Click on the card below to follow the " CVer " public account
AI/CV heavy-duty information, delivered as soon as possible
Click to enter -> [3D Point Cloud and Transformer] communication group
Reply in the background of CVer WeChat public account: PointGPT, you can download the pdf and code of this paper
3D point clouds show great potential in various applications such as autonomous driving, robotics and augmented reality. Unlike the regular pixels in 2D images, the arrangement of 3D points is irregular, which hinders the direct adoption of well-studied 2D networks for processing 3D data. Therefore, it is imperative to explore advanced methods suitable for 3D point cloud data. However, current 3D-centric methods often require fully supervised training from scratch, which requires labor-intensive manual annotation. In the fields of natural language processing (NLP) and image analysis, self-supervised learning (SSL) has emerged as an annotation-independent method for obtaining latent representations. Among these methods, Generative Pretrained Transformer (GPT) is particularly effective in learning representative features, whose task is to predict the data in an autoregressive manner. Due to its excellent performance, the question naturally arises: can GPT be adapted to point clouds and serve as an effective 3D representation learner?

Pre-training for automatic regression generation from point clouds
PointGPT
Paper interpretation
Summary
This paper introduces a method called PointGPT, which extends the concept of GPT to point cloud data to solve the challenges of point cloud data's disorder, low information density, and task intervals. The paper proposes a point cloud autoregressive generation task to pre-train the Transformer model. This method segments the input point cloud into multiple point patches and arranges them into an ordered sequence based on their spatial proximity. Then, the extractor-generator based Transformer decoder (using a double masking strategy) learns the latent representation conditioned on the previous patch to predict the next patch in an autoregressive manner. This scalable approach can learn high-capacity models that generalize well and achieve state-of-the-art performance on a variety of downstream tasks. Specifically, the method achieved a classification accuracy of 94.9% on the ModelNet40 dataset and a classification accuracy of 93.4% on the ScanObjectNN dataset, surpassing all other Transformer models. Additionally, the method achieves new state-of-the-art accuracy on four few-shot learning benchmarks.
Paper link: https://arxiv.org/pdf/2305.11487.pdf
Code link: https://github.com/CGuangyan-BIT/PointGPT
Paper contribution
1. A new GPT model named PointGPT is proposed for point cloud self-supervised learning (SSL). PointGPT utilizes point cloud autoregression to generate tasks while mitigating the problem of location information leakage, and performs well among single-modal self-supervised learning methods.
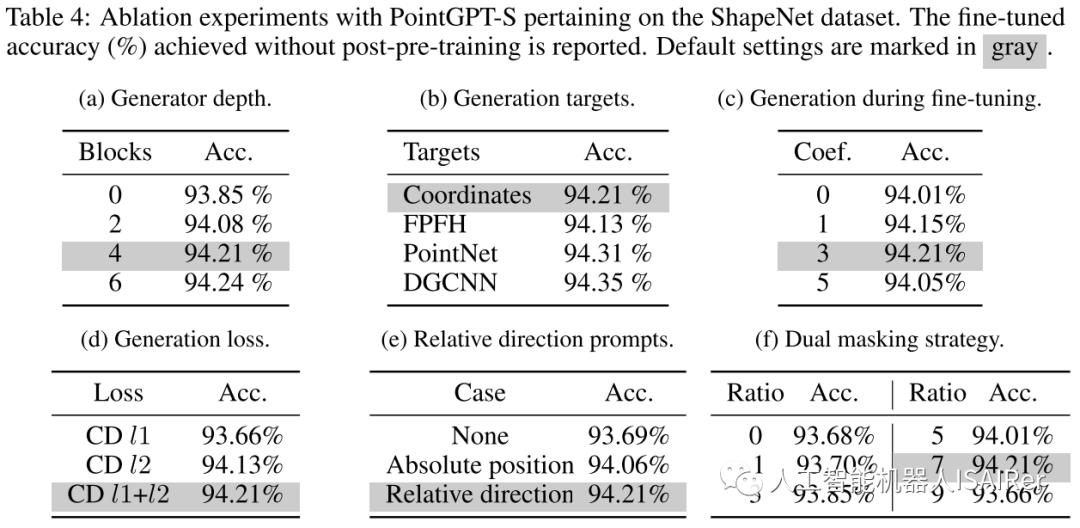
2. Propose a double masking strategy to create effective generation tasks, and introduce an extractor-generator Transformer architecture to enhance the semantic level of learned representations. These designs improve the performance of PointGPT in downstream tasks.
3. A post-pretraining stage is introduced and a larger dataset is collected to facilitate high-capacity model training. Leveraging PointGPT, our extended model achieves state-of-the-art performance on a variety of downstream tasks.
overall framework
The schematic diagram of the PointGPT method is shown in Figure 1. The input point cloud is segmented into point patches and arranged into an ordered sequence according to their spatial proximity. This sequence is input to the Transformer decoder, which predicts the next block based on the previously predicted block. This autoregressive approach enables the model to gradually generate point blocks, and the model can use previously generated point blocks to predict the next point block. In this way, PointGPT's method is able to predict without specifically specifying point blocks and avoids the problem of location information leakage, thereby improving the generalization ability of the model. The advantage of this method is that it can handle the disorder of point cloud data and show good performance on various downstream tasks.
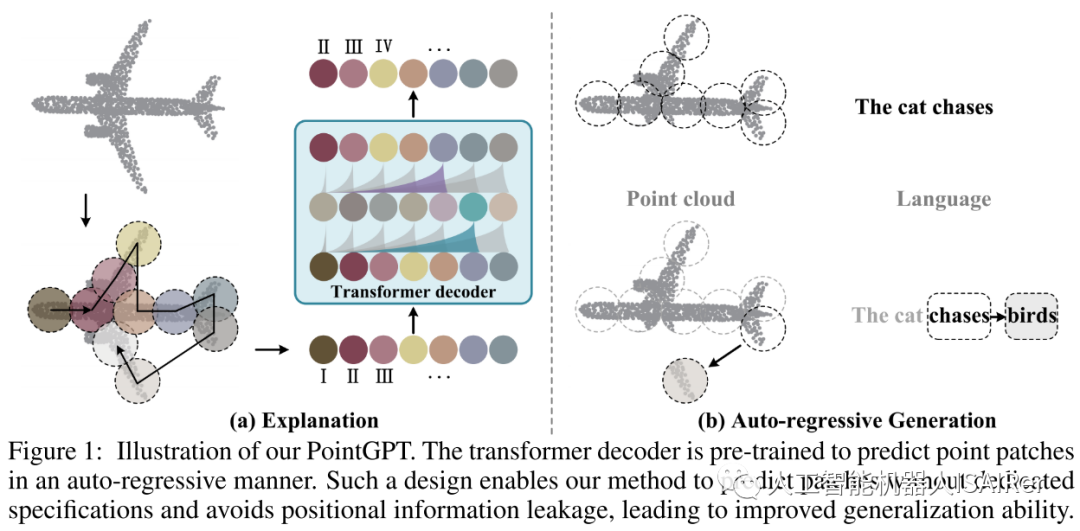
Figure 2 shows the overall process of PointGPT in the pre-training stage.
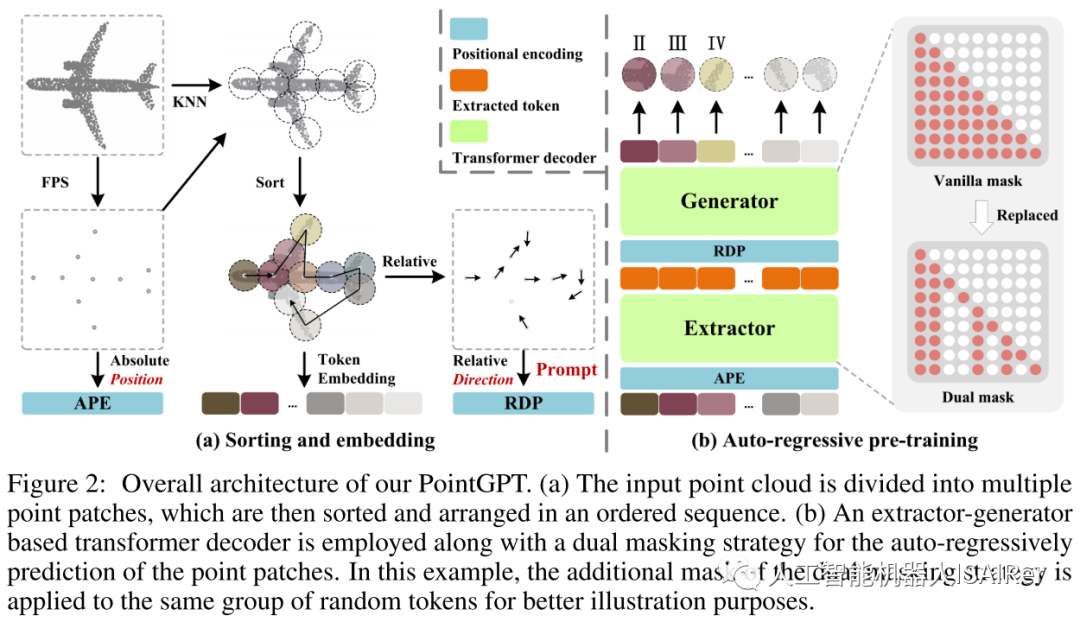
1. Point cloud sequence module
The pre-training process of PointGPT includes using the point cloud sequence module to construct an ordered sequence of point blocks, the extractor learns the latent representation of the point blocks, and the generator autoregressively generates the sequence of point blocks. In the post-training stage, the generator is discarded and the extractor utilizes the learned representations for downstream tasks. This process aims to learn the feature representation of point cloud data through autoregressive generation tasks and provide better representation capabilities for subsequent tasks.
Point block segmentation : This stage divides the point cloud into irregular point blocks. By splitting the point cloud into chunky subsets, the structure of the point cloud can be broken down into smaller parts for better processing. Considering the inherent sparseness and disorder of point clouds, the input point cloud is processed through the Farthest Point Sampling (FPS) and K Nearest Neighbors (KNN) algorithms to obtain center points and point patches.
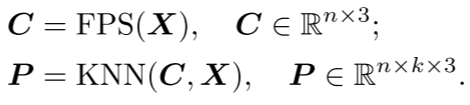
Sorting : To account for the inherent disorder of point clouds, the obtained point patches are organized into a coherent sequence based on their center points. Specifically, Morton coding is used to encode the coordinates of the center points into a one-dimensional space, and then sorted to determine the order of these center points  . Then, arrange the dot blocks in the same order.
. Then, arrange the dot blocks in the same order.
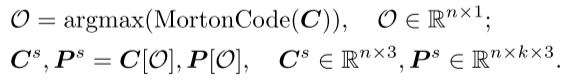
Embedding : In PointGPT, the Embedding step is used to extract rich geometric information of each point block. The sorted sequence of point blocks is embedded into the model for subsequent pre-training and task learning. Embedding can convert the geometric information of the point patch into a vector representation that the model can understand and process. The PointNet network is used here to extract geometric information.
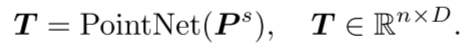
2. Extractor-generator Transformer architecture
Double masking strategy : The basic masking strategy in the Transformer decoder enables each token to receive information from all previous point tokens. In order to further promote the learning of useful representations, a double masking strategy is proposed, which additionally masks a certain proportion of the preceding tokens referenced by each token during pre-training. The resulting double mask 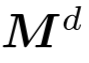 is shown in Figure 2(b). The self-attention process with double mask strategy can be expressed as:
is shown in Figure 2(b). The self-attention process with double mask strategy can be expressed as:
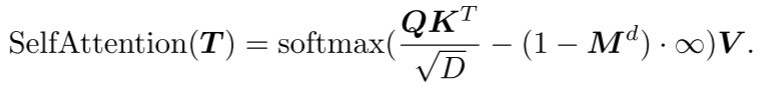
Among them, Q, K, and V are encoded by T with different weights of D channels. Set 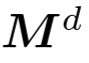 the masked positions in to 0 and the unmasked positions to 1.
the masked positions in to 0 and the unmasked positions to 1.
Extractor : The extractor consists entirely of Transformer decoder blocks and adopts a double masking strategy to obtain the latent representation  . The coordinates of the sorted center points are mapped to absolute position encoding ( APE ) using sinusoidal position encoding (PE).
. The coordinates of the sorted center points are mapped to absolute position encoding ( APE ) using sinusoidal position encoding (PE).
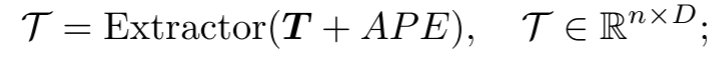
Generator : The generator has a similar architecture to the extractor but contains fewer Transformer blocks. It takes the extracted  as input and generates points for subsequent prediction heads
as input and generates points for subsequent prediction heads 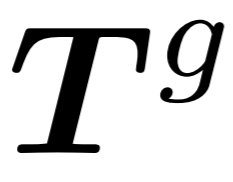 . However, since the center point sampling process may affect the order of point blocks, this introduces uncertainty when predicting subsequent point blocks. This makes it difficult for the model to effectively learn meaningful point cloud representations. In order to solve this problem, a relative direction hint ( RDP ) between center points is added to the generator , which provides direction information relative to subsequent point blocks as a hint without exposing the position of the masked point block and the overall point. The shape of the cloud object.
. However, since the center point sampling process may affect the order of point blocks, this introduces uncertainty when predicting subsequent point blocks. This makes it difficult for the model to effectively learn meaningful point cloud representations. In order to solve this problem, a relative direction hint ( RDP ) between center points is added to the generator , which provides direction information relative to subsequent point blocks as a hint without exposing the position of the masked point block and the overall point. The shape of the cloud object.
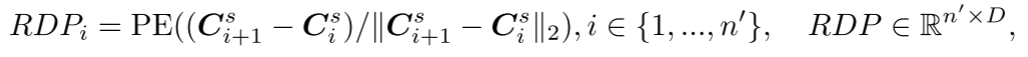
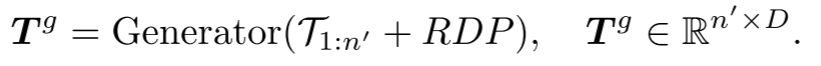
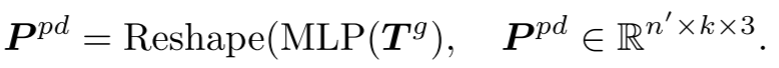
Prediction head: The prediction head is used to predict subsequent point blocks in coordinate space. It consists of a two-layer multilayer perceptron (MLP), containing two fully connected (FC) layers and (ReLU) activation function. The prediction head 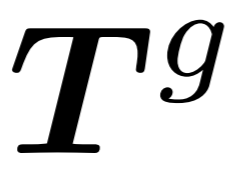 projects the tokens into vector space, where the number of output channels is equal to the total number of coordinates in a block of points. These vectors are then reorganized into predicted point blocks.
projects the tokens into vector space, where the number of output channels is equal to the total number of coordinates in a block of points. These vectors are then reorganized into predicted point blocks.
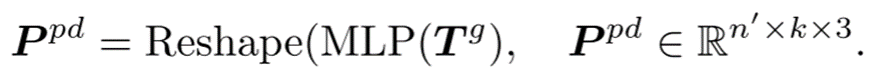
3. Intermediate fine-tuning and post-pre-training stages
Traditional point cloud self-supervised learning (SSL) methods directly fine-tune pre-trained models on the target dataset, which may lead to potential overfitting problems due to limited semantic supervision information. To alleviate this problem and facilitate training of high-capacity models, PointGPT adopts an intermediate fine-tuning strategy and introduces a post-training stage. In this stage, training is performed using a labeled hybrid dataset that collects and aligns multiple labeled point cloud datasets. By performing supervised training on this dataset, semantic information can be effectively merged from multiple sources. Subsequently, fine-tuning is performed on the target dataset to transfer the learned general semantic knowledge to task-specific knowledge. This strategy of intermediate fine-tuning and pre-training stages helps improve the model's generalization ability, avoid potential overfitting problems, and utilize diverse semantic information to improve model performance.
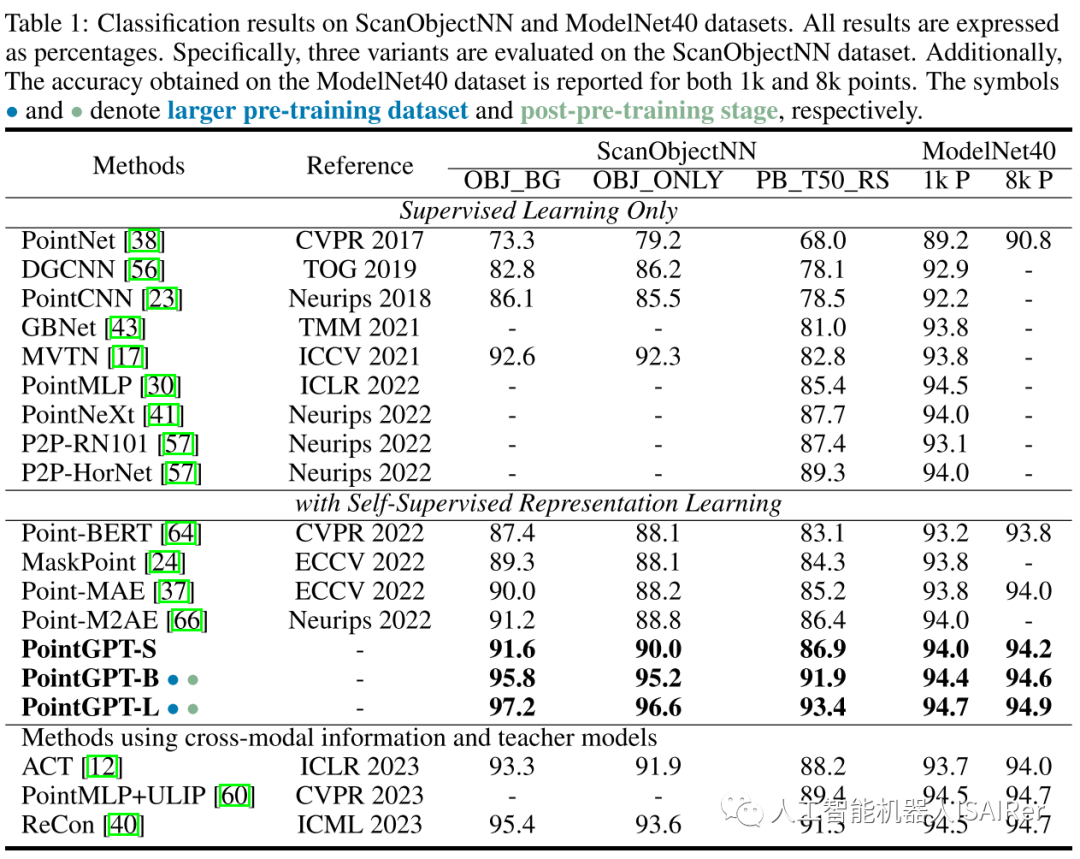
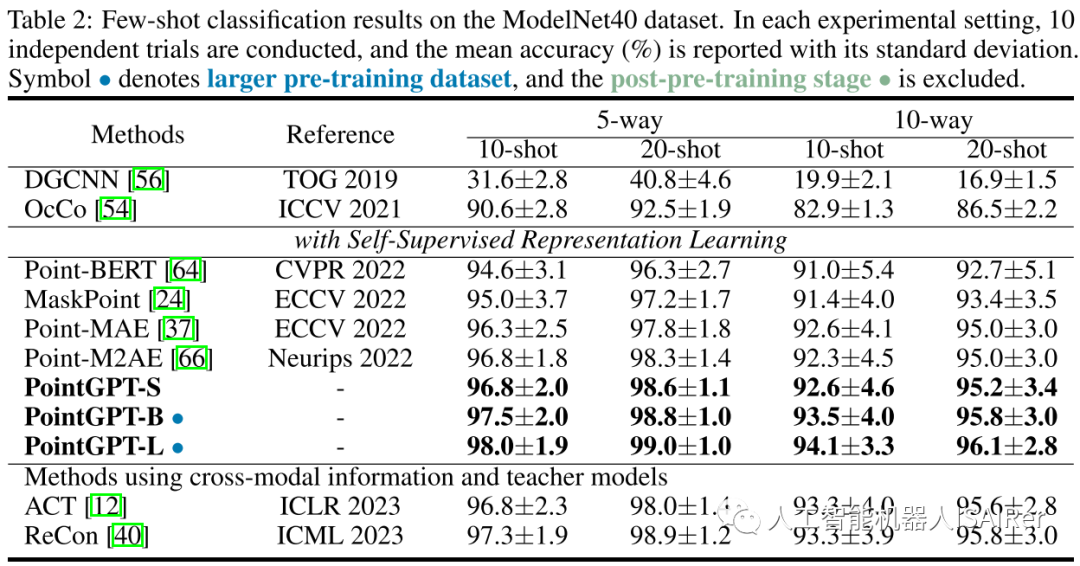
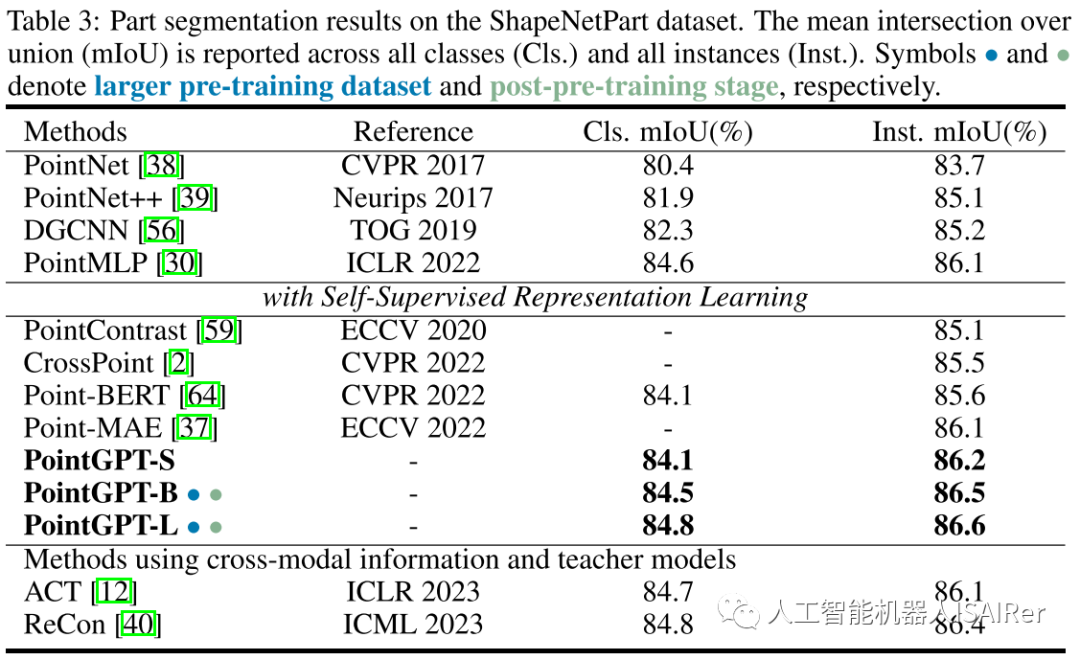
Experimental results
To demonstrate the performance of PointGPT on different downstream tasks, this paper conducts a series of experiments, including object classification, few-shot learning, and part segmentation on real-world and clean object datasets. Three different model capacities are used to evaluate the performance of PointGPT: PointGPT-S, which is pre-trained on the ShapeNet dataset but without the post-pre-training stage; PointGPT-B and PointGPT-L, which are performed on the collected mixed dataset. Pre-training and post-pre-training phases.
PointGPT-S is pre-trained on the ShapeNet dataset without subsequent post-pre-training. This is consistent with the previous SSL method for direct comparison with the previous method. In addition, to support the training of high-capacity PointGPT models (PointGPT-B and PointGPT-L), two datasets were collected: (1) Unlabeled hybrid dataset (UHD) for self-supervised pre-training, from various data Centrally collect point clouds, such as ShapeNet and S3DIS for indoor scenes and Semantic3D for outdoor scenes. UHD contains about 300K point clouds in total; (2) Labeled Hybrid Dataset (LHD) for supervised post-training, which aligns the label semantics of different datasets, with a total of 87 categories and about 200k point clouds.
Conclusion & Discussion
This paper introduces PointGPT, a new method that extends the GPT concept to the point cloud domain, solving challenges such as the disordered nature of point clouds, differences in information density, and the gap between generation tasks and downstream tasks. Different from the recently proposed self-supervised occlusion point modeling methods, our method avoids leakage of the overall object shape and has better generalization ability. Additionally, this paper explores the training process of high-capacity models and collects mixed datasets for pre-training and post-pre-training stages. The method in this paper has verified its effectiveness and strong generalization ability on various tasks, indicating that PointGPT performs well among single-modal methods with similar model capacity. In addition, our large-scale model achieves SOTA performance on various downstream tasks without the involvement of cross-modal information and teacher models. Although PointGPT has shown good performance, the data and model sizes it explores are still orders of magnitude smaller than those in the NLP and image processing fields.
Reply in the background of CVer WeChat public account: PointGPT, you can download the pdf and code of this paper
Click to enter -> [3D Point Cloud and Transformer] communication group
ICCV/CVPR 2023 paper and code download
Backstage reply: CVPR2023, you can download the collection of CVPR 2023 papers and code open source papers
Backend reply: ICCV2 023, you can download the collection of ICCV 2023 papers and code open source papers
3D点云交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-3D点云 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如3D点云+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看