pre-training
1) The problem to be solved in feature extraction is how to quantify text and images separately, and then send them to the model for learning?
Feature extraction:
Text: tend to large models such as bert
Image: Neural Networks, VIT, etc.
2) The problem to be solved in feature fusion is how to make the representations of text and images interact?
The simplest: addition/splicing, but more ingenious structures can also be designed
3) The pre-training task is how to design some pre-training tasks (PreTask) to assist the model in learning the alignment information of images and texts?
Cross-modal feature fusion, etc.
Mainstream methods of pre-training
Feature extraction: Bert’s tokenizer is the standard configuration for text representation, and LSTM may have been used earlier; for images, some traditional and classic convolutional networks are used, and there are three main forms of extraction: Rol, Pixel, and Patch.
Feature fusion: the current mainstream approach is nothing more than two types, namely, two-stream or single-stream; the former is basically a two-tower network, and then some layers are designed for interaction at the end of the model, so the interaction of the two-stream structure Happened much later. The latter is a network such as a transformer, which enters a network for interaction from the very beginning, so the interaction time of the single-stream structure occurs earlier and throughout the process, which is more flexible.
Pre-training PreTask: This is the most interesting place, and it is also the embodiment of the idea of most multimodal papers. Here is a summary of some common standard tasks, and some special tasks will be introduced separately in the paper
Masked Language Modeling ( MLM )
Masked Region Modeling(MRM)
Image Text Maching (ITM)
self-supervised learning
significance
After learning a large amount of unlabeled data, a powerful feature extractor can be acquired, and it can also extract better features when facing new tasks, especially small sample tasks such as medical imaging.
common use
Relative Position Prediction: Predict the relative position between two randomly selected image patches in an image
Image Restoration: Predict the occluded part of an image Jigsaw Puzzle: Restore the 9 image blocks that were disturbed in the image
Rotation Angle Prediction: Predict the rotation angle of objects in the image
Image coloring: use the L brightness channel in the Lab image to predict the ab color channel
Cross-channel prediction: L channel and ab channel predict each other
Counting: predict the number of noses, eyes, paws, heads
Instance distinction: classification, an image and its enhanced image are of one class, and other images are of different classes
Contrasting Predictive Coding: Predicting "Future" Information Based on "Past" Information
Visual Self-Supervised Algorithm Based on Contrastive Learning
concept
The concept of contrastive learning has been around for a long time, and it is a method of unsupervised learning. How to learn without supervision information and no need to reconstruct the data? -- data enhancement + mutual information
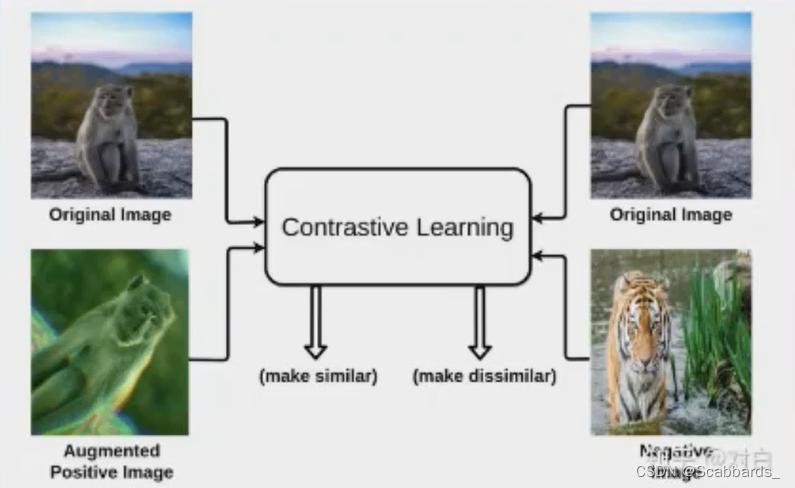
Its core is to draw the positive samples closer and the negative samples farther away by calculating the distance between sample representations. That is, when we are able to distinguish between positive and negative instances of that sample, the resulting representation is sufficient
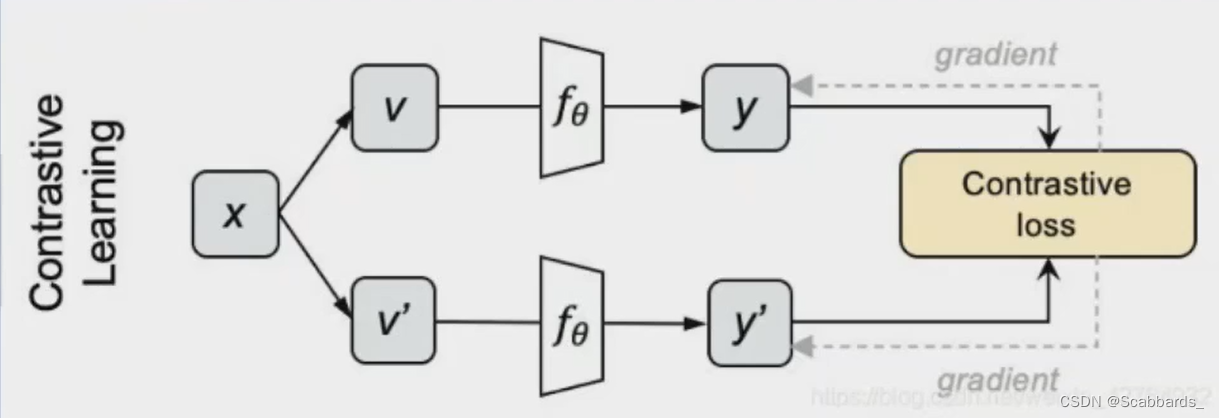
official
1. Sample N pictures and use different data enhancement methods to generate two views for each picture
2. Input them into the network respectively to obtain coded representations of y and y'
3. Calculate cosine pairwise for the upper and lower batches to obtain an NxN matrix. The diagonal position of each row represents the similarity between y and y', and the rest represent The similarity between y and N-1 negative examples. Do softmax classification for each row, use cross entropy loss as loss, and get the loss of comparative learning
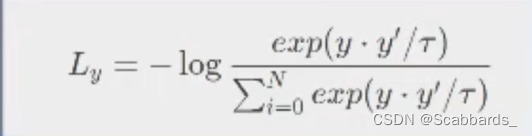
Where t \ tau t is an adjustable coefficient, the magnitude of the result after dot multiplication is not suitable for softmax operation, controlled by a t \tau t coefficient
Method to realize
end-to-end
Use the samples in the current batch as a dictionary
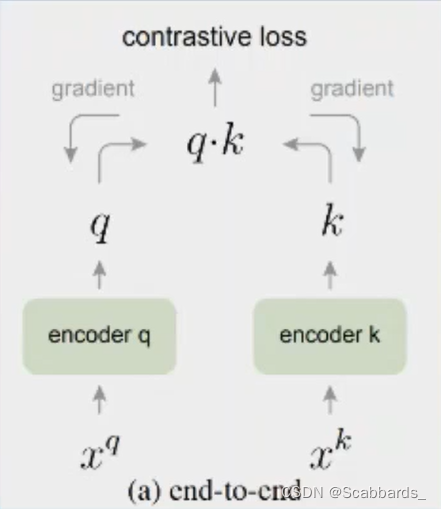
Disadvantages: limited by the GPU, the batch cannot be too large, and the dictionary is a big deal
memory bank storage queue
Set up a memory bank to store the previously encoded samples
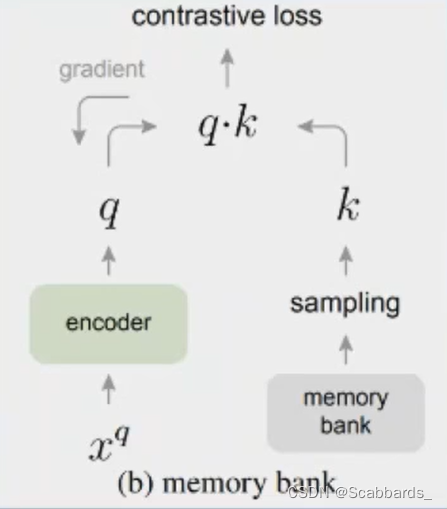
The stored codes are all calculated by the previous encoder, and the left encoder has been updating. There will be inconsistencies on both sides, which will affect the target optimization
Booger
Moco addresses the disadvantages of the above approach
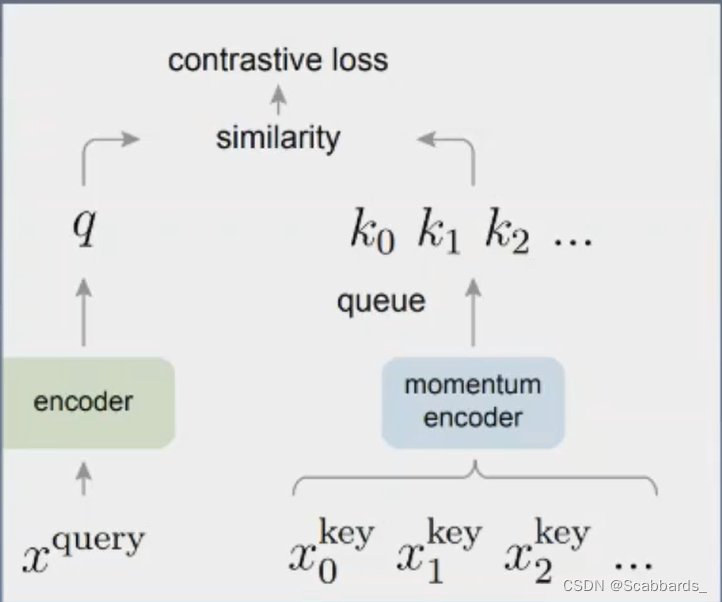
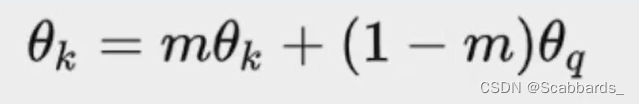

loss function
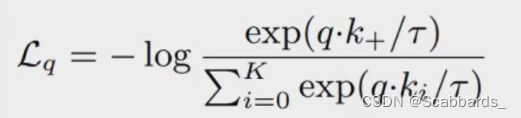
Assuming that there is a positive sample k+ and the rest are negative samples, according to the loss of nfoNCE, the loss is expressed as:
Among them, q and k+ can have various construction methods. This article uses a simpler way:
(1) Random resize a picture;
(2) Perform two random crops of 224*224 to obtain two images as q and k+ respectively;
(3) Perform enhanced operations, including random color jttering, random horizontal fliprandom grayscale conversion, etc.
use
Because comparative learning is to see whether it is similar, it can be used for retrieval, image search
Mask-based visual self-supervised algorithm
With Vision Transformer (ViT) dominating the major datasets in 2021, how to build a more suitable self-supervised learning paradigm based on ViT has become a major problem in this field. Initially, DINO and MoCo v3 tried to combine contrastive learning and ViT, and achieved good results. However, for a long time, due to the difference between the CV and NLP field data and the basic model, NLP's Masked Language Modeling (MLM) code mode mechanism has not been successfully applied to the CV field, but the recent vigorous development of ViT is the application of the mask learning mechanism. This opens the door to visual self-supervision.
Method to realize
BEIT
Inspired by BERT, the author proposes a pre-training task, masked image modeling (MIM) MIM uses two views for each image, the image patch and the visual token. The author divides the image into a grid of patches, which are the input representations of the main Transformer. In addition, the authors "tokenize" images into discrete visual tokens, which are obtained through latent codes of discrete VAEs. During pre-training, the author randomly masks some image patches and inputs the damaged ones to the Transformer. The model learns to recover the visual tokens of the original image, rather than the original pixels of the mask patch.
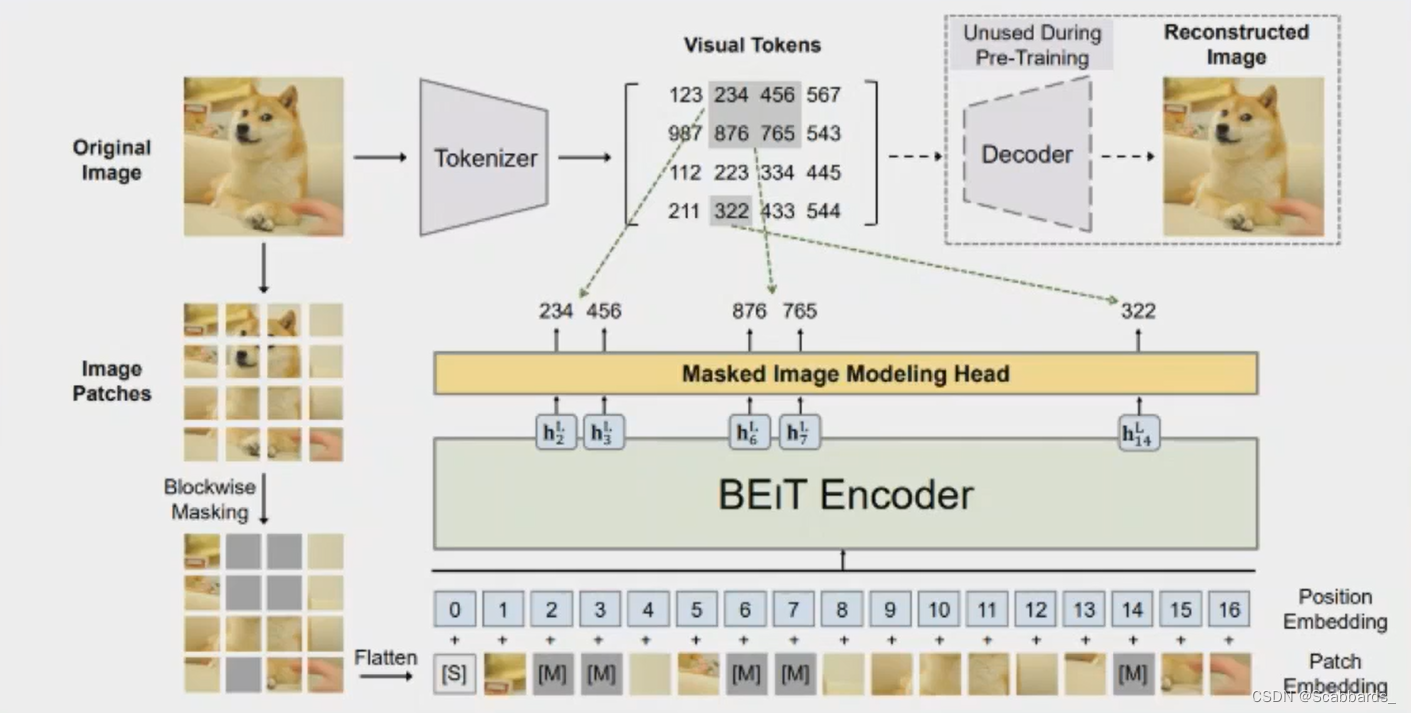
Images have two representation views, the image patch and the visual token. These two types are represented as pre-trained input and output, respectively.
Visual Token
Purpose: to get supervision signals
Learning image tokenizer via discrete variational autoencoder (DVAE). In the process of visual token learning, there are two modules, tokenizer and decoder. The tokenizer maps image pixels x to discrete tokens z according to the visual codebook (i.e., vocabulary). The decoder learns to reconstruct the input image x based on the token z. The rebuild target can be written as . Since the underlying visual tokens are discrete, model training is non-differentiable. Therefore, the author uses Gumbel-softmax to train the model. In addition, a unified prior is added to the tokenizer during dVAE training.
The authors label each image as a 14X14 visual token grid. The vocabulary size is set to 8192.
Image Patch
2D images are split into a series of patches so that standard Transformers can accept image data directly. Formally, the author reshape the image H*W*C into (H*W)/(P*P) patches, where C is the number of channels, (H, W) is the input image resolution, (P, P) is The resolution of each patch. Image patches are flattened into vectors and projected linearly, similar to word embeddings in BERT. Image patches preserve the original pixels and are used as input features in BEIT.
In the experiments in this paper, the author divides each 224X 224 image into a 14X14 image grid, where the size of each image grid is 16X16.
downstream task
Cross-modal retrieval
Task: Given a query in any modality of text or image, retrieve the most similar matching result in the gallery of other modality
Application: E-commerce commodity retrieval (search image by text)
accomplish
Matching Function Learning, corresponding to the ITM in the single-tower structure.
Representation Learning, corresponding to the comparison learning + cosine similarity in the twin towers
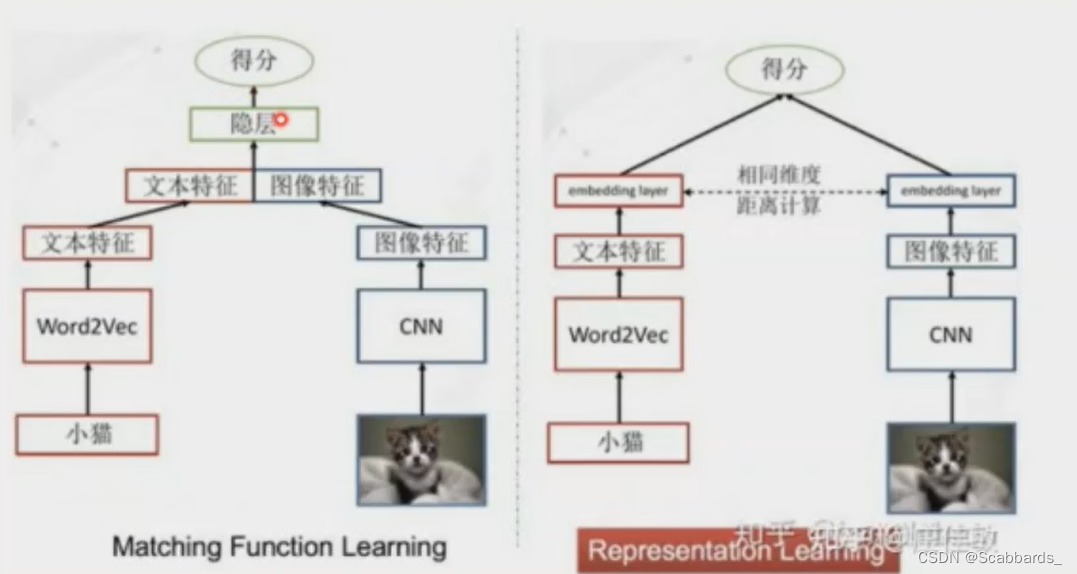
The main idea of the cross-modal similarity measurement method on the left is to fuse graphic and text features, and then pass through the hidden layer. The goal is to let the hidden layer learn a function that can measure cross-modal similarity.
The right side is the public space feature learning method, which is generally called the twin-tower structure. It maps images and texts into a public space to obtain multimodal representations, that is, the last layer of representations, so that cosine can be used directly to calculate the similarity. Images and text are independent of each other and do not interact with each other. It is hoped that an excellent representation can be learned to measure the similarity.
Research Hotspots and Ideas
In fact, I mainly do projects and do little research.
1. Propose a new cross-modal retrieval data set for a specific field, such as e-commerce, remote sensing, etc., and provide benchmarks; 2.
Cross-modal information alignment, how to introduce appropriate supervision signals;
3. Cross-modal How to better interact with information, how to combine single tower and double tower:
4. Difficult sample mining for cross-modal retrieval:
zeroshot classification
Convert the category label into a text description through a prompt process, then calculate the similarity between the image and the text mapped to each category label, and take the one with the highest similarity as the classification label

Application: Classification tasks where categories belong to the open set
accomplish
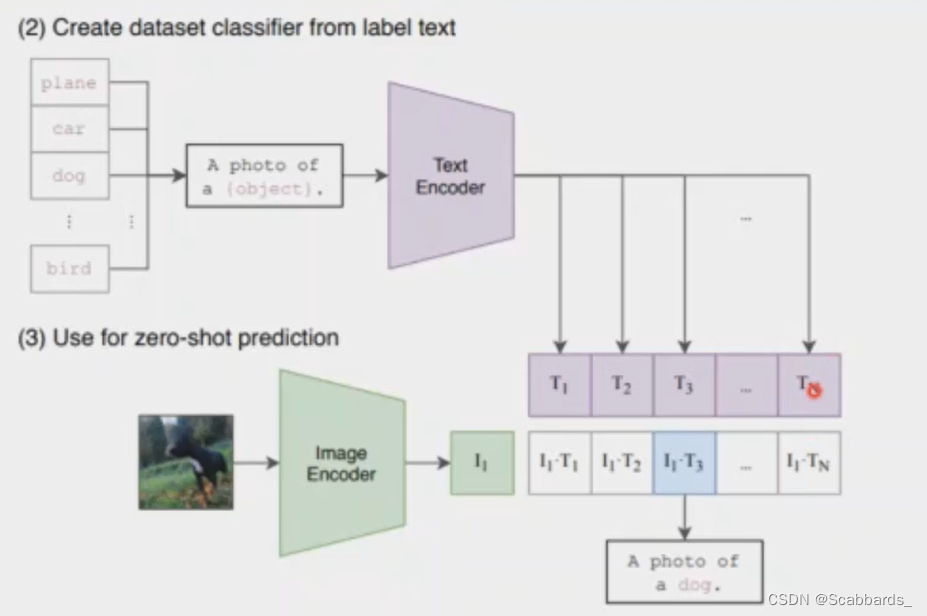
Convert the category label into a text description through a prompt process
Then calculate the similarity between the picture and the text mapped to each category label, and take the highest similarity as the classification label
dog -> A photo of a dog
**The design of the teleprompter also takes a lot of time to adjust, because small wording changes may have a huge impact on performance (for example, in Figure a below, add a before [CLASS] in "a photo of [CLASS]" "a" went straight up almost 6 points?! !)
How to design a suitable prompt;
https://arxiv.org/abs/2109.01134
Image Captaining
Task: Encoder: Input the picture into the Encoder to get visual features. The Encoder can use CNN or Transformer; the visual features can be decoded into a sequence of words through the Decoder. The Decoder can use LSTM or Transformer
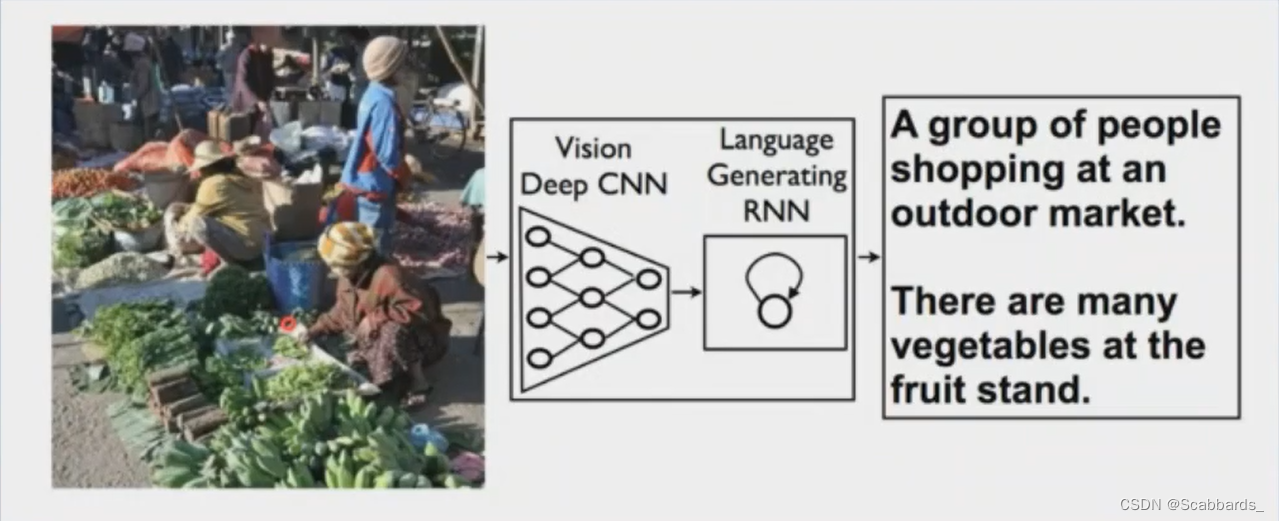
Encoder: The picture is input into the Encoder to obtain visual features. The Encoder can use CNN or Transformer.
Decoder: The visual features are decoded into a sequence of words through the Decoder. The Decoder can use LSTM or Transformer.
accomplish
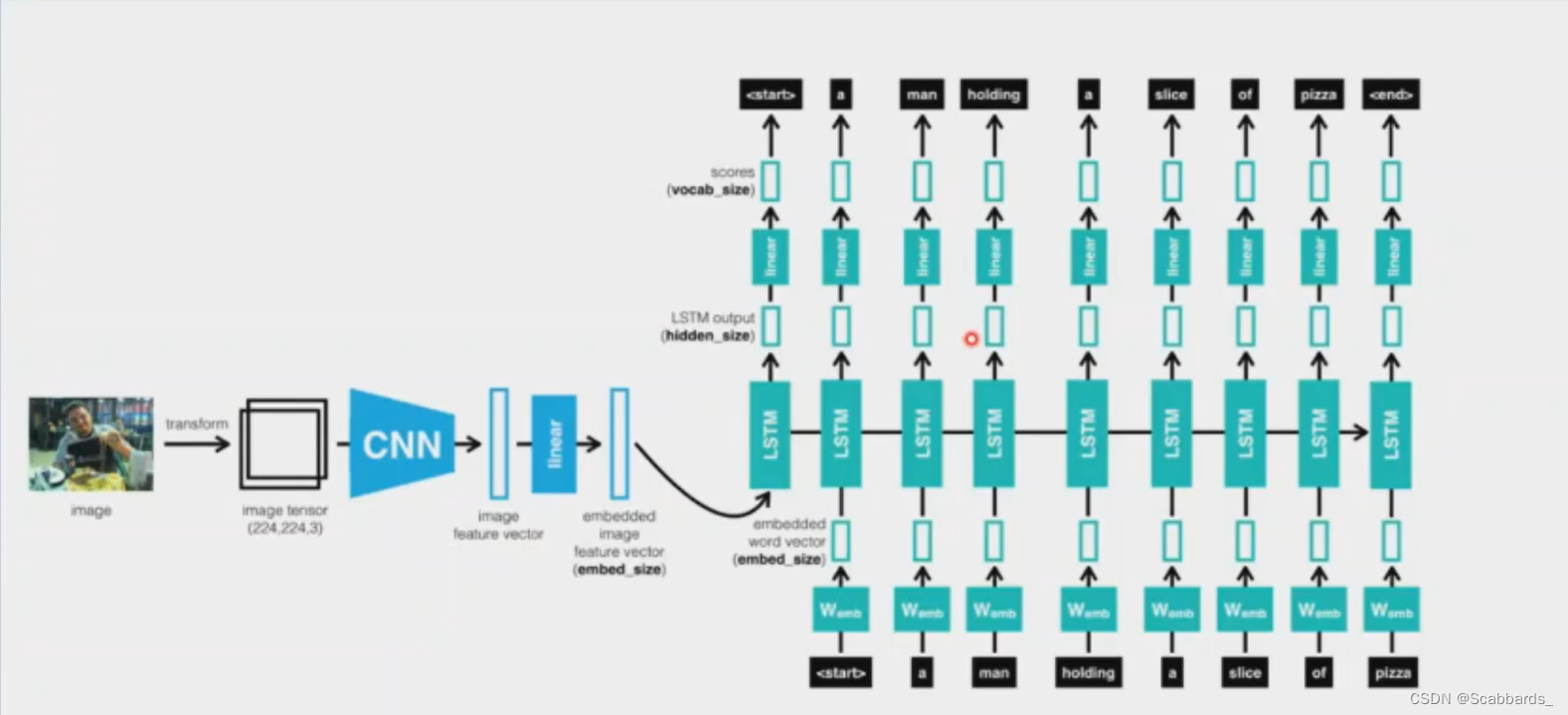
We pass all inputs to the LSTM as a sequence, and the sequence looks like this:
1. First extract the feature vector from the image
2. Then a word, the next word, etc.
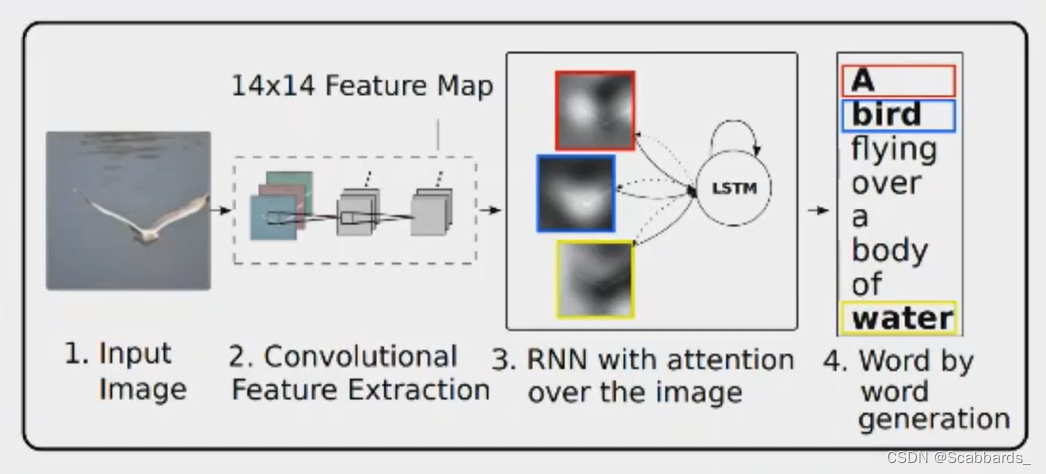
1) CNN performs convolution to extract feature information of the picture and finally forms feature map information of the picture
2) attention strengthens and suppresses the extracted feature map as input data for the subsequent LSTM model, and the attention data at different times will be affected by the LSTM at the previous moment The model output data is adjusted
3) LSTM model finally outputs text information

**Encoder stage, CNN (Convolutional Neural Network) is used in the article to extract feature map vectors
In order to obtain the correspondence between the feature vector and the specific position of the picture, the author extracts features from the shallow convolution kernel instead of the fully connected layer. By inputting a subset of a aa, this enables the decoder to selectively focus on a certain part of the picture. part

Decoder stage: use LSTM as decoder to generate a word at each step
shortcoming:
low efficiency
For long-term modeling ability is relatively weak
Research Hotspots and Ideas
1) Propose a new ImageCaptioning data set for a specific field, such as e-commerce field (automatic product description generation), remote sensing field, etc., and provide benchmark; 2) Design a more robust model structure, mainly based on
Transformer;
3) semantic alignment;