The last two blogs [yolov8 detects Rockchip RKNN C++ deployment] and [yolov8pose Rockchip RKNN chip, Horizon chip, TensorRT deployment] wrote about the C++ deployment of yolov8 detection and yolov8pose simulation deployment. Some netizens hope to open source the C++ code deployed on the board by yolov8pose. This article describes the C++ deployment of yolov8pose based on the rknn board. It is open source and provides complete code, models, and usage processes for netizens to test and verify by themselves.
Special note: If there is any infringement, let me know and delete it, thank you.
【Complete code】Code and model
1. rknn model preparation
The step of converting onnx to rknn model will not be described in detail. Please refer to the previous article "yolov8pose Rockchip RKNN chip, Horizon chip, TensorRT deployment" . The previous article provided a complete model and simulation code. If you just want to verify the model, you can directly use the provided rknn model for subsequent steps. This article is also based on the converted rknn model from the previous article and is deployed on the rk3588 chip. test.
2. C++ code preparation
The C++ code in this article is based on rknpu2_1.3.0 officially provided by Rockchip. Official open source example reference , extraction code: rknn.
3. C++ code description
For the model and image reading part, refer to the official example provided by rknn, which mainly explains the post-processing part. A yolov8pose post-processing class is defined to decode the model output. The decoding result is installed in a vector. The format of the installation is classId, score, xmin, ymin, xmax, ymax, classId, score, xmin, ymin, xmax, ymax. ... proceed, every six data are a detection frame, traverse the vector to get the detection frame; store the 17 key points in another vector in the order of each point (score, x, y), traverse the vector to get key point. Note: The number of detection frames corresponds to the order of the two vectors of the key points; don't ask why the structure is used inside the post-processing, and when it is passed out, the structure is not used but the vector is used. Each detection frame corresponds to 17 key points:
vector DetectiontRects;(classId,score,xmin,ymin,xmax,ymax, classId,score,xmin,ymin,xmax,ymax...)
vector DetectKeyPoints;(score, x, y,score, x, y,score, x, y …)
// 后处理部分
std::vector<float> out_scales;
std::vector<int32_t> out_zps;
for (int i = 0; i < io_num.n_output; ++i)
{
out_scales.push_back(output_attrs[i].scale);
out_zps.push_back(output_attrs[i].zp);
}
int8_t *pblob[9];
for (int i = 0; i < io_num.n_output; ++i)
{
pblob[i] = (int8_t *)outputs[i].buf;
}
// 将检测结果按照classId、score、xmin1、ymin1、xmax1、ymax1 的格式存放在vector<float>中
GetResultRectYolov8 PostProcess;
std::vector<float> DetectiontRects;
// 将17个关键点按照每个点(score, x, y)的顺序存入
std::vector<float> DetectKeyPoints;
PostProcess.GetConvDetectionResult(pblob, out_zps, out_scales, DetectiontRects, DetectKeyPoints);
int KeyPoinstNum = 17;
float pose_score = 0;
int pose_x = 0, pose_y = 0;
int NumIndex = 0, Temp = 0;
for (int i = 0; i < DetectiontRects.size(); i += 6)
{
int classId = int(DetectiontRects[i + 0]);
float conf = DetectiontRects[i + 1];
int xmin = int(DetectiontRects[i + 2] * float(img_width) + 0.5);
int ymin = int(DetectiontRects[i + 3] * float(img_height) + 0.5);
int xmax = int(DetectiontRects[i + 4] * float(img_width) + 0.5);
int ymax = int(DetectiontRects[i + 5] * float(img_height) + 0.5);
char text1[256];
sprintf(text1, "%d:%.2f", classId, conf);
rectangle(src_image, cv::Point(xmin, ymin), cv::Point(xmax, ymax), cv::Scalar(255, 0, 0), 2);
putText(src_image, text1, cv::Point(xmin, ymin + 15), cv::FONT_HERSHEY_SIMPLEX, 0.7, cv::Scalar(0, 0, 255), 2);
// 关键点
for (int k = NumIndex * KeyPoinstNum * 3; k < (NumIndex + 1)* KeyPoinstNum * 3 ; k += 3)
{
pose_score = DetectKeyPoints[k + 0];
if(pose_score > 0.5)
{
pose_x = int(DetectKeyPoints[k + 1] * float(img_width) + 0.5);
pose_y = int(DetectKeyPoints[k + 2] * float(img_height) + 0.5);
if(Temp < 5)
{
cv::circle(src_image, cv::Point(pose_x, pose_y), 2, cv::Scalar(0, 0, 255), 5);
}
else if(5 <= Temp && Temp < 12)
{
cv::circle(src_image, cv::Point(pose_x, pose_y), 2, cv::Scalar(0, 255, 0), 5);
}
else
{
cv::circle(src_image, cv::Point(pose_x, pose_y), 2, cv::Scalar(255, 0, 0), 5);
}
}
Temp += 1;
}
NumIndex += 1;
}
imwrite(save_image_path, src_image);
The core part of the post-processing code is as follows. The post-processing code is not necessarily optimal. If there is a better way to write it, please share it. For the complete code, please refer to the github repository, code and model corresponding to this example .
int GetResultRectYolov8::GetConvDetectionResult(int8_t **pBlob, std::vector<int> &qnt_zp, std::vector<float> &qnt_scale, std::vector<float> &DetectiontRects, std::vector<float> &DetectKeyPoints)
{
int ret = 0;
if (meshgrid.empty())
{
ret = GenerateMeshgrid();
}
int gridIndex = -2;
float xmin = 0, ymin = 0, xmax = 0, ymax = 0;
float cls_val = 0;
float cls_max = 0;
int cls_index = 0;
int quant_zp_cls = 0, quant_zp_reg = 0, quant_zp_pose = 0;
float quant_scale_cls = 0, quant_scale_reg = 0, quant_scale_pose = 0;
KeyPoint Point;
DetectRect temp;
std::vector<DetectRect> detectRects;
for (int index = 0; index < headNum; index++)
{
int8_t *reg = (int8_t *)pBlob[index * 2 + 0];
int8_t *cls = (int8_t *)pBlob[index * 2 + 1];
int8_t *pose = (int8_t *)pBlob[index + 6];
quant_zp_reg = qnt_zp[index * 2 + 0];
quant_zp_cls = qnt_zp[index * 2 + 1];
quant_zp_pose = qnt_zp[index + headNum * 2];
quant_scale_reg = qnt_scale[index * 2 + 0];
quant_scale_cls = qnt_scale[index * 2 + 1];
quant_scale_pose = qnt_scale[index + headNum * 2];
for (int h = 0; h < mapSize[index][0]; h++)
{
for (int w = 0; w < mapSize[index][1]; w++)
{
gridIndex += 2;
for (int cl = 0; cl < class_num; cl++)
{
cls_val = sigmoid(DeQnt2F32(cls[cl * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_cls, quant_scale_cls));
if(0 == cl)
{
cls_max = cls_val;
cls_index = cl;
}
else
{
if(cls_val > cls_max)
{
cls_max = cls_val;
cls_index = cl;
}
}
}
if (cls_val > objectThresh)
{
xmin = (meshgrid[gridIndex + 0] - DeQnt2F32(reg[0 * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_reg, quant_scale_reg)) * strides[index];
ymin = (meshgrid[gridIndex + 1] - DeQnt2F32(reg[1 * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_reg, quant_scale_reg)) * strides[index];
xmax = (meshgrid[gridIndex + 0] + DeQnt2F32(reg[2 * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_reg, quant_scale_reg)) * strides[index];
ymax = (meshgrid[gridIndex + 1] + DeQnt2F32(reg[3 * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_reg, quant_scale_reg)) * strides[index];
xmin = xmin > 0 ? xmin : 0;
ymin = ymin > 0 ? ymin : 0;
xmax = xmax < input_w ? xmax : input_w;
ymax = ymax < input_h ? ymax : input_h;
if (xmin >= 0 && ymin >= 0 && xmax <= input_w && ymax <= input_h)
{
temp.xmin = xmin / input_w;
temp.ymin = ymin / input_h;
temp.xmax = xmax / input_w;
temp.ymax = ymax / input_h;
temp.classId = cls_index;
temp.score = cls_val;
for(int kc = 0; kc < keypoint_num; kc ++)
{
Point.x = (DeQnt2F32(pose[(kc * 3 + 0) * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_pose, quant_scale_pose) * 2 + (meshgrid[gridIndex + 0] - 0.5)) * strides[index] / input_w;
Point.y = (DeQnt2F32(pose[(kc * 3 + 1) * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_pose, quant_scale_pose) * 2 + (meshgrid[gridIndex + 1] - 0.5)) * strides[index] / input_h;
Point.score = sigmoid(DeQnt2F32(pose[(kc * 3 + 2) * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_pose, quant_scale_pose));
temp.keyPoints.push_back(Point);
}
detectRects.push_back(temp);
}
}
}
}
}
std::sort(detectRects.begin(), detectRects.end(), [](DetectRect &Rect1, DetectRect &Rect2) -> bool
{
return (Rect1.score > Rect2.score); });
for (int i = 0; i < detectRects.size(); ++i)
{
float xmin1 = detectRects[i].xmin;
float ymin1 = detectRects[i].ymin;
float xmax1 = detectRects[i].xmax;
float ymax1 = detectRects[i].ymax;
int classId = detectRects[i].classId;
float score = detectRects[i].score;
if (classId != -1)
{
// 将检测结果按照classId、score、xmin1、ymin1、xmax1、ymax1的格式存放在vector<float>中
DetectiontRects.push_back(float(classId));
DetectiontRects.push_back(float(score));
DetectiontRects.push_back(float(xmin1));
DetectiontRects.push_back(float(ymin1));
DetectiontRects.push_back(float(xmax1));
DetectiontRects.push_back(float(ymax1));
// 每个检测框对应的17个关键点按照(score, x, y)格式存在vector<float>中
for(int kn = 0; kn < keypoint_num; kn ++)
{
DetectKeyPoints.push_back(float(detectRects[i].keyPoints[kn].score));
DetectKeyPoints.push_back(float(detectRects[i].keyPoints[kn].x));
DetectKeyPoints.push_back(float(detectRects[i].keyPoints[kn].y));
}
for (int j = i + 1; j < detectRects.size(); ++j)
{
float xmin2 = detectRects[j].xmin;
float ymin2 = detectRects[j].ymin;
float xmax2 = detectRects[j].xmax;
float ymax2 = detectRects[j].ymax;
float iou = IOU(xmin1, ymin1, xmax1, ymax1, xmin2, ymin2, xmax2, ymax2);
if (iou > nmsThresh)
{
detectRects[j].classId = -1;
}
}
}
}
return ret;
}
4. Compile and run
1) Compile
cd examples/rknn_yolov8pose_demo_open
bash build-linux_RK3588.sh
2) Run
cd install/rknn_yolov8pose_demo_Linux
./rknn_yolov8pose_demo
Note: Modify the path of the model, test image, and save the image. The file is the main.cc file under src.
5. Board-end reasoning effect
The number before the colon ":" is the category corresponding to Coco's 80 categories, and the floating point number after it is the target score. (Category: Score)
onnx effect

board end inference effect

Note: The inference test preprocessing does not consider equal ratio scaling, and the activation function SiLU is replaced with Relu. Since not much data is used, the effect is not very good and is only used for testing the process.
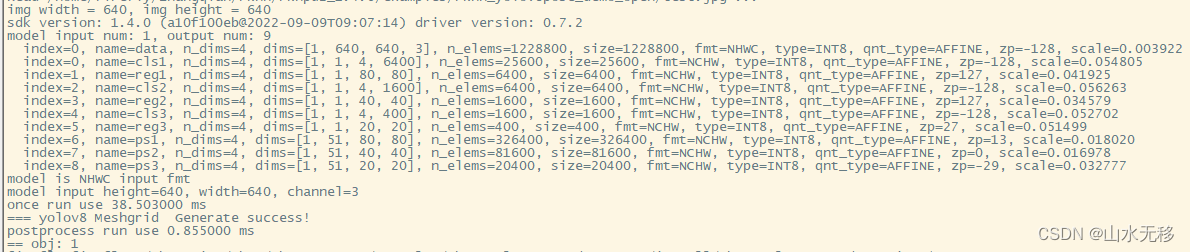
6. Model and post-processing time consumption
The model and post-processing time consumption are posted for your reference. The chip rk3588 is used and the input resolution is 640x640.