self.unseen:
idx = np.isin(cur_label, self.half_labels)
cur_points = cur_points[idx]
cur_normal = cur_normal[idx]
cur_label = cur_label[idx]
if self.ao and self.split in ['val', 'test']:
idx = ~np.isin(cur_label, self.symmetric_labels)
cur_points = cur_points[idx]
cur_normal = cur_normal[idx]
cur_label = cur_label[idx]
if self.single:
idx = np.isin(cur_label, [8])
cur_points = cur_points[idx]
cur_normal = cur_normal[idx]
cur_label = cur_label[idx]
points.append(cur_points)
normal.append(cur_normal)
label.append(cur_label)
points = np.concatenate(points, axis=0)
normal = np.concatenate(normal, axis=0)
data = np.concatenate([points, normal], axis=-1).astype(np.float32)
label = np.concatenate(label, axis=0)
return data, label
def compose(self, item, p_keep):
tgt_cloud = self.data[item, ...]
if self.split != 'train':
np.random.seed(item)
R, t = generate_random_rotation_matrix(), generate_random_tranlation_vector()
else:
tgt_cloud = flip_pc(tgt_cloud)
R, t = generate_random_rotation_matrix(), generate_random_tranlation_vector()
src_cloud = random_crop(copy.deepcopy(tgt_cloud), p_keep=p_keep[0])
src_size = math.ceil(self.npts * p_keep[0])
tgt_size = self.npts
if len(p_keep) > 1:
tgt_cloud = random_crop(copy.deepcopy(tgt_cloud),
p_keep=p_keep[1])
tgt_size = math.ceil(self.npts * p_keep[1])
src_cloud_points = transform(src_cloud[:, :3], R, t)
src_cloud_normal = transform(src_cloud[:, 3:], R)
src_cloud = np.concatenate([src_cloud_points, src_cloud_normal],
axis=-1)
src_cloud = random_select_points(src_cloud, m=src_size)
tgt_cloud = random_select_points(tgt_cloud, m=tgt_size)
if self.split == 'train' or self.noise:
src_cloud[:, :3] = jitter_point_cloud(src_cloud[:, :3])
tgt_cloud[:, :3] = jitter_point_cloud(tgt_cloud[:, :3])
tgt_cloud, src_cloud = shuffle_pc(tgt_cloud), shuffle_pc(
src_cloud)
return src_cloud, tgt_cloud, R, t
def __getitem__(self, item):
src_cloud, tgt_cloud, R, t = self.compose(item=item,
p_keep=self.p_keep)
if not self.normal:
tgt_cloud, src_cloud = tgt_cloud[:, :3], src_cloud[:, :3]
return tgt_cloud, src_cloud, R, t
def __len__(self):
return len(self.data)
2.2 Model design
The model design is as follows:
2.3 loss design
It mainly includes Init_loss, Refine_loss and Ol_loss.
Where Init_loss is used to calculate Predicted point cloud 0 Predicted point cloud_0 预浦PointYun0Mse or mae loss with the target point cloud,
Refine_loss is used to calculate Predicted point cloud [ 1 : ] Predicted point cloud_{[ 1:]} 预浦PointYun[1:]With the target point cloudWeighted mae loss
Ol_loss is used to calculate the overlap score of the output of the two input point clouds, so that the two point clouds The overlap scores of corresponding points are the same.

The specific implementation code is as follows:
import math
import torch
import torch.nn as nn
from utils import square_dists
def Init_loss(gt_transformed_src, pred_transformed_src, loss_type='mae'):
losses = {
}
num_iter = 1
if loss_type == 'mse':
criterion = nn.MSELoss(reduction='mean')
for i in range(num_iter):
losses['mse_{}'.format(i)] = criterion(pred_transformed_src[i],
gt_transformed_src)
elif loss_type == 'mae':
criterion = nn.L1Loss(reduction='mean')
for i in range(num_iter):
losses['mae_{}'.format(i)] = criterion(pred_transformed_src[i],
gt_transformed_src)
else:
raise NotImplementedError
total_losses = []
for k in losses:
total_losses.append(losses[k])
losses = torch.sum(torch.stack(total_losses), dim=0)
return losses
def Refine_loss(gt_transformed_src, pred_transformed_src, weights=None, loss_type='mae'):
losses = {
}
num_iter = len(pred_transformed_src)
for i in range(num_iter):
if weights is None:
losses['mae_{}'.format(i)] = torch.mean(
torch.abs(pred_transformed_src[i] - gt_transformed_src))
else:
losses['mae_{}'.format(i)] = torch.mean(torch.sum(
weights * torch.mean(torch.abs(pred_transformed_src[i] -
gt_transformed_src), dim=-1)
/ (torch.sum(weights, dim=-1, keepdim=True) + 1e-8), dim=-1))
total_losses = []
for k in losses:
total_losses.append(losses[k])
losses = torch.sum(torch.stack(total_losses), dim=0)
return losses
def Ol_loss(x_ol, y_ol, dists):
CELoss = nn.CrossEntropyLoss()
x_ol_gt = (torch.min(dists, dim=-1)[0] < 0.05 * 0.05).long() # (B, N)
y_ol_gt = (torch.min(dists, dim=1)[0] < 0.05 * 0.05).long() # (B, M)
x_ol_loss = CELoss(x_ol, x_ol_gt)
y_ol_loss = CELoss(y_ol, y_ol_gt)
ol_loss = (x_ol_loss + y_ol_loss) / 2
return ol_loss
def cal_loss(gt_transformed_src, pred_transformed_src, dists, x_ol, y_ol):
losses = {
}
losses['init'] = Init_loss(gt_transformed_src,
pred_transformed_src[0:1])
if x_ol is not None:
losses['ol'] = Ol_loss(x_ol, y_ol, dists)
losses['refine'] = Refine_loss(gt_transformed_src,
pred_transformed_src[1:],
weights=None)
alpha, beta, gamma = 1, 0.1, 1
if x_ol is not None:
losses['total'] = losses['init'] + beta * losses['ol'] + gamma * losses['refine']
else:
losses['total'] = losses['init'] + losses['refine']
return losses
3. Training and prediction
First enter the src directory and unzip modelnet40_ply_hdf5_2048.zip in the src directory
3.1 Training
The training command and training output are as follows
python train.py --root modelnet40_ply_hdf5_2048/ --noise --unseen
python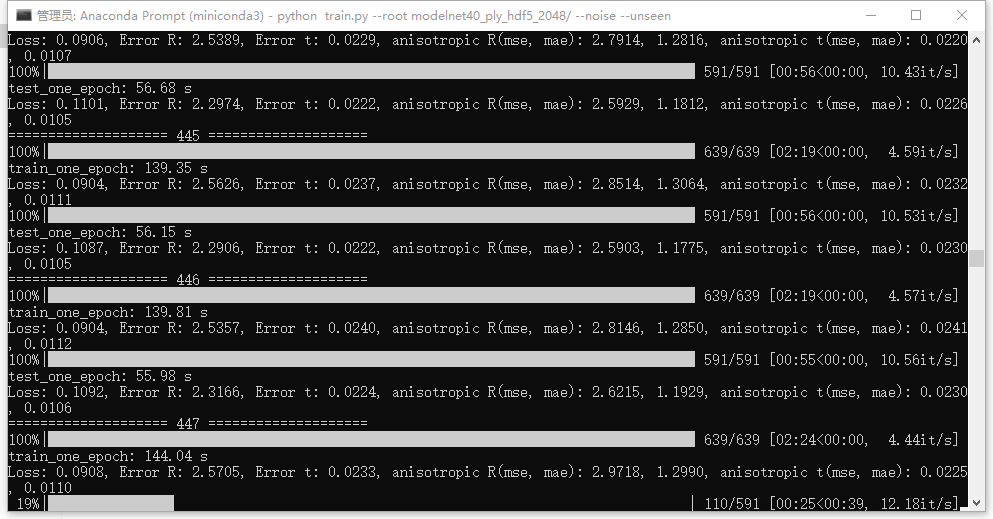
During the training process, two model files will be generated in the work_dirs\models\checkpoints directory
3.2 Verification
The training command and training output are as follows
python eval.py --root modelnet40_ply_hdf5_2048/ --unseen --noise --cuda --checkpoint work_dirs/models/checkpoints/min_rot_error.pth
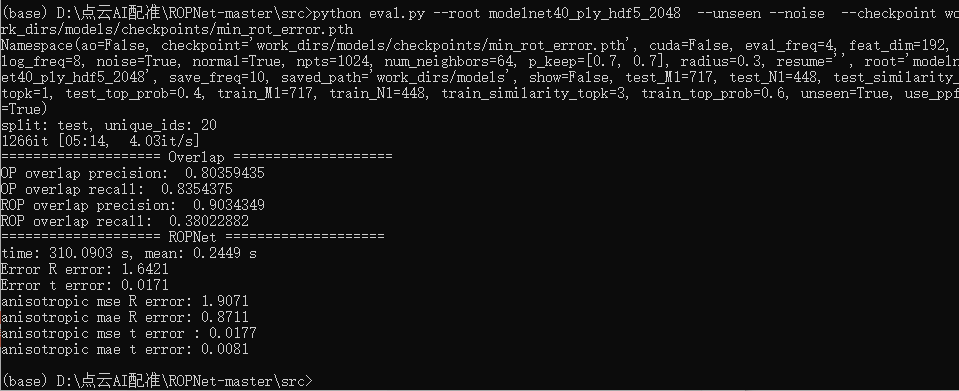
3.3 Testing
The command to test the training data is as follows
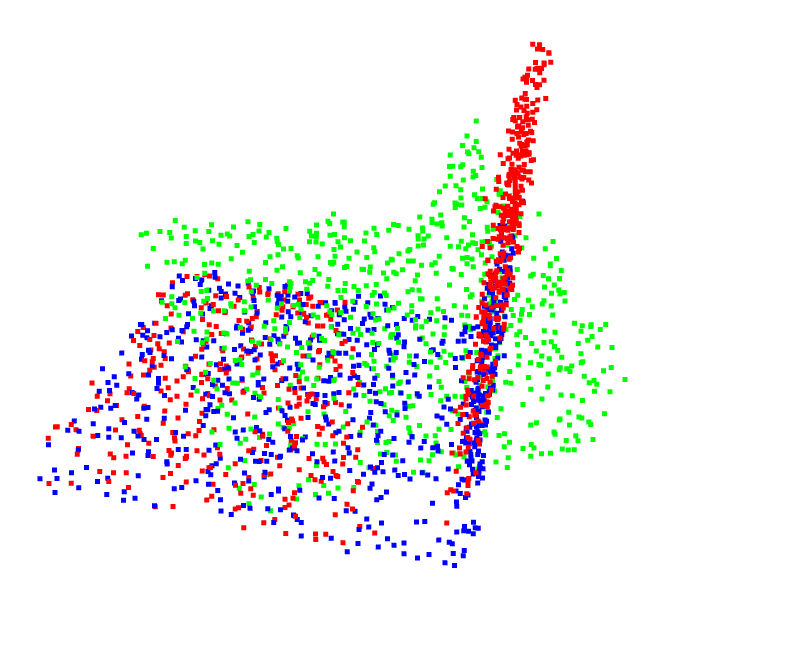
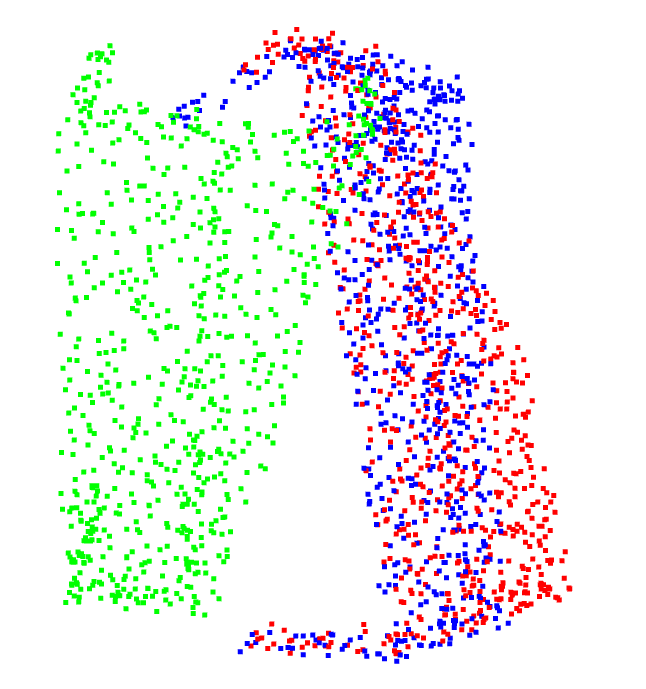
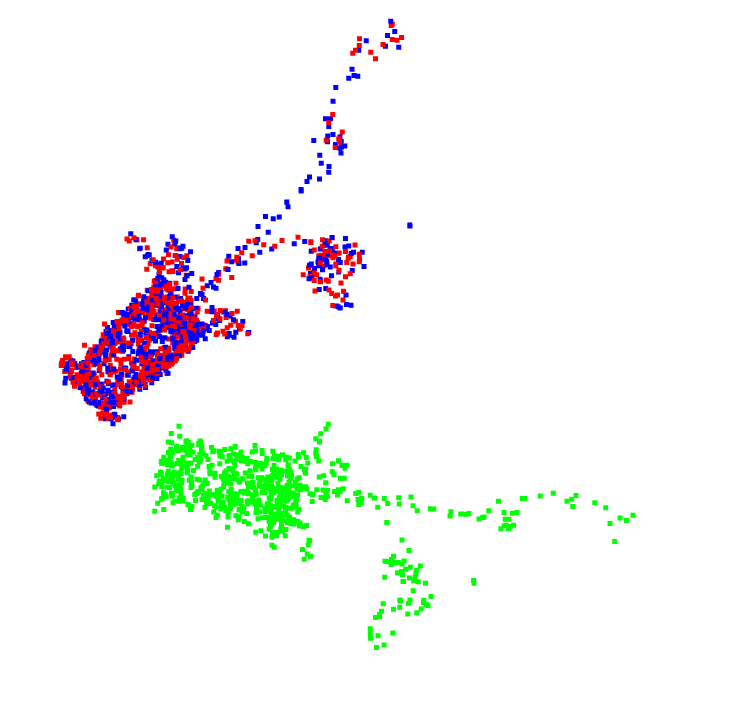
python vis.py --root modelnet40_ply_hdf5_2048/ --unseen --noise --checkpoint work_dirs/models/checkpoints/min_rot_error.pth
The specific registration effect is as follows, where the green point cloud is the input point cloud, the red point cloud is the reference point cloud, and the blue point cloud is the registered point cloud. It can be seen that the blue point cloud basically coincides with the red point cloud, and it can be determined that the registration effect is very complete.
3.4 Process your own data sets
Tutorials for training and processing your own data based on this project will be given later.