Preface
When using a crawler to crawl data, when the amount of data to be crawled is relatively large and the data is urgently needed to be obtained quickly, you can consider writing a single-threaded crawler into a multi-threaded crawler. Let’s learn some basic knowledge and coding methods.
1. Processes and threads
A process can be understood as an instance of a running program. A process is an independent unit that owns resources, but a thread is not an independent unit. Since the overhead of scheduling a process each time is relatively large, threads are introduced for this reason. A process can have multiple threads, and multiple threads can exist in a process at the same time. These threads share the resources of the process, and the cost of thread switching is very small. Therefore, the purpose of introducing processes into the operating system is to better enable the concurrent execution of multi-programs and improve resource utilization and system throughput; while the purpose of introducing threads is to reduce the time and space overhead incurred when programs are executed concurrently and improve Concurrency performance of the operating system.
A simple example is used to describe it below. Open the "Task Manager" of the local computer as shown in Figure 1. These running programs are called processes. If you compare a process to a job and assign 10 people to do the job, these 10 people are 10 threads. Therefore, within a certain range, multi-threading efficiency is higher than single-threading efficiency.
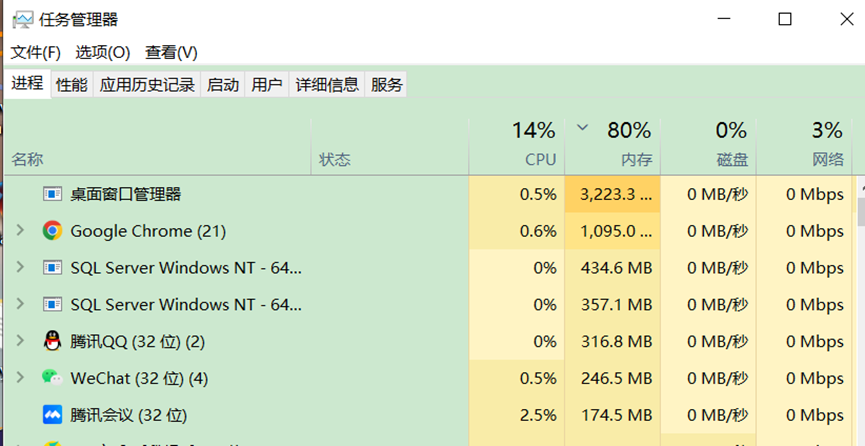
Figure 1. Task Manager
2. Multi-threading and single-threading in Python
In our daily learning process, we mainly use single-threaded crawlers. Generally speaking, if the resources to be crawled are not particularly large, a single thread can be used. In Python, it is single-threaded by default. A simple understanding is: the code is run in order, for example, the first line of code is run first, then the second line, and so on. The knowledge learned in the previous chapters was all practiced in the form of single thread.
For example, downloading pictures from a website in batches is a time-consuming operation. If you still use a single-threaded method to download, the efficiency will be very low, which means you need to spend more time waiting for downloading. In order to save time, we can consider using multi-threading to download images at this time.
The threading module is a module in Python specifically used for multi-thread programming. It encapsulates threads and makes it more convenient to use. For example, it is necessary to use multi-threading for two events: writing code and playing games. The case code is as follows.
import threading
import time
# 定义第一个
def coding():
for x in range(3):
print('%s正在写代码\n' % x)
time.sleep(1)
# 定义第二个
def playing():
for x in range(3):
print('%s正在玩游戏\n' % x)
time.sleep(1)
# 如果使用多线程执行
def multi_thread():
start = time.time()
# Thread创建第一个线程,target参数为函数命
t1 = threading.Thread(target=coding)
t1.start() # 启动线程
# 创建第二个线程
t2 = threading.Thread(target=playing)
t2.start()
# join是确保thread子线程执行完毕后才能执行下一个线程
t1.join()
t2.join()
end = time.time()
running_time = end - start
print('总共运行时间 : %.5f 秒' % running_time)
# 执行
if __name__ == '__main__':
multi_thread() # 执行单线程The running results are shown in Figure 2.

Figure 2. Multi-threaded running results
So how much time will it take to execute a single thread? The case code is as follows.
import time
# 定义第一个
def coding():
for x in range(3):
print('%s正在写代码\n' % x)
time.sleep(1)
# 定义第二个
def playing():
start = time.time()
for x in range(3):
print('%s正在玩游戏\n' % x)
time.sleep(1)
end = time.time()
running_time = end - start
print('总共运行时间 : %.5f 秒' % running_time)
def single_thread():
coding()
playing()
# 执行
if __name__ == '__main__':
single_thread() # 执行单线程The running results are shown in Figure 3.

Figure 3. Single-thread running results
After the above running results of multi-threading and single-threading, it can be seen that in multi-threading, writing code and playing games are executed at the same time, while in single-threading, writing code is done first and then playing games. In terms of time, there may be only a slight difference. When the workload is large, you will find that multi-threading consumes less time. From this case, we can also know that when there are not many tasks to be performed, Sometimes, you only need to write a single thread.
3. Change single thread to multi-thread
Taking the image crawling of a live broadcast as an example, the case code is as follows.
import requests
from lxml import etree
import time
import os
dirpath = '图片/'
if not os.path.exists(dirpath):
os.mkdir(dirpath) # 创建文件夹
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
def get_photo():
url = 'https://www.huya.com/g/4079/' # 目标网站
response = requests.get(url=url, headers=header) # 发送请求
data = etree.HTML(response.text) # 转化为html格式
return data
def jiexi():
data = get_photo()
image_url = data.xpath('//a//img//@data-original')
image_name = data.xpath('//a//img[@class="pic"]//@alt')
for ur, name in zip(image_url, image_name):
url = ur.replace('?imageview/4/0/w/338/h/190/blur/1', '')
title = name + '.jpg'
response = requests.get(url=url, headers=header) # 在此发送新的请求
with open(dirpath + title, 'wb') as f:
f.write(response.content)
print("下载成功" + name)
time.sleep(2)
if __name__ == '__main__':
jiexi()If you need to modify it to a multi-threaded crawler, you only need to modify the main function. For example, create 4 threads for crawling. The case code is as follows.
if __name__ == "__main__":
threads = []
start = time.time()
# 创建四个进程
for i in range(1, 5):
thread = threading.Thread(target=jiexi(), args=(i,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
end = time.time()
running_time = end - start
print('总共消耗时间 : %.5f 秒' % running_time)
print("全部完成!") # 主程序4. Book recommendations

This book introduces common techniques for Python3 web crawlers. First, it introduces the basic knowledge of web pages, then introduces urllib, Requests request library and parsing libraries such as XPath and Beautiful Soup. Then it introduces selenium's crawling of dynamic websites and Scrapy crawler framework. Finally, it introduces the basics of Linux to facilitate readers' independent deployment. Written crawler script.
This book is mainly intended for beginners who are interested in web crawlers.
Recommended by famous experts

about the author

Content structure and supporting resources
赠书
赠送规则:通过留言点赞以及抽奖的方式送出
1. 文末留言+分享朋友圈:通过留言点赞的方式送出三本!!留言点赞数量最多的小伙伴将各获得1本
附加规则:最近一个月中奖的本次不再送书,也给其他人一个中奖的机会!
开奖时间:8/17日 16点
注意事项:获赠者请在24小时以内添加本人微信,过期中奖无效