
I. Introduction
Garbage collection is an unavoidable topic for Javars, and the tuning work involved in work often revolves around the garbage collector. Facing different business scenarios, no unified garbage collector can guarantee GC performance. Therefore, programmers must not only be able to write business code, but also have knowledge of the underlying principles and tuning of the JVM. This situation may change with the emergence of ZGC. The new generation collector ZGC requires almost no tuning and the GC pause time can be reduced to sub-second level.
Oracle has officially introduced ZGC starting from JDK11. ZGC has three major goals:
- Supports TB-level memory (8M~4TB).
- The pause time is controlled within 10ms (the actual observation in the production environment is at the microsecond level), and the pause will not increase with the size of the heap or the size of active objects.
- The impact on program throughput is less than 15%.
How is ZGC designed to achieve this goal? This article will start with the key characteristics of the ZGC algorithm, understand these characteristics by analyzing the ZGC cycle processing process, and explore the ZGC design ideas.
2. ZGC terminology
Non-generational : The memory will be divided into the new generation and the old generation (G1 has been logically generational), ZGC cancels the generational design, and each GC cycle will mark all active objects in the entire heap.
Pages: ZGC breaks down the heap space into areas, which are called pages. ZGC uses pages to reclaim memory.
Concurrency: GC and threads and business threads run at the same time . ZGC's highly concurrent design, almost all GC work, marking and heap defragmentation are run simultaneously with business threads (mutators), including only a short STW synchronization pause.
Parallel: Multiple threads work on GC threads at the same time to speed up recycling.
Mark-copy algorithm: The mark-copy algorithm mainly includes the following three processes.
- The marking phase starts from the GC Roots collection, analyzes object reachability, and marks active objects.

图1:可达性分析后对象的引用状态
- The object transfer phase is to copy the active object to a new memory address.
- In the relocation phase, because the transfer causes the address of the object to change, during the relocation phase, all pointers pointing to the old address of the object must be adjusted to the new address of the object.
The biggest advantage of the mark-copy algorithm is to prevent the occurrence of heap memory fragmentation, and the heap memory can be organized during the copy process. ZGC, CMS and G1 all use mark-copy algorithms, but different implementations lead to great performance differences.
3. ZGC performance data
The ZGC design strives to provide a maximum pause time of a few milliseconds while ensuring that throughput is not affected. Below is the performance test data run by SPECjbb2015 against different collectors in OpenJDK. Under 128G heap memory, ZGC's performance is higher than other collectors in terms of latency and throughput.
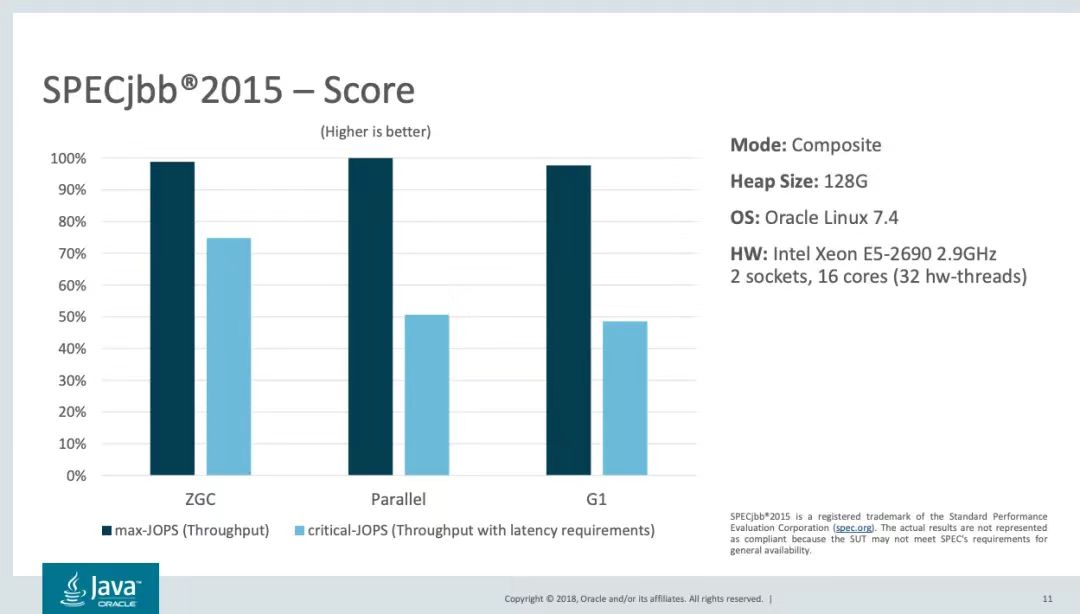
图2:SPECjbb2015GC性能评分
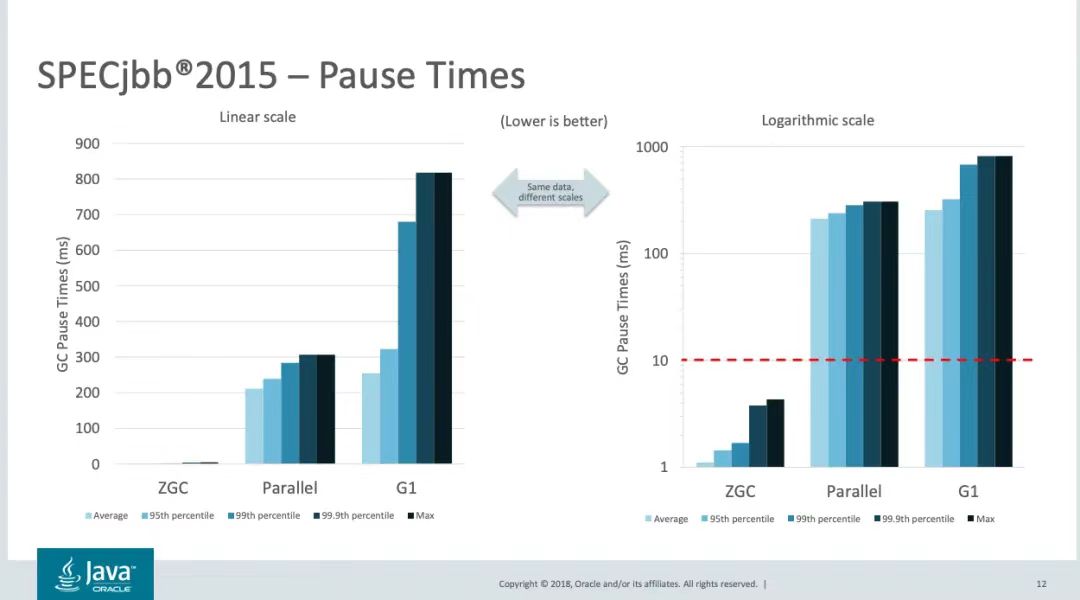
图3: SPECjbb2015GC延迟比较
4. Key features of ZGC
The cycle of ZGC is highly concurrent. The higher the concurrency, the smaller the impact on business threads when GC is working. The performance report of SPECjbb2015 can be seen that ZGC is more than 10 times lower than G1 in terms of latency. ZGC has only three working cycles. The stage is STW, and other stages are completely concurrent. This is due to ZGC's improvements in heap view concurrency and consistency design. We all know that in concurrent scenarios, we need to coordinate various threads to achieve consistency on shared resources. The common method is to lock resources. The idea under the garbage collector is similar. If the GC thread is working, it needs to lock the object resources for processing. , all business threads need to be suspended, which results in STW (Stop The Word). In the past, garbage collectors made the GC thread and the business thread agree on the address of the object in the heap. When the object is transferred, the business thread cannot access it (because the address of the object has changed), regardless of whether the G1 or CMS object is being copied. STW is always required. The Colored Pointer and Load Barrier technologies used by ZGC allow all threads to agree on the color (state) of the pointer under concurrent conditions, rather than the object address. Therefore, ZGC can copy objects concurrently, which greatly reduces GC pause time. We first have a preliminary understanding of colored pointers and read barriers, and then look at the specific application of these two technologies through the ZGC recycling cycle.
Colored Pointer
Embedding metadata in pointers (implemented using high-order bits in the address), this technology of storing metadata in pointers is called Colored Pointer. Pointers in ZGC are always 64-bit structures, consisting of meta bits (the color of the pointer) and address bits. The number of address bits determines the theoretically supported maximum heap size. ZGC uses a 42-bit storage address, which means that ZGC supports a maximum of 4TB heap memory. As shown in the figure, the lower 42 bits are address bits, the middle 4 bits are meta bits, and the upper 18 bits are unused. The four bits are Finalized (F), Remapped (R), Marked1 (M1) and Marked0 (M0).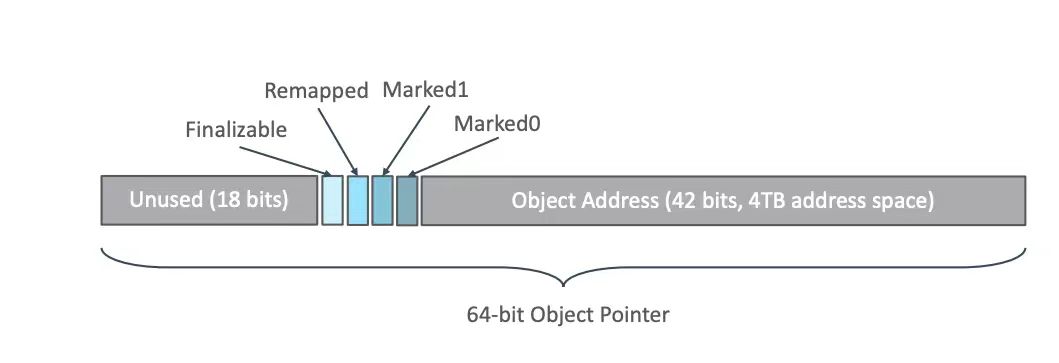
图4: 64位地址使用示意图
In ZGC, the designated mark is represented by a color, which can be "good" (the address is valid) or "bad" (the address may be invalid). The color of the pointer is determined by the state of its bits: F, R, M1 and M0. "Good" means that one of the R, M1, and M0 bits is set, and the other three are not set. For example, 0100, 0010, and 0001 belong to the "good" color. The object state can be distinguished by the color on the pointer without additional memory access, which makes ZGC faster in the marking and transfer phases.
By setting the state of the address bit, different address views can be formed. The same physical heap memory of ZGC is mapped to the virtual address space three times, resulting in three "views" of the same physical memory. There will be only one active view in different periods of GC activity. , ZGC marks the color of the object by switching different view marks according to the garbage collection cycle.
The following figure shows the space division of virtual addresses: 
图5:虚拟地址空间划分和多视图映射
[0~4TB) corresponds to Java heap;
[4TB ~ 8TB) is called M0 address space;
[8TB ~ 12TB) is called M1 address space;
[12TB ~ 16TB) reserved and unused;
[16TB ~ 20TB) is called Remapped space.
ZGC is not generational, which means that garbage collection needs to scan the entire heap space. The address view divides the entire Java heap into multiple parts and allocates a virtual memory segment for each part. During garbage collection, ZGC only needs to scan one of the virtual memory segments and map it to the actual memory location as the current view. At the same time, ZGC will map other virtual memory segments to virtual addresses, and these memory segments will not be scanned by the collector.
Load Barrier
ZGC differs significantly from previous GC (CMS, G1, etc.) algorithms in the HotSpot JVM by utilizing read barriers instead of write barriers. Read barriers solve the problem of object pointer updates during concurrent transfers: during a transfer, if an object is moved without updating the incoming pointer of the referenced object (the moved object may be referenced by any other object in the heap), a dangling pointer ( Memory space that has been released or invalid memory address will cause problems when accessing dangling pointers). Read barrier technology can capture such dangling pointer objects and trigger code to update the new location of the object, thereby "repairing" the dangling pointer. In order to track how objects move so that dangling pointers are fixed when loading, forwarding tables are used in ZGC to map pre-relocation (old) addresses to post-relocation (new) addresses. Whether the business thread accesses the object as a consumer, or the GC thread traverses all active objects in the heap (during marking), the read barrier may be triggered.
How to implement ZGC read barrier? For example, the code var x = obj.field. x is a local variable located on the stack, and field is a pointer located on the heap. Business threads trigger read barriers when operating heap objects. There are two execution paths of the read barrier: fast path and slow path. If the pointer being loaded is in a valid state (good color), the fast path of loading the barrier is used. Otherwise, the slow path is used. The fast path is effectively empty, while the slow path contains the logic to calculate a valid state pointer: check whether the object has been (or will be) relocated, and if so, find or generate a new address. In addition to allowing the thread that triggers the read barrier to read the latest address, the read barrier also has the function of self-healed pointers , which means that the read barrier will modify the state of the pointer so that subsequent access by other threads can execute quickly. path. Whichever path is taken, the address in the correct state is returned. The following pseudocode is used to represent the general logic of ZGC when executing read barriers:
/**
slot 是值线程栈中的局部变量,也就是屏障要操作的目标对象
*/
unintptr_t barrier(unintptr_t *slot,unintptr_t addr){
//快速路径,fast path
if(is_good_or_null(addr))return addr;
//慢速路径,slow path
good_addr = process(addr);
//自我修复
self_heal(slot,addr,good_addr);
return good_addr;
}
/*
自我修复,将指针恢复到正常状态
*/
void self_heal(unintptr_t *slot,unintptr_t old_addr,unintptr_t new_addr){
if(new_addr == 0)return;
while(true){
if(CAS(slot,&old_addr,new_addr)
return;
if(is_good_or_null(old_addr))
return;
}
}
ZGC's read barrier may be triggered by GC threads and business threads, and will only be triggered when accessing objects in the heap. It will not be triggered when the accessed object is located in GC Roots. This is why STW is required when scanning GC Roots.
Below is a simplified example code showing when the read barrier is triggered.
Object o = obj.FieldA // 从堆中读取引用,需要加入屏障
<Load barrier>
Object p = o // 无需加入屏障,因为不是从堆中读取引用
o.dosomething() // 无需加入屏障,因为不是从堆中读取引用
int i = obj.FieldB //无需加入屏障,因为不是对象引用
5. ZGC execution cycle
As shown in the figure below, the ZGC cycle consists of three STW pauses and four concurrency phases: mark/remap (M/R), concurrent reference processing (RP), concurrent transfer preparation (EC), and concurrent transfer (RE). In order for readers to understand quickly, the ZGC execution process has been greatly simplified below.
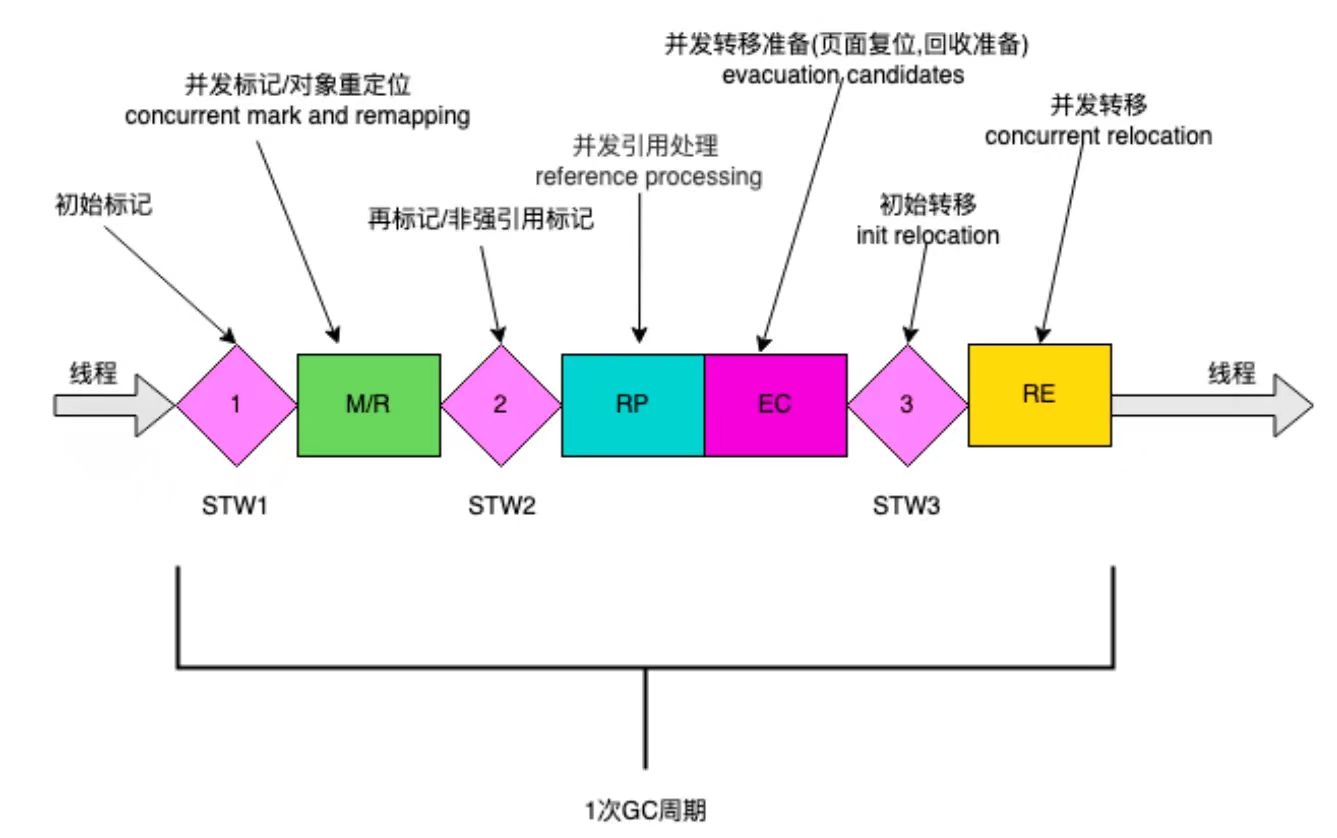
图6:ZGC周期表示
Initial mark (STW1)
The ZGC initial mark execution consists of three main tasks.
- The address view is set to M0 (or M1), M0 or M1 is set alternately according to the previous cycle.
- Reallocate new pages to business threads to create objects, and ZGC will only process pages allocated before the current cycle.
- Initial marking: Only the surviving root object is marked as M0 (M1) and added to the marking stack for concurrent marking.
Address view window during GC cycle
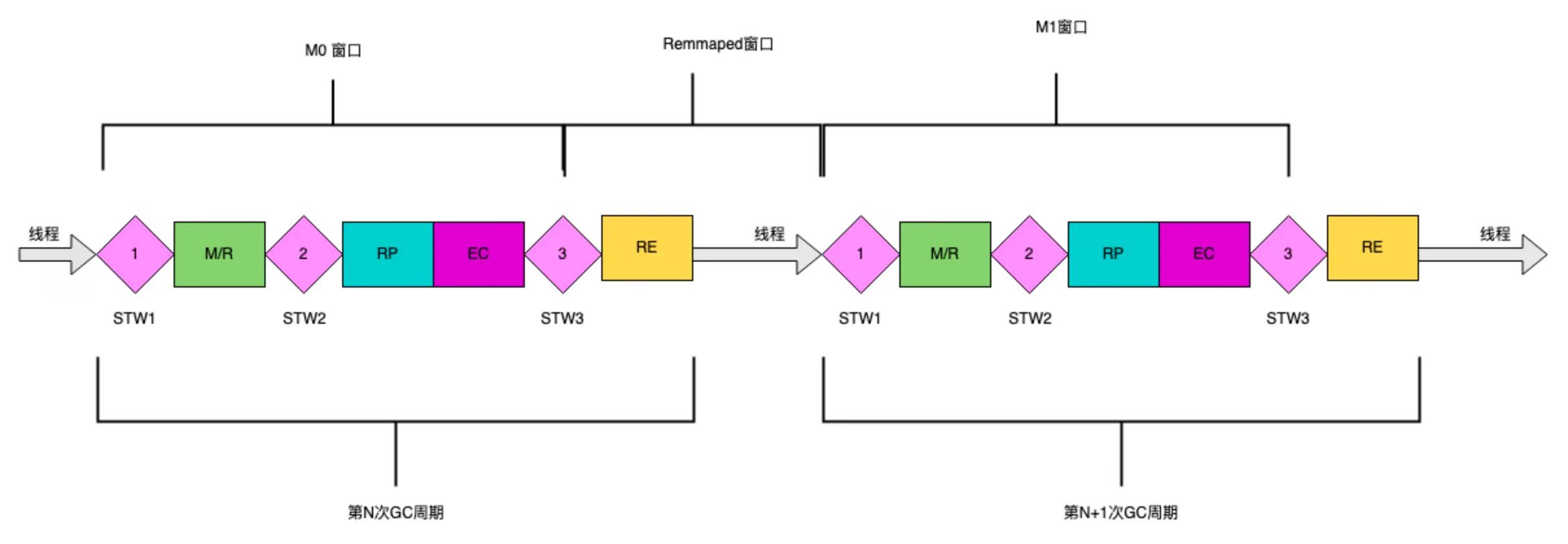
图7:ZGC周期中状态窗口划分
Concurrency Marking (M/R)
There are 2 concurrently marked tasks:
First, the concurrent marking thread starts from the object list to be marked, traverses the object's member variables according to the object reference relationship graph, and recursively marks.
Second, calculate and update the activity information of the associated page. Activity information is the number of active bytes on a page and is used to select pages that will be reclaimed and those objects will be relocated as part of heap defragmentation.
The following pseudocode is the main process of concurrent marking:
while(obj in mark_stack){
//标记存活对象,当且仅当该对象未被标记并且当前线程成功标记该对象时才返回true
success = mark_obj(obj);
if(success){
for(e in obj->ref_fields()){
MarkBarrier(slot_of_e,e);
}
}
}
//GC线程调用
//EC是待回收页面的集合
void MarkBarrier(uintptr_t *slot,unintptr_t addr){
if(is_null(addr))return;
//判断是否在待回收集合内
if(is_pointing_into(addr,EC)){
//地址重映射到当前GC视图
good_addr = remap(addr);
} else {
good_addr = good_color(addr);
}
//访问的对象添加到标记栈
mark_stack->add(good_addr);
self_heal(slot,addr,good_addr);
}
//读屏障前面有介绍过,由业务线程调用
void LoadBarrier(uintptr_t *slot,unintptr_t addr){
if(is_null(addr))return;
if(is_pointing_into(addr,EC)){
good_addr = remap(addr);
} else {
good_addr = good_color(addr);
}
mark_stack->add(good_addr);
self_heal(slot,addr,good_addr);
return good_addr;
}
The code snippet shows the GC thread main loop during the concurrent marking phase. mark_obj() returns true if and only if the object has not been marked and the current thread successfully marked the object. It uses atomic operations (compare and swap, CAS) internally to set bits in the bitmap, so it is thread-safe. MarkBarrier() traverses the member properties of the object and completes the marking of the object reference. The business thread is also running during concurrent marking. Previously, if the business thread accessed the object, LoadBarrier() would be executed to assist the GC thread in completing the object marking.
Remarking phase (STW2)
There are three main tasks in the re-labeling phase:
- Executing the repair task means that the thread runs the code compiled by C2, and missing marks may occur when entering the re-marking stage.
- End marking. After concurrent marking, there may be objects to be marked in the local marking stack of the business thread. The purpose of performing this step is to mark these objects to be marked.
- Perform partial non-strong root parallel marking.
Concurrent transfer preparation (EC)
Concurrent transfer preparation tasks:
- Filter all pages that can be recycled
- Select pages with a lot of garbage as the page transfer set
Initial transfer (STW3)
The initial transfer mainly involves the following processes:
- Adjust the address view: Adjust the address view from M0 or M1 to Remapped, which means entering the real transfer. After that, all allocated object views are Remapped.
- Relocate TLAB: Because the address view is adjusted, the view of the address in TLAB needs to be adjusted.
- Start transfer: starting from the root collection, traverse the objects directly referenced by the root object, and transfer these objects.
The initial transfer is STW, and its processing time is proportional to the number of GC Roots. Generally, it takes very little time.
Concurrent transfer (RE)
The initial transfer completes the relocation of the GC Roots object. In the concurrent transfer phase, the transfer set (EC) determined in the previous step will be transferred, and the transfer will be performed on each page of the transfer set.
The process of concurrent transfer can be abstracted into the following pseudo-code process:
//GC线程主循环遍历EC的页面,将个将EC集页面中对象进行转移
for (page in EC){
for(obj in page){
relocate(obj);
}
}
//该方法GC和业务线程都有可能执行,如果是业务线程访问对象会先进行转移在进行操作
unintptr_t relocate(unintptr_t obj) {
//获取对象的地址转发表
ft = forwarding_tables_get(obj);
if (ft->exist(obj)){
return ft->get(obj);
}
new_obj = copy(obj);
//CAS写对象转发表数据
if(ft->insert(obj,new_obj)){
return new_obj;
}
//CAS发生竞争,写转发表失败,释放分配的内存
dealloc(new_obj)
return ft->get(obj);
}
The function of the forwarding table is to store the mapping from the old address to the new address after the transfer. The data in the forwarding table is stored in the page, and the page after the transfer is completed can be recycled.
After the concurrent transfer is completed, the entire ZGC cycle is completed.
6. ZGC algorithm demonstration
To illustrate the ZGC algorithm, the figure below demonstrates all stages in the example.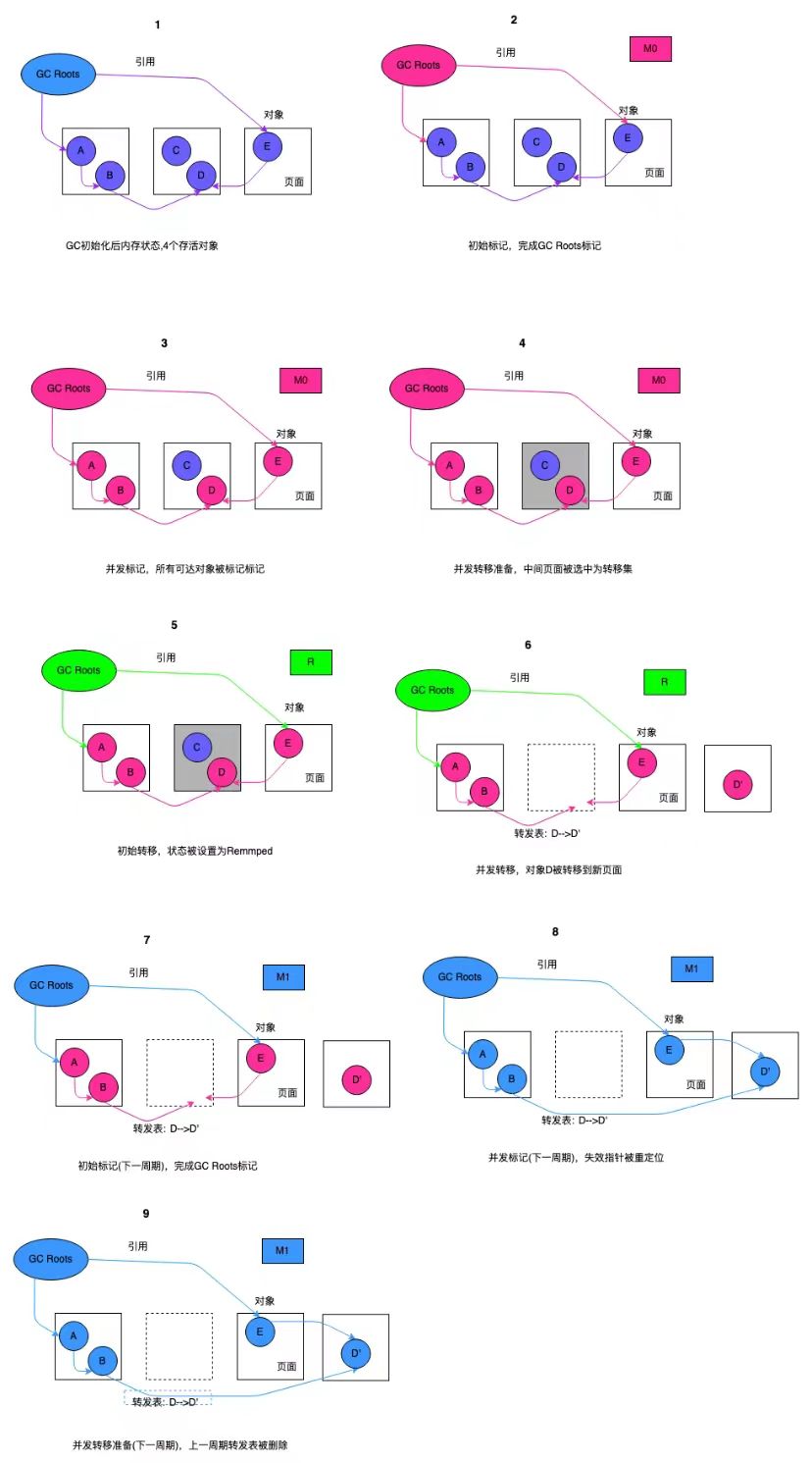
图8:ZGC算法演示
Figure 8(1) shows the initial state of the heap. ZGC has completed initialization after the application is started.
In Figure 8(2), M0 is selected as the global mark, and all root pointers are marked as M0. All roots are then pushed to the mark stack, which is consumed by the GC thread during concurrent mark (M/R).
As shown in Figure 8(3), the objects themselves are drawn with appropriate colors to indicate that they have been marked, even though the pointers have state.
In Figure 8(4), the page with the fewest surviving objects (the middle page) is selected as the transfer candidate set (EC).
Subsequently, in Figure 8(5), the global flag is set to Remmaped and all root pointers have been updated to Remmaped. If the root points to the EC, the corresponding object is relocated and the root pointer is updated to the new address.
In Figure 8(6), the object in the EC is transferred, and the address record is evicted from the forwarding table in the page for old and new address translation. When the concurrent transfer phase ends, the current GC cycle also ends. The entire EC will be recycled during the current cycle. There may be a question here. The old address of the object has not been updated. How can the object still be accessed if the page is recycled? The reason is that the object storage space in the page is recycled, and the forwarding table will not be recycled. If the business thread accesses these objects at this time, the slow path bit of the read barrier will be triggered, and the invalid pointer will be repaired. Invalid pointers that are not accessed will not be repaired until the next GC concurrent mark (M/R) phase.
In Figure 8(7), the next GC cycle starts and M1 is selected as the global state (alternating between M0 and M1).
In Figure 8(8), the concurrent marking phase (M/R) is mapped to a new location by querying the forwarding table for invalid indicators.
Finally, in Figure 8(9), the forwarding table of the EC page in the previous cycle is recycled to prepare for the upcoming concurrent transfer (RE) phase.
7. Summary
ZGC is a very complex JVM subsystem, and it is impossible to describe all the details in one article. This article discusses in detail the key technologies of ZGC's colored pointers and read barriers. They are also innovative points in ZGC. Finally, a simplified version of the ZGC algorithm process is demonstrated through an example. Through studying complex systems like ZGC, I also realized that when analyzing complex systems, there is no need to worry too much about implementation details at the beginning. You can start with the key processes and then go deeper.
The high concurrency design of ZGC contributes to its high performance, which is attributed to the use of colored pointers and read barriers. Of course, in addition to these two items, there are other exquisite designs such as: memory model, concurrency model, prediction algorithm, etc., which will not be discussed here. Readers You can refer to other articles. Understanding the basic principles of ZGC can help optimize the performance of applications and build knowledge for application tuning. Finally, ZGC has excellent performance and stability. We can give priority to using ZGC when selecting GC.
Reference content:
[1] Peng Chenghan: "Design and Implementation of a New Generation of Garbage Collector ZGC". Machinery Industry Press, 2019.
[2]https://tech.meituan.com/2020/08/06/new-zgc-practice-in-meituan.html
[3]https://www.baeldung.com/jvm-zgc-garbage-collector
[4]https://openjdk.org/projects/zgc/
[5]https://www.jfokus.se/jfokus18/preso/ZGC--Low-Latency-GC-for-OpenJDK.pdf
*Text/byteyangyang
This article is original to Dewu Technology. For more exciting articles, please see: Dewu Technology official website
Reprinting without the permission of Dewu Technology is strictly prohibited, otherwise legal liability will be pursued according to law!
Lei Jun: The official version of Xiaomi’s new operating system ThePaper OS has been packaged. A pop-up window on the Gome App lottery page insults its founder. The U.S. government restricts the export of NVIDIA H800 GPU to China. The Xiaomi ThePaper OS interface is exposed. A master used Scratch to rub the RISC-V simulator and it ran successfully. Linux kernel RustDesk remote desktop 1.2.3 released, enhanced Wayland support After unplugging the Logitech USB receiver, the Linux kernel crashed DHH sharp review of "packaging tools": the front end does not need to be built at all (No Build) JetBrains launches Writerside to create technical documentation Tools for Node.js 21 officially released