Article directory
Series article index
Python crawler basics (1): Detailed explanation of the use of urllib library
Python crawler basics (2): Using xpath and jsonpath to parse crawled data
Python crawler basics (3): Using Selenium to dynamically load web pages
Python crawler basics (4): More convenient to use Python crawler basics of requests library
(5): Using scrapy framework
1. Use of requests library
The requests library is a third-party library written in Python language for accessing network resources. It is based on urllib, but is simpler, more convenient and user-friendly than urllib. The requests library can help automatically crawl HTML web pages and simulate human access to the server to automatically submit network requests.
Pay attention to comparing with urllib when using it.
1.Official documents
Official documentation:
https://requests.readthedocs.io/projects/cn/zh_CN/latest/
Get started quickly:
https://requests.readthedocs.io/projects/cn/zh_CN/latest/user/quickstart.html
2. Install the requests library
# 进入到python安装目录的Scripts目录
d:
cd D:\python\Scripts
# 安装
pip install requests -i https://pypi.douban.com/simple
3. Simple to use
import requests
url = 'http://www.baidu.com'
response = requests.get(url=url)
# 一个类型和六个属性
# Response类型:<class 'requests.models.Response'>
print(type(response))
# 设置响应的编码格式
response.encoding = 'utf-8'
# 以字符串的形式来返回了网页的源码
print(response.text)
# 返回一个url地址
print(response.url)
# 返回的是二进制的数据
print(response.content)
# 返回响应的状态码
print(response.status_code)
# 返回的是响应头
print(response.headers)
4. Use get request
Summary:
(1) Parameters are passed using params
(2) Parameters do not require urlencode encoding
(3) Customization of the request object is not required
(4) Question mark in the request resource path? You can add it or not add it.
import requests
url = 'https://www.baidu.com/s'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'wd':'北京'
}
# url 请求资源路径
# params 参数
# kwargs 字典
response = requests.get(url=url,params=data,headers=headers)
content = response.text
print(content)
5. Use post request
Summary:
(1) Post request does not require encoding and decoding
(2) The parameter of post request is data
(3) No customization of the request object is required
import requests
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'kw': 'eye'
}
# url 请求地址
# data 请求参数
# kwargs 字典
response = requests.post(url=url,data=data,headers=headers)
content =response.text
print(content)
import json
obj = json.loads(content)
print(obj)
6. Use a proxy
import requests
url = 'http://www.baidu.com/s?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
data = {
'wd':'ip'
}
proxy = {
'http':'212.129.251.55:16816'
}
response = requests.get(url = url,params=data,headers = headers,proxies = proxy)
content = response.text
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)
2. Actual combat
1. Practical combat: Login to the ancient poetry website
(1) Find the login page
Enter the ancient poetry website: https://www.gushiwen.cn/
click [My] to enter the login page https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx:
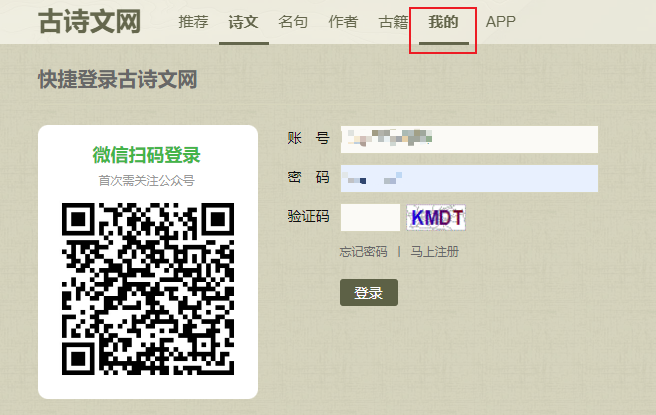
# 获取登录页的源码
import requests
# 这是登陆页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 获取页面的源码
response = requests.get(url = url,headers = headers)
content = response.text
What we need to do next is to see what data is needed to log in to this website.
(2) Data required for login operation
We enter the wrong verification code to determine the data required to call the login interface:
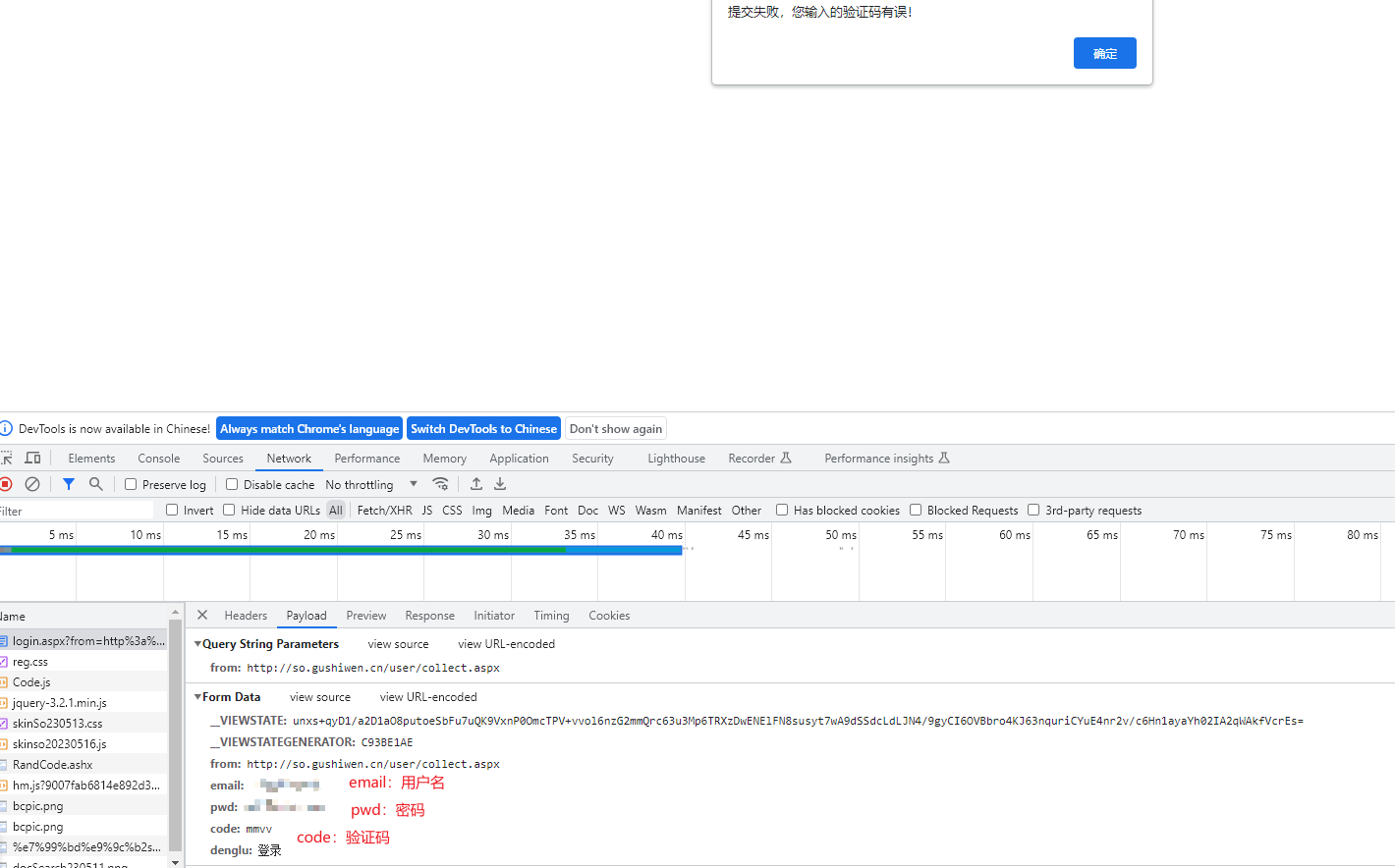
We all know that username, password and verification code are necessary for login.
In addition, the from and denglu form fields look like they are hard-coded.
However, __VIEWSTATE and __VIEWSTATEGENERATOR look like they are dynamically generated. How do we get them?
(3) Obtain data in the hidden domain
We right-click -> View web page source code, search globally, and find that __VIEWSTATE and __VIEWSTATEGENERATOR are data stored in the hidden field of the page. Generally, the data that cannot be seen is in the source code of the page, so we need to obtain the source code of the page. Then you can get it by parsing it.

# 解析页面源码 然后获取_VIEWSTATE __VIEWSTATEGENERATOR
# 我们此处用bs4进行解析
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# 获取_VIEWSTATE的值
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
print('获取__VIEWSTATE:' + viewstate)
# 获取__VIEWSTATEGENERATOR的值
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
print('获取__VIEWSTATEGENERATOR:' + viewstategenerator)
(4) Get verification code picture
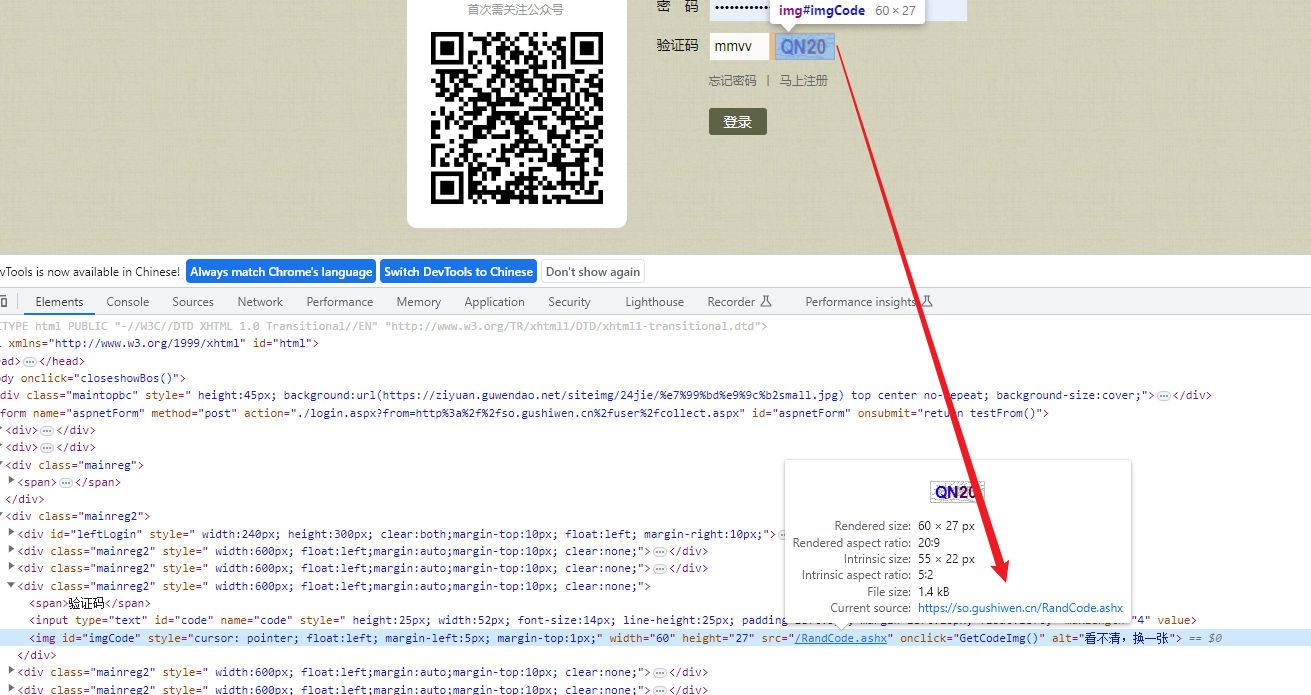
We found that the address of the image is: https://so.gushiwen.cn/RandCode.ashx, and it is a different verification code image every time it is refreshed.
Here we get the verification code image, which cannot be obtained directly through request, because we need to ensure that the sessions for each request are connected, so we need to obtain the verification code image through the session.
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
# 有坑,需要使用session进行验证码的获取
# import urllib.request
# urllib.request.urlretrieve(url=code_url,filename='code.jpg')
# requests里面有一个方法 session() 通过session的返回值 就能使用请求变成一个对象
session = requests.session()
# 验证码的url的内容
response_code = session.get(code_url)
# 注意此时要使用二进制数据 因为我们要使用的是图片的下载
content_code = response_code.content
# wb的模式就是将二进制数据写入到文件
with open('code.jpg','wb')as fp:
fp.write(content_code)
# 获取了验证码的图片之后 下载到本地 然后观察验证码 观察之后 然后在控制台输入这个验证码 就可以将这个值给
# code的参数 就可以登陆
code_name = input('请输入你的验证码')
Save the verification code locally, look at the verification code when logging in, and then enter it.
(5) Login operation
After obtaining all the data, assemble the data and call the login interface post request:
# 点击登陆
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstategenerator,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '', # 用户名
'pwd': '', # 密码
'code': code_name,
'denglu': '登录',
}
response_post = session.post(url = url, headers = headers, data = data_post)
content_post = response_post.text
with open('gushiwen.html','w',encoding= ' utf-8')as fp:
fp.write(content_post)
(6) Get my collection
After logging in, you only need to use the same session to get all my information.
# 获取我的收藏
collect_url = 'https://so.gushiwen.cn/user/collect.aspx?sort=t'
collect_info = session.get(url = collect_url)
collect_context = collect_info.text
with open('collect.html','w',encoding= ' utf-8')as fp:
fp.write(content_post)
2. Practical combat: Use Super Eagle verification code to automatically identify
(1) Super Eagle official website
http://www.chaojiying.com/
Price: http://www.chaojiying.com/price.html
(2) Download
Click [Development Document]: http://www.chaojiying.com/api-14.html
After the download is completed, there will be an example. You only need to use its API to achieve automatic image recognition:
