1. Suppose there are n nodes in an ordered singly linked list. It is now required to insert a new node so that the singly linked list remains ordered. The time complexity of this operation is ().
If you want to insert a new node into an ordered singly linked list to maintain the order of the singly linked list, the time complexity depends on the insertion position. Here are some common situations:
-
头部Insert a new node into the linked list: If you want to insert a new node at the head of the linked list, you only need to point the pointer of the new node to the head node of the current linked list and set the new node as the new head node .
The time complexity of this operation is O(1) because it only involves a constant number of operations. -
尾部Inserting a new node into the linked list: If you want to insert a new node at the end of the linked list, you need to traverse the entire linked list to find the tail node, and then point the pointer of the tail node to the new node .
The time complexity of this operation is O(n) , where n is the length of the linked list, because the entire linked list needs to be traversed. -
中间Inserting a new node into the linked list: If you want to insert a new node in the middle of the linked list, you need to find the previous node at the insertion position, then point the pointer of the previous node to the new node, and the pointer of the new node points to the node after the insertion position .
The time complexity of this operation is also O(n) , because in the worst case, the entire linked list needs to be traversed to find the insertion position.
2. When the linear list (a1, a2...an) is stored in a sequential manner, the time complexity of accessing the element at the i-th position is ().
When 线性表stored in a sequential manner, it is usually represented by an array . In this case, the time complexity of accessing the element at position i is O(1).
This is because the elements in the array are stored at consecutive memory addresses .
Therefore, the element at any position can be accessed directly by calculating the offset without traversing the entire array. As long as you know the index of the location you want to access, you can quickly access elements by index.
So the time complexity is constant time O(1).
3. Regarding the time complexity of the algorithm, the correct one is ()
A. The time complexity of an algorithm refers to the time required to execute the algorithm program.
B. The time complexity of the algorithm refers to the length of the algorithm program.
C. The time complexity of the algorithm refers to the number of basic operations required during the execution of the algorithm
. D. The time complexity of an algorithm refers to the number of instructions in the algorithm program.
Answer:C
Time complexity measures the growth trend of the running time of an algorithm as the input size increases , and is usually represented by the big O symbol (O). Time complexity does not directly refer to the execution time of the algorithm program (A), nor does it refer to the length of the algorithm program (B) or the number of instructions (D).
Instead, the efficiency of an algorithm is evaluated by analyzing the number of times basic operations in the algorithm are performed.
Time complexity describes the performance of an algorithm. It tells us the relationship between the running time of the algorithm and the size of the input.
4.—A complete binary tree with 12 nodes, its depth is (()
The depth of a complete binary tree can be determined by counting its nodes. The depth of a complete binary tree with n nodes can be calculated by:
-
If this complete binary tree is full ( each level has a maximum number of nodes ), the depth is
log2(n + 1). This is because the number of nodes in a full binary tree is2^d - 1, where d is the depth. -
If this complete binary tree is not full , the depth can be calculated through level traversal . Starting from the root node, traverse the tree layer by layer until you encounter the first empty node. Depth is the number of layers traversed.
In this problem, the given complete binary tree has 12 nodes, which is not full, so we need to use the second method to calculate the depth.
For a complete binary tree with 12 nodes, the depth can be found by level traversal:
- First level: 1 node
- Second level: 2 nodes
- Level 3: 4 nodes
Until the third level, there are a total of 7 nodes, and the fourth level starts to have no nodes. Therefore, the depth of this complete binary tree is 3.
5. The linked list requires the storage address of the element
A linked list is a data structure that consists of a sequence of nodes, each node containing a data element and a pointer (or reference) to the next node. The nodes of the linked list do not need to be stored adjacently in memory , so the storage addresses of the elements are not required to be consecutive.
In a linked list, each node contains a data element and a pointer to the next node, which stores the memory address of the next node . This design allows the linked list to effectively insert and delete elements without moving data like an array.
Therefore, the linked list does not require the storage address of the elements连续的 . It allows the elements to be stored dispersedly in the memory, as long as the pointer of each node points correctly to the next node.
This is an important difference between linked lists and linear data structures such as arrays.
6. Assume that the stack adopts a sequential storage structure. If i-1 elements have been pushed onto the stack, then when the i-th element is pushed onto the stack, the time complexity of the push algorithm is Oi, right?
Answer:不对
When the stack adopts a sequential storage structure, the time complexity of pushing the i-th element onto the stack is O(1), not Oi.
The stack of the sequential storage structure is implemented based on the array, and the top pointer of the stack points to the top element of the array. When you push a new element onto the stack, you simply put the element into the array at the next position of the top pointer and update the position of the top pointer. This operation has constant time complexity, independent of the number of elements in the stack , which is O(1).
Therefore, no matter how many elements are already pushed onto the stack, the time complexity of pushing the i-th element onto the stack is O(1).
7. Which of the following sorting algorithms is unstable?
A. Merge sort
B. Insertion sort
C. Heap sort
D. Quick sort
Answer:D. 快速排序
Quicksort is an unstable sorting algorithm.
Unstable sorting algorithm means that the relative position of the same elements may change during the sorting process .
During the sorting process of quick sort, the relative positions of the same elements may change, so it is unstable.
8. The node sequence obtained by pre-order traversal of a binary sorting tree is not necessarily an ordered sequence?
Answer:错误
The node sequence obtained by preorder traversal of a binary sorting tree (also called a binary search tree) is ordered.
In a binary search tree, the order of preorder traversal is to visit the root node first, and then visit the left subtree and right subtree in sequence.
Due to the nature of binary search trees, all nodes in the left subtree are smaller than the root node, and all nodes in the right subtree are larger than the root node , so the sequence obtained by preorder traversal is ordered. Specifically, preorder traversal 从小到大visits the nodes in the tree in order.
Therefore, the node sequence obtained by pre-order traversal of a binary sorted tree is ordered, not unordered.
9. The wrong description of the relational model is ().
A. Based on strict mathematical theory, set theory and predicate calculus formulas
B. Most microcomputer DBMS adopts relational data model
C. The use of two-dimensional tables to represent the relational model is a major feature of it
D. Does not have connection operations A DBMS can also be a relational database system
Answer:D. 不具有连接操作的DBMS也可以是关系数据库系统。
The join operation (Join) is one of the important operations in the relational database system. It is used to associate data in two or more tables according to certain conditions.
One of the core features of a relational database system is the ability to perform join operations between tables to support complex queries and data analysis. If a DBMS does not support join operations, then it does not meet the basic requirements of a relational database system.
Therefore, a DBMS without join operations cannot be called a relational database system.
10.In SQL language, the command to delete a table is ()
In SQL language, the command to delete a table is:
DROP TABLE table_name;
where table_nameis the name of the table to be deleted. This command will completely delete the specified table, including all data and structures in the table. Therefore, you should think carefully before executing this command and make sure that you really want to delete the table.
11. Which of the following is correct about the unique index of the database ()?
A. The table can contain multiple unique constraints, but there can only be one primary key.
C. The unique constraint column can be modified and updated.
D. The unique constraint cannot be used to define foreign keys.
Answer:C. 唯一约束列可修改和更新
A unique index is a constraint that ensures that a value in a column (or columns) in a table is unique , but allows the column's value to be modified and updated. It does not restrict the column value from being modified , it just requires that the modified value is still unique.
Other options are described below:
A. A table can contain multiple unique constraints, but only one primary key: This is correct, a table can have multiple unique constraints, but only one primary key constraint.
D. Unique constraints cannot be used to define foreign keys: This is incorrect. Unique constraints can be used to define foreign keys. Foreign keys require unique constraints on the referenced columns to ensure data integrity.
12. Each record in a relational database file ().
A. The order of front and back cannot be reversed arbitrarily. It must be arranged in the order of input.
B. The order of front and back can be reversed arbitrarily without affecting the data relationship in the library. C.
The order of front and back can be reversed arbitrarily, but the results of statistical processing may be different if the order is different.
D. The order cannot be reversed arbitrarily, and must be arranged in the order of the keyword field values.
Answer:C. 前后顺序可以任意颠倒,但排列顺序不同,统计处理的结果就可能不同
In a relational database, the order in which data is stored usually does not affect the correctness of the data , but in some cases it may affect the results of queries or statistical processing.
For example, when executing different queries, the way the data is sorted or arranged may result in different query results, depending on the query's conditions and sorting. Therefore, although data records in a relational database can be stored in different orders on physical storage, logical data relationships and consistency should be maintained .
Explanation of other options:
A. The order cannot be reversed arbitrarily, and must be arranged in the order of input: This is not necessarily correct. Records in the database are usually out of order , and the order in which records are inserted will not affect the correctness of the data.
B. The order can be reversed arbitrarily without affecting the data relationship in the database: This is not necessarily correct. If query, sorting or association operations are involved, the order of the data may affect the query results.
D. The order cannot be reversed arbitrarily, and must be arranged in the order of keyword field values: This is a description of a specific situation. For example, if you need to sort or retrieve according to the value of a certain field, then the data may need to be sorted or retrieved according to the value of that field. Arrange in order.
13.Athletes table contains athlete name, age and country represented. Which of the following queries will find the youngest athletes representing each country?
SELECT country, MIN(age) as youngest_age
FROM athletes
GROUP BY country;
This query will group by country and then find the youngest age (i.e. the youngest athlete) among the athletes in each country. The query results will include each country and the age of their youngest athlete.
14. If concurrent operations are not controlled, it may cause () problems.
If concurrent operations are not controlled, the following problems may occur:
-
Race Conditions : Multiple concurrent operations attempt to access or modify shared data at the same time, but without appropriate synchronization mechanisms, leading to unpredictable results. This can lead to data corruption or inconsistency.
-
Deadlock : Multiple processes or threads are waiting for the release of a resource, and they hold each other's resources, causing all processes or threads to be unable to continue executing.
-
Livelock : Multiple processes or threads are constantly changing their status, but ultimately cannot continue to perform meaningful work, similar to deadlock, but each process or thread is still running.
-
Data Consistency Issues : Concurrent operations may cause data consistency issues. For example, one operation reads data that is being modified by another operation, resulting in incorrect results.
-
Performance Issues : If concurrent operations are not controlled, they may cause resource contention, reduce system performance, increase response time, and even cause the system to crash.
15.What does system deadlock belong to?
A. Program failure
B. Transaction failure
C. System failure
D. Media failure
Answer:C. 系统故障
System deadlock refers to a situation in a computer system where multiple processes or threads wait for each other due to competition for resources, causing all processes or threads to be unable to continue executing.
This is a system-level failure that usually requires the operating system or resource manager to detect and resolve. Therefore, it is classified as a system failure.
16. Suppose there is a user table, which contains fields: userid (int), username (varchar), password (varchar), etc. The table needs to set a primary key. Which of the following statements is correct?
A. If username and password cannot be repeated at the same time, then username and password can be combined together as the primary key.
B. When designing the primary key for this table, based on the principle of minimum selection of the primary key, it is best to use userid as the primary key.
C. When designing the primary key of this table, according to the principle of minimum when selecting the primary key, it is best to use username and password as the composite key. D.
If userid is used as the primary key, then the value entered in the userid column is allowed to be empty.
Answer:B. 此表设计主键时,根据选择主键的最小性原则,最好采用userid作为主键
A primary key is a field that uniquely identifies each record in a table. According to the principle of minimization in selecting the primary key , it is best to choose a field that is unique enough as the primary key, and preferably a field that does not change frequently.
Generally, self-increasing integer fields (such as userid) are well suited for primary keys because they guarantee uniqueness and are not prone to conflicts. In this case, the value of userid column should not be empty and should be unique.
Combining username and password as the primary key mentioned in option A is generally not a good choice as this may cause performance issues and increased complexity. Normally, the primary key should be 简单且高效.
Therefore, according to the principle of minimum, it is best to use userid as the primary key.
17. In database technology, in order to improve the logical independence and physical independence of the database, the structure of the database is divided into three levels: user level, () and storage level.
A. Administrator level
B. External level
C. Concept level
D. Internal level
Answer:C、概念级
- External level (also called user level) : This is the highest level of abstraction and focuses on the external view of the database, i.e. how users see and access the database. At this level, the user's views, user permissions, and the external organization of the data are defined.
- Concept level : This level focuses on the logical structure of the entire database, including all data, tables, relationships, constraints, etc. The conceptual level defines the global schema of the database and is usually managed by the database administrator.
- Storage level (also called internal level) : This is the lowest level of abstraction, which focuses on the physical storage details of the database, such as data files, index structures, physical storage devices, etc. The storage level is responsible for mapping conceptual level logical structures to physical storage to achieve database performance and efficiency.
18. The () of data is to prevent the existence of data that does not conform to the semantics in the database, that is, to prevent the existence of incorrect data in the database. Data () is to protect the database from malicious damage and illegal access.
Data integrity is to prevent the existence of data that does not conform to semantics in the database, that is, to prevent the existence of incorrect data in the database. Data security (security) is to protect the database from malicious damage and illegal access.
Maintaining data integrity is ensuring the accuracy and consistency of data, often accomplished by applying data constraints and rules. Data security includes data confidentiality, availability and integrity to prevent unauthorized access, data leakage or damage. Data security is usually achieved through security measures such as authentication, authorization, and encryption.
19. A computer often has multiple processors, each of which has its own different tasks, some are used for drawing, and some are used for communication. The processor responsible for running system software and application software is called_
The processor responsible for running system software and application software is usually called the main processor or central processing unit (CPU) .
The main processor is responsible for executing the computer system's operating system and application programs, as well as managing the computer's various hardware resources. Other processors (such as graphics processors, communications processors, etc.) may be used for specific tasks, but the main processor is usually the heart of the computer and is responsible for coordinating and executing various tasks.
20. In the following description about virtual memory, the correct one is ( ).
A. It requires that the program must be completely loaded into the memory before running and it does not have to reside in the memory during the running process.
B. It requires that the program does not need to be completely loaded into the memory before running and does not need to reside in the memory during the running process.
C. It requires that the program does not need to be loaded into the memory before running. All are loaded into the memory but must remain in the memory during operation
. D. Requires that the program must be completely loaded into the memory before running but does not need to remain in the memory during operation.
Answer:B. 要求程序运行前不必全部装入内存且在运行过程中不必一直驻留在内存
Virtual memory is a computer memory management technology that allows programs to load part of the program and data into the memory before running , 根据需要so as to effectively utilize limited memory resources.
When the program is running, only the part of the data and code currently needed will reside in the memory, and other parts may be swapped to the disk to free up memory space for use by other programs.
This mechanism can make computer systems more flexible, allowing larger programs to be run because the entire program does not need to be loaded into memory at once. Therefore, option B is the correct description of the characteristics of virtual memory.
21. The purpose of using buffer technology in the operating system is to enhance the capabilities of the system ( ).
The purpose of using buffering technology in the operating system is to enhance the system's I/O (input/output) capabilities.
Cache technology can help the operating system manage and optimize data read and write operations more effectively to reduce frequent access to external storage devices such as disks, thereby improving the system's I/O performance and response speed.
By temporarily storing data in a memory buffer, you can reduce the number of I/O operations, optimize data transmission, reduce waiting time, and improve the overall performance of the system.
22. Recursion is usually implemented with ().
A. Ordered linear list
B. Queue
C. Stack
D. Array
Answer:C、栈
Recursion is a programming technique that calls itself. When a recursive function is executed, each level of call will save the current state in the call stack.
23. Among the following descriptions, the correct one is ().
A. The optical disk drive belongs to the host, while the optical disk belongs to the peripheral
device. B. The camera belongs to the input device, while the projector belongs to the output device. C.
The U disk can be used as external storage or memory.
D. The hard disk is auxiliary storage and does not belong to the peripherals
Answer:B. 摄像头属于输入设备,而投影仪属于输出设备
A camera is typically used to capture images or videos and input them into a computer, and is therefore an input device.
A projector is usually used to display images or videos from a computer, so it is an output device.
Other options are described below:
A. Both optical drives and optical discs are computer peripherals. Optical disc drives are used to read data from optical discs, which are storage media.
C. A USB flash drive is usually used as an external storage device, but it can also be used as a memory expansion device for the computer (for example, as virtual memory). So this description is correct to some extent, but it requires more context to determine the specific use.
D. The hard disk is a kind of auxiliary memory, usually called the external storage device of the computer, and is not a peripheral device. Hard drives are used to permanently store data and programs, while peripherals usually refer to auxiliary devices connected to the computer, such as keyboards, mice, printers, etc.
24.TCP and UDP each have their own port numbers. They do not interfere with each other and can coexist on the same host. (),Is it right
Answer:正确
TCP and UDP each have their own port numbers. They do not interfere with each other and can coexist on the same host.
TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are two different transport layer protocols that are used to transmit data in computer networks.
Each protocol has its own range of port numbers, which are used to identify different applications or services. There is no conflict between TCP ports and UDP ports, they can exist on the same host at the same time to support different types of network communications. This approach allows the computer to run multiple TCP and UDP applications simultaneously without conflict.
25. Computer network communication adopts two methods: synchronous and asynchronous, but the transmission efficiency is the highest ().
The most efficient transmission is asynchronous communication .
In synchronous communication, data transmission is carried out according to a predetermined clock signal or time interval, which is required by the sender and receiver. This 严格同步ensures that there will be no errors in the data during transmission, but it also brings additional overhead and complexity.
In contrast, in asynchronous communication, data transmission is carried out at irregular time intervals and does not require strict synchronization, so it is more flexible and efficient. Asynchronous communication is usually used for short message transmission and low-speed communication, such as serial communication.
Therefore, from a transmission efficiency perspective, asynchronous communication is generally more efficient. However, it should be noted that different application scenarios may require different communication methods, because synchronous communication is more reliable in some cases.
26. The following statement about network bridges is incorrect ( ).
A. The network bridge works at the data link layer, segmenting the network and connecting two physical networks into one logical network. B. The network bridge
can filter data that is not to be transmitted and effectively prevent broadcast storms.
C , The bridge can connect to LANs with different data link layer protocols.
D. The bridge needs to process the data it receives, which increases the transmission delay.
Answer:A. 网桥工作在数据链路层,对网络进行分段,并将2个物理网络连接成1个逻辑网络
A bridge usually does not segment the network. Its main function is to connect two or more physical networks and forward data frames based on MAC addresses. Bridges connect these physical networks into a single logical network rather than segmenting them. The function of a bridge is to transmit data frames from one physical network to another to achieve cross-network communication.
The descriptions of the other options are correct:
B. The bridge can effectively prevent broadcast storms by filtering data that does not need to be transmitted. The bridge can filter out data frames that do not need to be passed to other networks, thereby reducing redundant data transmission in the network and preventing broadcast storms.
C. Bridges can connect LANs with different data link layer protocols. Bridges connect local area networks that use different data link layer protocols and help these networks communicate.
D. The bridge has to process the data it receives, which increases the transmission delay. The bridge needs to check the destination address of the data frame and forward the data frame to the appropriate network. This process will add a certain amount of transmission delay, but it is usually very small and has little impact on network performance.
27. The IP protocol is connectionless, and its information transmission method is ()
The IP protocol is connectionless , and its information transmission method is datagrams .
In the IP protocol, data is divided into small packets (datagrams), each packet containing information such as the destination address, and then transmitted over the Internet. These packets can be transmitted through different paths and intermediate nodes, and finally reassembled at the destination address. Each data packet is transmitted independently without a pre-established connection state, so it is called a connectionless datagram transmission method.
This packet switching method makes the IP protocol suitable for flexible and distributed network environments.
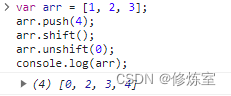
28. The result of running the following jacascip code in the browser is:
var arr = [1, 2, 3];
arr.push(4);
arr.shift();
arr.unshift(0);
console.log(arr);
The running results are as follows:
[0, 2, 3, 4]
explain:
- The initial array is
[1, 2, 3]. arr.push(4);Add the number 4 to the end of the array and the array becomes[1, 2, 3, 4].arr.shift();Remove the starting element of the array and the array becomes[2, 3, 4].arr.unshift(0);Add the number 0 to the beginning of the array and the array becomes[0, 2, 3, 4].console.log(arr);Output the modified array[0, 2, 3, 4].
29.The output result of the following code is
(function() {
var a = b = 5;
})();
console.log(b);
console.log(a);
The output of this code results in an error. In the code (function() { var a = b = 5; })();, bis defined as a global variable, and ais defined as a local variable. So, inside the function, aand bare both set to 5, but their scopes are different.
However, since bis a global variable, it is also visible outside the function. So, although ait is only visible inside the function, it bis still accessible outside the function.
The following is the execution flow of the code:
(function() { var a = b = 5; })();in(function() { ... })();is an immediately executed function. A local variable is defined inside the functiona, but a global variable is also definedband set to 5.console.log(b);Printbthe value of the global variable. Its value is 5, so it will be output5.console.log(a);Attempting to print the value of a local variableawill not be visible outside the function, so an error will result, and the console may report an errora is not defined(a is not defined).
So, this code will output:
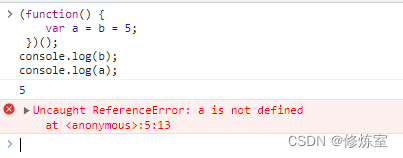
5
Uncaught ReferenceError: a is not defined
30. How to judge whether a js object is an Array, and arr is the object to be judged. What is the most accurate method?
A、typeof(arr)
B、arr instanceof Array
C、arr.toString===‘[object Array]’;
D、Object.prototype.toString.call(arr) === "[object Array]';
The most accurate method is option D, which is Object.prototype.toString.call(arr)used to determine whether a JavaScript object is an array. This is because it takes into account not only the object's type, but also the object's prototype chain, so it can correctly distinguish between arrays and other object types.
The specific code is as follows:
if (Object.prototype.toString.call(arr) === "[object Array]") {
// arr 是一个数组
} else {
// arr 不是一个数组
}
Option A ( typeof arr) will only tell you the type of object, but it cannot accurately distinguish arrays from other object types, because in JavaScript, arrays are also objects, so it will return "object".
Option B ( arr instanceof Array) will work in most cases, but if you pass the array between multiple windows or frames, there is a chance that instanceof will not work, so it is not as accurate as option D.
Option C ( arr.toString() === '[object Array]') is not a common way to tell if an object is an array, and is not accurate enough. The toString method returns a string representation of the object, not the object's actual type.
31. Which of the following options are native js methods for operating arrays?
A、splice
B、shift
C、resort
D、sort
Answer:C、resort
Native JavaScript methods for manipulating arrays include the following options:
A.: spliceUsed to add or remove elements from an array.
B shift.: Used to delete the first element of the array and return the deleted element.
D sort.: Used to sort array elements.
"resort" in option C is not a native JavaScript array method. The correct spelling is "reverse", which is used to reverse the order of elements in an array.
32.Which of the following operations is defined by the W3C standard to prevent events from being passed to the parent container?
The operations defined by the W3C standard to prevent events from being delivered to the parent container are:
event.stopPropagation()
This method is used to prevent event bubbling, that is, stop the event from being passed from the triggering element to the parent element. When you call in an event handler event.stopPropagation(), the event does not continue to higher-level elements, but stops on the current element.
In addition, there is a related method event.preventDefault()that is used to prevent the default behavior of the event, such as preventing the jump of the link or the submission of the form. These two methods can be used together to achieve more precise event control.
33.The output of the following code is:
(function() {
var x = foo();
var foo = function foo() {
return “foobar"
};
return x;
})();
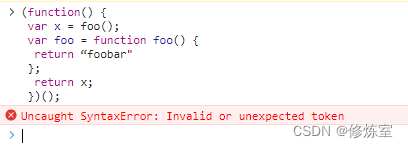
There is a bug in the provided code: in var x = foo();, an attempt is made to call foo()the function before the function is declared. This will cause a ReferenceError because fooit has not been defined before this line.
Correct code would be to declare the function first fooand then call it. The corrected code is as follows:
(function() {
var foo = function foo() {
return "foobar";
};
var x = foo();
return x;
})();
In this corrected code, foothe function named is declared first, and then the function is called on the next line foo(). Function fooReturns the string "foobar" and assigns it to a variable x. Finally, the function executes immediately and returns x.
The output of the corrected code is:
"foobar"
33. When styles are not involved, the priority display of page elements has nothing to do with the structural placement order. Please decide whether this sentence is correct or not.
This sentence is incorrect. When styles are not involved, the priority display of page elements is related to the structural placement order .
In HTML, the structural placement order of page elements determines their hierarchical structure in the DOM (Document Object Model). When the browser renders a page, it follows the structure of the DOM 从上到下逐个处理元素and renders them on the page.
Therefore, elements that appear earlier in the DOM structure will appear in front on the page, while elements that appear later will appear in the back on the page.
Although the content of page elements may be the same without styling involved, their display order is still affected by the order in which they are arranged in the DOM structure. Only when you apply CSS styles to control the position and appearance of elements can you more flexibly control the display order of elements.
34. Among the following html semantic tags, which one has an incorrect description?
A. <em>emphasis text, <blockquote>long text quotation
B.<strong>emphasis text, <h1>article column titleC
.<a>hyperlink, <p>article paragraphD
. <ul>ordered list. <ol>Unordered list
Answer: D. <ul>It is an unordered list and <ol>it is an ordered list.
The description in this option confuses the meaning of <ul>(unordered list) and <ol>(ordered list). In fact, <ul>is used to create unordered lists (e.g., bulleted lists), while <ol>is used to create ordered lists (e.g., numbered lists). The meaning and purpose of these two labels are different.
The description in the other options is correct:
A. <em>Used to emphasize text and <blockquote>to express long text quotations.
B. <strong>Used to emphasize text and <h1>indicate the title of an article column.
C. <a>Used to create hyperlinks <p>to represent article paragraphs.
35. Which of the following descriptions of the advantages and disadvantages of Ajax and Flash is correct?
A. The advantage of Ajax lies in its openness, ease of use and ease of development.
B. The advantage of Flash lies in multimedia processing, which can more easily call external resources outside the browser.
C. The main criticism of Ajax is that it may destroy the browser. Back function
D. Flash files are often very large, and users need to endure a long waiting time when using them for the first time.
The correct description is:
A. The advantages of Ajax are openness, ease of use and ease of development.
B. The advantage of Flash lies in multimedia processing, which makes it easier to call external resources outside the browser.
C. The main criticism of Ajax is that it can break the browser's back functionality.
D. Flash files are often very large, and users need to endure a long waiting time when using them for the first time.
These descriptions cover some common advantages and disadvantages of Ajax and Flash.
Ajax is generally more open and easier to develop, providing a better user experience, but may cause problems with the browser's back functionality.
Flash has advantages in processing multimedia, but Flash files may be larger, causing users to wait longer when loading for the first time.
36. The value of the element’s type attribute can be ()
A、image
B、checkbox
C、button
D、select
Answer:A、B、C
A. image: Used to create image buttons.
B.: checkboxUsed to create check boxes.
C button.: Used to create ordinary buttons.
D select.: This is not the attribute value <input>of the element type, but <select>the element used to create the drop-down list.
37.JavaScript defines var a="40", var b=7, then executing a%b will get ().

In JavaScript, execution a % bmeans calculating the remainder of variable adivided by variable .b
If the values of aand bare "40" and 7, then executing a % bwill result in a remainder of 5, because the remainder of dividing 40 by 7 is 5. So, executing a % bwill get 5.
38.CSS style, margin: 10px 20px 40px 30px; which one is the bottom margin?
In CSS, marginthe value of the attribute represents the top, right, bottom, and left margins in clockwise direction. In the given style margin: 10px 20px 40px 30px;, the order of values is top, right, bottom, left, so the corresponding value of the bottom margin is 40px.
39. To set the text color, attributes should be used
Setting text color should use CSS properties color. You can use this property to specify the color of text, using a color name, a hexadecimal color code, or an RGB value to represent the color.
For example:
p {
color: red; /* 使用颜色名称 */
}
span {
color: #0077b6; /* 使用十六进制颜色代码 */
}
h1 {
color: rgb(255, 0, 0); /* 使用RGB值 */
}
The above code sets the text color of paragraphs, <span>elements, and headings to different colors respectively. You can choose the appropriate color representation method according to your needs.
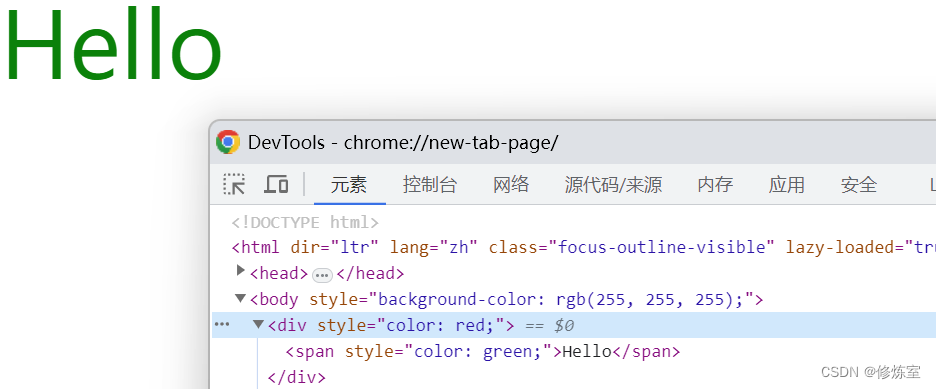
40. There is a piece of html code:
<div style="color: red;">
<span style="color: green;">Hello</span>
</div>
Then the font color of "Hello is ()
<div> The font color of the element's text "Hello" is green ("green").
41. Among css selectors, the priority order is correct
A. id selector > tag selector > class selector
B. id selector > class selector > tag selector
C. Class selector > tag selector > id selector
D. Tag selector > class selector > id Selector
Answer:B. id选择器 > 类选择器 > 标签选择器
This means that in CSS, with the same style rules, the id selector has the highest priority, followed by the class selector, and finally the tag selector.
This is due to the fact that the id selector should be unique within the document and therefore have higher priority, while the tag selector is the most common and therefore has the lowest priority.
If you have the same selector type (for example, two class selectors or two label selectors), the priority of applying styles is determined based on the order in which they appear in the style sheet.
42. Please choose the correct answer
A. The div tag can be used as a separator tag.
B. The code indentation in the tag in html is for the convenience of reading.
C. <div ><p>Niuke.com</div></p>
D. It cannot be used in <div> Nested ul, h tags
Answer:B. HTML中标签中的代码缩进是为了方便阅读
Code indentation in HTML is generally used to improve the readability of the code, but it does not affect the structure or rendering results of the HTML. Indentation helps developers understand the hierarchy and nesting of code more easily.
There are some errors or unclear descriptions in other options:
A. The "div" tag is often used as a container to separate content, but "div" itself is not a tag specifically used for separation.
C. There is a tag mismatch problem in the provided HTML code. It should be that the tags <div><p>牛客网</p></div>are nested correctly <p>.
D. <div>Tags can nest other HTML elements, including <ul>and <h>tags, as long as their nesting structure is valid. Therefore, this description is not accurate