Foreword: Under the Spring Boot framework, you can use the following method to deduplicate 4 billion QQ numbers. Please note: The theoretical maximum value of QQ numbers is 2 32 − 1 2^{32} - 1232−1 , which is about 4.3 billion.
Article directory
Summary in advance (total score~~~)
- If it is limited to 1GB of memory and does not rely on external storage or middleware,
HashSetneitherJava 8 Streamwill be able to meet the requirements. - File sharding and external sorting algorithms can accommodate the 1GB memory limit, but involve additional file operations and sorting steps.
- Using the database's deduplication capabilities may require additional storage overhead.
- Redis as middleware can meet memory constraints, but it needs to rely on the Redis service.
- Bloom filter is an efficient data structure suitable for large-scale data deduplication, which can perform memory estimation based on the expected number of insertions and false positive rate.
the rudest way
1. Use HashSet to remove duplicates:
Set<String> qqSet = new HashSet<>();
// 假设qqList是包含40亿个QQ号的列表
for (String qq : qqList) {
qqSet.add(qq);
}
List<String> distinctQQList = new ArrayList<>(qqSet);
2. Use Java 8’s Stream to deduplicate:
List<String> distinctQQList = qqList.stream()
.distinct()
.collect(Collectors.toList());
3. Use the deduplication function of the database:
- First, create a database table to store QQ numbers. You can use MySQL or other relational databases.
- Insert 4 billion QQ numbers into the database table one by one, and the database will automatically remove duplicates.
- Finally, read the deduplicated QQ number list from the database:
// 假设使用Spring Data JPA进行数据库操作
@Repository
public interface QQRepository extends JpaRepository<QQEntity, Long> {
List<QQEntity> findAll();
}
// 在业务逻辑中使用QQRepository获取去重后的QQ号列表
List<QQEntity> distinctQQList = qqRepository.findAll();
Limit 1GB memory, file method
4. File fragmentation
- Divide 4 billion QQ numbers into multiple smaller segments, and each segment can contain a certain number of QQ numbers.
- For each segment, use HashSet for deduplication, but only retain the deduplication results of some segments in memory, not all.
- Write the deduplication results of each segment to a disk file to free up memory space.
- Deduplicate the next segment and repeat the above steps until all segments have been processed.
- Finally, the deduplication results in all disk files are merged into the final deduplication result.
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.*;
public class QQDuplicateRemover {
private static final int MAX_MEMORY_USAGE_MB = 1024; // 最大内存使用限制,单位:MB
private static final int MAX_SEGMENT_SIZE = 1000000; // 每个分段的最大数量
public static void main(String[] args) {
// 假设qqList是包含40亿个QQ号的列表
List<String> qqList = loadQQList();
// 分段处理
int segmentCount = (int) Math.ceil((double) qqList.size() / MAX_SEGMENT_SIZE);
List<File> segmentFiles = new ArrayList<>();
for (int i = 0; i < segmentCount; i++) {
List<String> segment = qqList.subList(i * MAX_SEGMENT_SIZE, Math.min((i + 1) * MAX_SEGMENT_SIZE, qqList.size()));
Set<String> segmentSet = new HashSet<>(segment);
segment.clear(); // 释放内存
File segmentFile = writeSegmentToFile(segmentSet);
segmentFiles.add(segmentFile);
segmentSet.clear();
}
// 合并去重结果
List<String> distinctQQList = mergeSegments(segmentFiles);
// 输出去重后的QQ号列表
for (String qq : distinctQQList) {
System.out.println(qq);
}
}
// 加载40亿个QQ号列表的示例方法
private static List<String> loadQQList() {
// TODO: 实现加载40亿个QQ号列表的逻辑,返回List<String>
return new ArrayList<>();
}
// 将分段的去重结果写入磁盘文件
private static File writeSegmentToFile(Set<String> segmentSet) {
File segmentFile;
BufferedWriter writer = null;
try {
segmentFile = File.createTempFile("qq_segment_", ".txt");
writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(segmentFile), StandardCharsets.UTF_8));
for (String qq : segmentSet) {
writer.write(qq);
writer.newLine();
}
} catch (IOException e) {
throw new RuntimeException("Failed to write segment to file.", e);
} finally {
if (writer != null) {
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return segmentFile;
}
// 合并分段文件并去重
private static List<String> mergeSegments(List<File> segmentFiles) {
List<String> distinctQQList = new ArrayList<>();
PriorityQueue<BufferedReader> fileReaders = new PriorityQueue<>(Comparator.comparing(QQDuplicateRemover::readNextLine));
for (File segmentFile : segmentFiles) {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(segmentFile), StandardCharsets.UTF_8));
String line = reader.readLine();
if (line != null) {
fileReaders.offer(reader);
}
} catch (IOException e) {
throw new RuntimeException("Failed to read segment file: " + segmentFile.getName(), e);
}
}
String currentQQ = null;
while (!fileReaders.isEmpty()) {
BufferedReader reader = fileReaders.poll();
String qq = readNextLine(reader);
if (!qq.equals(currentQQ)) {
distinctQQList.add(qq);
currentQQ = qq;
}
String nextQQ = readNextLine(reader);
if (nextQQ != null) {
fileReaders.offer(reader);
} else {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return distinctQQList;
}
// 读取下一行数据
private static String readNextLine(BufferedReader reader) {
try {
return reader.readLine();
} catch (IOException e) {
throw new RuntimeException("Failed to read line from segment file.", e);
}
}
}
In this sample code, the idea of segmented processing is used. First, divide the 4 billion QQ numbers into smaller segments and use HashSet for deduplication. Then, the deduplication results for each segment are written to a temporary file to free up memory. Finally, all segmented files are merged and deduplicated to obtain the final deduplication result.
Please note that the loadQQList() method in the sample code is a placeholder method and needs to be implemented according to the actual situation. In addition, a temporary file is used in this sample code to store the segmented deduplication results. In actual applications, you may need to make appropriate modifications according to your needs, such as specifying the output file path, handling exceptions, etc. In addition, since the memory limit is 1GB, you may need to adjust the size of MAX_SEGMENT_SIZE according to the actual situation to ensure that the size of each segment in memory does not exceed the limit.
This is just a basic sample code for your reference and understanding of the idea of segmented processing. Depending on actual needs and specific circumstances, you may need to make more optimizations and improvements.
5. External sorting algorithm
- Divide 4 billion QQ numbers into multiple small files, each file containing a part of the QQ number.
- To perform internal sorting on each small file, you can use algorithms such as merge sort.
- After merging the sorted small files, use the idea of merging and sorting to gradually merge the files and remove duplicate QQ numbers.
- Finally, the result after deduplication is obtained.
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.*;
public class QQDuplicateRemover {
private static final int MAX_MEMORY_USAGE_MB = 1024; // 最大内存使用限制,单位:MB
private static final int MAX_SEGMENT_SIZE = 1000000; // 每个分段的最大数量
public static void main(String[] args) {
// 假设qqList是包含40亿个QQ号的列表
List<String> qqList = loadQQList();
// 外部排序去重
List<File> sortedSegmentFiles = externalSort(qqList);
// 合并去重结果
List<String> distinctQQList = mergeSortedSegments(sortedSegmentFiles);
// 输出去重后的QQ号列表
for (String qq : distinctQQList) {
System.out.println(qq);
}
}
// 加载40亿个QQ号列表的示例方法
private static List<String> loadQQList() {
// TODO: 实现加载40亿个QQ号列表的逻辑,返回List<String>
return new ArrayList<>();
}
// 外部排序算法
private static List<File> externalSort(List<String> qqList) {
List<File> segmentFiles = new ArrayList<>();
int segmentCount = (int) Math.ceil((double) qqList.size() / MAX_SEGMENT_SIZE);
// 将数据分段并排序
for (int i = 0; i < segmentCount; i++) {
List<String> segment = qqList.subList(i * MAX_SEGMENT_SIZE, Math.min((i + 1) * MAX_SEGMENT_SIZE, qqList.size()));
Collections.sort(segment);
File segmentFile = writeSegmentToFile(segment);
segmentFiles.add(segmentFile);
}
// 逐步合并排序后的分段文件
while (segmentFiles.size() > 1) {
List<File> mergedSegmentFiles = new ArrayList<>();
for (int i = 0; i < segmentFiles.size(); i += 2) {
File segmentFile1 = segmentFiles.get(i);
File segmentFile2 = (i + 1 < segmentFiles.size()) ? segmentFiles.get(i + 1) : null;
File mergedSegmentFile = mergeSegments(segmentFile1, segmentFile2);
mergedSegmentFiles.add(mergedSegmentFile);
}
segmentFiles = mergedSegmentFiles;
}
return segmentFiles;
}
// 将分段数据写入临时文件
private static File writeSegmentToFile(List<String> segment) {
File segmentFile;
BufferedWriter writer = null;
try {
segmentFile = File.createTempFile("qq_segment_", ".txt");
writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(segmentFile), StandardCharsets.UTF_8));
for (String qq : segment) {
writer.write(qq);
writer.newLine();
}
} catch (IOException e) {
throw new RuntimeException("Failed to write segment to file.", e);
} finally {
if (writer != null) {
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return segmentFile;
}
// 合并两个分段文件
private static File mergeSegments(File segmentFile1, File segmentFile2) {
BufferedReader reader1 = null;
BufferedReader reader2 = null;
BufferedWriter writer = null;
File mergedSegmentFile;
try {
mergedSegmentFile = File.createTempFile("qq_segment_", ".txt");
reader1 = new BufferedReader(new InputStreamReader(new FileInputStream(segmentFile1), StandardCharsets.UTF_8));
reader2 = new BufferedReader(new InputStreamReader(new FileInputStream(segmentFile2), StandardCharsets.UTF_8));
writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(mergedSegmentFile), StandardCharsets.UTF_8));
String qq1 = reader1.readLine();
String qq2 = reader2.readLine();
while (qq1 != null && qq2 != null) {
if (qq1.compareTo(qq2) < 0) {
writer.write(qq1);
writer.newLine();
qq1 = reader1.readLine();
} else if (qq1.compareTo(qq2) > 0) {
writer.write(qq2);
writer.newLine();
qq2 = reader2.readLine();
} else {
writer.write(qq1);
writer.newLine();
qq1 = reader1.readLine();
qq2 = reader2.readLine();
}
}
// 处理文件剩余的数据
while (qq1 != null) {
writer.write(qq1);
writer.newLine();
qq1 = reader1.readLine();
}
while (qq2 != null) {
writer.write(qq2);
writer.newLine();
qq2 = reader2.readLine();
}
} catch (IOException e) {
throw new RuntimeException("Failed to merge segment files.", e);
} finally {
try {
if (reader1 != null) {
reader1.close();
}
if (reader2 != null) {
reader2.close();
}
if (writer != null) {
writer.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return mergedSegmentFile;
}
// 合并排序后的分段文件并去重
private static List<String> mergeSortedSegments(List<File> segmentFiles) {
List<String> distinctQQList = new ArrayList<>();
PriorityQueue<BufferedReader> fileReaders = new PriorityQueue<>(Comparator.comparing(QQDuplicateRemover::readNextLine));
for (File segmentFile : segmentFiles) {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(segmentFile), StandardCharsets.UTF_8));
String line = reader.readLine();
if (line != null) {
fileReaders.offer(reader);
}
} catch (IOException e) {
throw new RuntimeException("Failed to read segment file: " + segmentFile.getName(), e);
}
}
String currentQQ = null;
while (!fileReaders.isEmpty()) {
BufferedReader reader = fileReaders.poll();
String qq = readNextLine(reader);
if (!qq.equals(currentQQ)) {
distinctQQList.add(qq);
currentQQ = qq;
}
String nextQQ = readNextLine(reader);
if (nextQQ != null) {
fileReaders.offer(reader);
} else {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return distinctQQList;
}
// 读取下一行数据
private static String readNextLine(BufferedReader reader) {
try {
return reader.readLine();
} catch (IOException e) {
throw new RuntimeException("Failed to read line from segment file.", e);
}
}
}
This sample code uses an external sorting algorithm to handle the deduplication problem of 4 billion QQ numbers. First, the data is segmented and each segment is sorted in memory. Then, gradually merge the sorted segmented files until only one file remains. Finally, the merged segmented files are deduplicated to obtain the final deduplication result.
Please note that the loadQQList() method in the sample code is a placeholder method and needs to be implemented according to the actual situation. In addition, a temporary file is used in this sample code to store the segmented and merged results. In actual applications, you may need to make appropriate modifications according to your needs, such as specifying the output file path, handling exceptions, etc. In addition, since the memory limit is 1GB, you may need to adjust the size of MAX_SEGMENT_SIZE according to the actual situation to ensure that the size of each segment in memory does not exceed the limit.
This is just a basic sample code for you to refer to and understand the implementation of external sorting algorithms. Depending on actual needs and specific circumstances, you may need to make more optimizations and improvements.
Use middleware redis
6. bitmap
Redis bitmap (Bitmap) is a special data structure used to handle bit-level operations. You can use Redis bitmaps to solve deduplication problems, including deduplication of large-scale data.
The following are the general steps to solve the deduplication problem using Redis bitmaps:
-
Convert the data that needs to be deduplicated into a unique identifier, such as converting the QQ number into the corresponding integer or string.
-
Use Redis's bitmap data structure to create a bitmap key to store deduplication markers. You can use Redis's SETBIT command to set a specific bit in the bitmap to 1, indicating that the identifier already exists.
-
Traverse the data set, and for each unique identifier, use the SETBIT command to set the corresponding bit in the bitmap. If this bit has been set to 1, it means that the identifier already exists and corresponding processing can be performed (such as discarding or recording duplicate data).
-
After completing the traversal, you can use other commands of the bitmap (such as BITCOUNT) to obtain the number after deduplication, or use the GETBIT command to check whether a specific bit is set to determine whether a certain identifier exists.
Here is an example code for using Redis bitmaps for deduplication (using the Java Redis client Jedis):
import redis.clients.jedis.Jedis;
public class RedisBitmapDuplicateRemover {
private static final String BITMAP_KEY = "duplicate_bitmap";
public static void main(String[] args) {
// 假设qqList是包含40亿个QQ号的列表
List<String> qqList = loadQQList();
// 初始化Redis连接
Jedis jedis = new Jedis("localhost");
// 去重计数器
int duplicateCount = 0;
// 遍历qqList进行去重
for (String qq : qqList) {
long bit = Long.parseLong(qq); // 假设QQ号被转换为长整型
// 检查位图中的对应位是否已经被设置
boolean isDuplicate = jedis.getbit(BITMAP_KEY, bit);
if (isDuplicate) {
// 处理重复数据
duplicateCount++;
} else {
// 设置位图中的对应位为1,表示标识已经存在
jedis.setbit(BITMAP_KEY, bit, true);
// 处理非重复数据
}
}
// 获取去重后的数量
long distinctCount = jedis.bitcount(BITMAP_KEY);
System.out.println("Duplicate count: " + duplicateCount);
System.out.println("Distinct count: " + distinctCount);
// 关闭Redis连接
jedis.close();
}
// 加载40亿个QQ号列表的示例方法
private static List<String> loadQQList() {
// TODO: 实现加载40亿个QQ号列表的逻辑,返回List<String>
return new ArrayList<>();
}
}
In this example, we first convert the QQ number into a long integer and use a Redis bitmap to store the deduplication mark. Then traverse the QQ number list. For each QQ number, we use the GETBIT command to check whether the corresponding bit in the bitmap has been set. If it has been set, it means that the QQ number is duplicated and we can handle it accordingly. If the corresponding bit in the bitmap is not set, it means that the QQ number appears for the first time. We use the SETBIT command to set the corresponding bit in the bitmap to 1, indicating that the identifier already exists.
Finally, we use the BITCOUNT command to get the number of bits set to 1 in the bitmap, that is, the number after deduplication. At the same time, we can also use other bitmap commands to perform more operations, such as using the GETBIT command to check whether a specific bit is set.
Please note that the loadQQList() method in the sample code is still a placeholder method and needs to be implemented according to the actual situation. Additionally, you need to make sure you have Redis installed and the Redis connection configured correctly.
In summary, with the help of Redis bitmaps, you can effectively solve the problem of deduplication of large-scale data.
7. Bloom filter
Bloom Filters can be used to efficiently perform fast lookup and deduplication operations without storing the actual data. Here are the general steps for deduplication using Bloom filters:
Initialize the Bloom filter: Determine the size of the Bloom filter (number of bits) and the number of hash functions.
Convert the data that needs to be deduplicated into a unique identifier, such as converting the QQ number into the corresponding integer or string.
For each unique identifier, multiple different hash functions are used for hash calculation to obtain multiple hash values.
Set the corresponding bits of the multiple hash values obtained to 1, indicating that the identifier already exists.
When it is necessary to determine whether a certain identifier exists, use the same hash function to perform hash calculation on the identifier, and check whether the corresponding bits are all 1. If any bit is 0, the identifier does not exist; if all bits are 1, the identifier may exist (there is a certain false positive rate).
The following is a sample code that uses Bloom filters to implement deduplication (using the Java Bloom Filter library Guava):
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterDuplicateRemover {
private static final int EXPECTED_INSERTIONS = 1000000; // 预期插入数量
private static final double FPP = 0.01; // 期望误判率
public static void main(String[] args) {
// 初始化布隆过滤器
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(
Funnels.stringFunnel(), EXPECTED_INSERTIONS, FPP);
// 假设qqList是包含大量QQ号的列表
List<String> qqList = loadQQList();
// 去重计数器
int duplicateCount = 0;
// 遍历qqList进行去重
for (String qq : qqList) {
if (bloomFilter.mightContain(qq)) {
// 处理重复数据
duplicateCount++;
} else {
bloomFilter.put(qq);
// 处理非重复数据
}
}
// 获取去重后的数量
long distinctCount = qqList.size() - duplicateCount;
System.out.println("Duplicate count: " + duplicateCount);
System.out.println("Distinct count: " + distinctCount);
}
// 加载大量QQ号列表的示例方法
private static List<String> loadQQList() {
// TODO: 实现加载大量QQ号列表的逻辑,返回List<String>
return new ArrayList<>();
}
}
In this example, we use the Bloom Filter in the Guava library to implement the deduplication function. First, we initialize the bloom filter bloomFilter, specifying the expected number of insertions and the expected false positive rate. Then, traverse the QQ number list qqList. For each QQ number, we first use the mightContain() method to determine whether the QQ number may already exist in the Bloom filter. If true is returned, it means that the QQ number may already exist and we can handle it accordingly. If false is returned, it means that the QQ number probably does not exist. We use the put() method to insert it into the Bloom filter and process it accordingly.
Finally, we can get the deduplicated number by counting the number of duplicates and subtracting the number of duplicates from the total number of lists.
Please note that the loadQQList() method in the sample code is still a placeholder method and needs to be implemented according to the actual situation. Additionally, you need to ensure that the Guava library has been included and the dependencies configured correctly.
In summary, the Bloom filter is an efficient deduplication data structure and is suitable for deduplication operations on large-scale data. However, Bloom filters have a certain false positive rate, so in scenarios that require high accuracy, additional verification methods may be needed to confirm the existence of data.
Analyze the memory required by Bloom filter and bitmap to store 4 billion QQ numbers
Bloom filters and bitmaps are common data structures used to store and query large amounts of data efficiently. Below I will analyze the memory required by Bloom filters and bitmaps to store 4 billion QQ numbers.
Bloom filter:
To estimate the exact amount of memory a bloom filter requires, there are several factors to consider:
-
Expected Insertions: This refers to the number of elements expected to be inserted into the Bloom filter.
-
Expected false positive rate (False Positive Probability): This refers to the probability of judgment error allowed by the Bloom filter, that is, the probability of misjudgment of a non-existent element as existing.
-
Number of hash functions (Hash Functions Count): Bloom filters use multiple hash functions to map input elements to multiple positions in the bit array, which helps reduce the false positive rate.
The memory footprint of a Bloom filter can be approximated by the following formula:
M = − ( N ∗ ln ( p ) ) / ( ln ( 2 ) 2 ) M = -(N * ln(p)) / (ln(2)^2)M=−(N∗l n ( p )) / ( l n ( 2 )2)
Where, M is the number of bits required (memory footprint), N is the expected number of insertions, and p is the expected false positive rate.
Note that this formula only provides an approximation and assumes that the output of the hash function is uniformly distributed. In fact, the performance and memory usage of Bloom filters are also related to factors such as the choice of hash function and the mutual independence between hash functions.
For example, assuming we want to store 4 billion QQ numbers in a Bloom filter and expect a false positive rate of 0.01% (0.0001), we can substitute these values into the formula for estimation:
M = (4 billion* ln (0.0001) ) / ( ln ( 2 ) 2 ) M = (4 billion* ln(0.0001)) / (ln(2)^2)M=( 4 billion∗l n ( 0.0001 )) / ( l n ( 2 )2)
B y t e s = c e i l ( M / 8 ) Bytes = ceil(M / 8) Bytes=ceil(M/8)
According to the calculation results, the Bloom filter requires approximately 596.05MB of memory.
Please note that this is only an estimate and actual memory usage may vary. At the same time, in order to avoid an excessively high false positive rate, more hash functions may need to be used, thereby increasing memory usage.
Therefore, the specific memory usage needs to be adjusted and tested based on actual needs and misjudgment rate requirements.
Bitmap:
Bitmap memory analysis comes from Tencent Three Sides: How to remove duplication from 4 billion QQ numbers?
A bitmap is a data structure that uses bits to represent the presence or absence of data. For the 4 billion QQ numbers, each QQ number can be represented by a unique integer or hash value.
If we use a 32-bit integer to represent each QQ number, then each integer needs to occupy 32 bits. Therefore, the memory required to store 4 billion QQ numbers is:
Let’s see the trick! We can optimize hashmap and use bitmap data structure to successfully solve time and space problems at the same time.
In many practical projects, bitmap is often used. I looked at the source code of many components and found that bitmap is implemented in many places. The bitmap diagram is as follows:
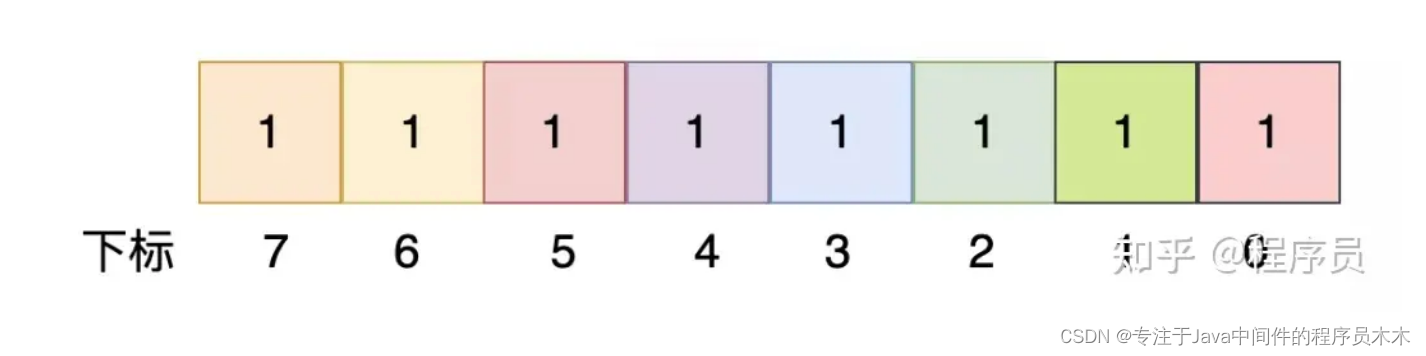
This is an unsigned char type. As you can see, there are 8 bits in total, and the value range is [0, 255]. As shown above, the value of the unsigned char is 255, which can identify the existence of numbers 0 to 7.
In the same way, the value of the unsigned char type below is 254, and its corresponding meaning is: the numbers 1 to 7 exist, but the number 0 does not exist:
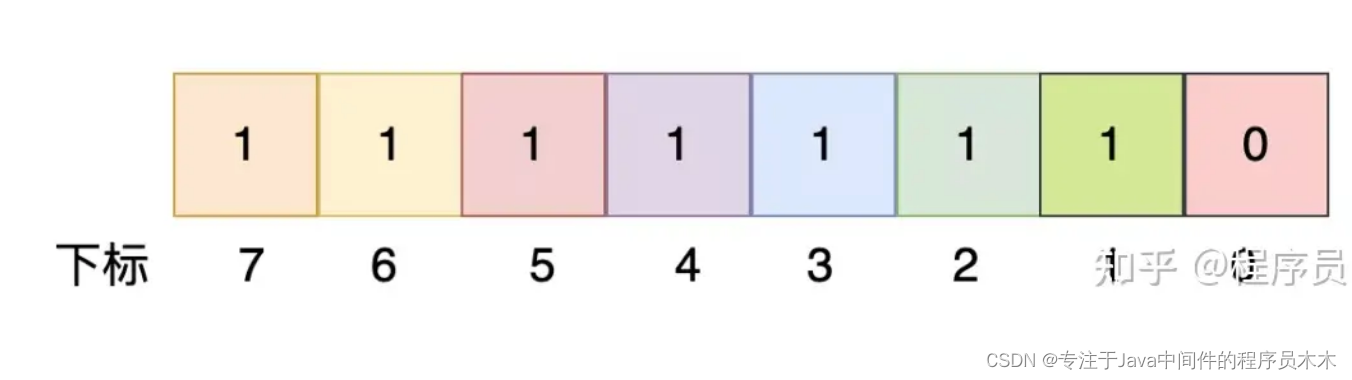
It can be seen that an unsigned char type data can identify the presence or absence of 8 integers from 0 to 7. And so on:
An unsigned int type data can identify the presence or absence of 32 integers from 0 to 31.
Two unsigned int type data can identify the presence or absence of 64 integers from 0 to 63.
Obviously, it can be deduced that 512MB is enough to identify the existence of all QQ numbers. Please note: the theoretical maximum value of QQ numbers is 2^32 - 1, which is about 4.3 billion.
The next question is very simple: use a 512MB unsigned int array to record the presence or absence of the QQ number in the file to form a bitmap, such as:
bitmapFlag[123] = 1
bitmapFlag[567] = 1
bitmapFlag[123] = 1
bitmapFlag[890] = 1
Actually it is:
bitmapFlag[123] = 1
bitmapFlag[567] = 1
bitmapFlag[890] = 1
Then traverse all positive integers (4 bytes) from small to large. When the bitmapFlag value is 1, it indicates that the number exists.
Summarize
1. Use HashSet to remove duplicates:
This is a simple and crude method, using the built-in hash collection data structure.
All 4 billion QQ numbers need to be loaded into the memory, so the 1GB memory limit may be exceeded.
The advantages are simple implementation and good query performance, but the memory usage is high.
2. Use Java 8’s Stream to deduplicate:
Utilize the stream operation feature of Java 8 to remove duplicates through the distinct() method.
It is also necessary to load all 4 billion QQ numbers into the memory, which may exceed the 1GB memory limit.
The advantage is that it is simple and easy to use, but it takes up a lot of memory.
3. Use the deduplication function of the database:
Use the deduplication function of the database to use the QQ number as a unique index or use the DISTINCT keyword to query.
The data needs to be stored in a database, which may require additional storage overhead.
The advantage is that it is suitable for large-scale data, but it needs to rely on the database system.
4. File fragmentation:
The data is stored in slices, each file stores part of the QQ number, and then deduplication is performed on each file.
You can deduplicate by reading files one by one and using HashSet, and finally merge the results.
Can accommodate 1GB memory limit, but requires additional file manipulation and merging steps.
5. External sorting algorithm:
Use an external sorting algorithm to divide the data into multiple parts and perform deduplication during the sorting process.
Can fit within 1GB memory limit, but requires additional sorting and merging steps.
6. Bitmap:
Use bitmaps to store 4 billion QQ numbers, and each QQ number uses one bit to indicate whether it exists or not.
Approximately 512MB of memory is required to store 4 billion QQ numbers.
7. Bloom filter:
Use Bloom filter to store 4 billion QQ numbers and use a small memory (596.05MB) to achieve deduplication function.
The specific memory usage of the Bloom filter depends on the expected number of insertions and the expected false positive rate, which can be estimated according to the formula.