Original text: https://mp.weixin.qq.com/s/vPNPdbZy11q1qsfEz9etZQ
1 Introduction to entropy weight method
Entropy is derived from the Greek word "change", which means the capacity of change . The German physicist Clausius introduced the concept of entropy in order to format the second law of thermodynamics.
The concept of entropy comes from thermodynamics and is an irreversible phenomenon used to describe processes. Later, Shannon was the first to introduce entropy into information theory. In information theory, entropy is used to express the uncertainty of the occurrence of things, and entropy is used as a measure of uncertainty .
The entropy weight method is a method to determine the weight of indicators based on the amount of information provided by each indicator survey data . Its basic principle is that if the entropy value of an indicator is small and the entropy weight is large , it means that the indicator can provide The greater the amount of information , the greater the role it can play in decision-making; on the contrary, when the entropy value of an indicator is large and the entropy weight is small, it means that the indicator can provide less information and play a greater role in decision-making. The effect will be smaller.
The entropy weight method is an objective assignment method that relies on the discrete nature of the data itself . It is used to comprehensively score samples by combining multiple indicators to achieve comparisons between samples .
2 Calculation steps of entropy weight method
1) Select data
Select mmm indicators, totalnn samples, thenX ij X_{ij}XijPart IIThe jjthsample of iValues of j indicators:
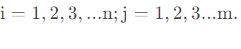
2) Data standardization processing
When the measurement units and directions of various indicators are not uniform, the data need to be standardized. In order to avoid the meaningless logarithm when calculating the entropy value, a real number of smaller magnitude can be added to each 0 value, such as 0.01.
- For positive indicators (bigger is better)

- For negative indicators (the smaller the better)
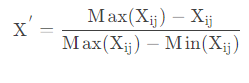
3) Calculate jjthii under j indicatorThe proportion of i samples accounting for this indicator
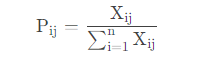
4) Calculate the jjthThe entropy value of j indicators
The larger the entropy is, the more chaotic the system is and the less information it carries. The smaller the entropy is, the more orderly the system is and the more information it is carrying.
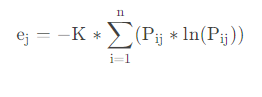
P i j = 0 P_{ij}=0 Pij=0 ,ej = 0 e_j=0ej=0; K = 1 ln ( n ) K=\frac{1}{\ln (n)} K=ln ( n )1, where nnn is the number of samples.
5) Calculate the jjthDifference coefficient of j index
The information utility value of an indicator depends on the information entropy of the indicator ej e_jejThe difference between 1 and 1, its value directly affects the size of the weight. The greater the information utility value, the greater the importance to the evaluation and the greater the weight.
6) Calculate the weight of evaluation indicators
The essence of using the entropy method to estimate the weight of each indicator is to use the difference coefficient of the indicator information to calculate. The higher the difference coefficient, the greater the importance to the evaluation (or the greater the weight, the greater the contribution to the evaluation results). larger)
jj _The weight of j indicators:
7) Calculate the comprehensive score of each sample
3 python implementation
import numpy as np
#输入数据
loss = np.random.uniform(1, 4, size=5)
active_number = np.array([2, 4, 5, 3, 2])
data = np.array([loss, active_number]) # 2个变量5个样本
print(data)
# 定义熵值法函数
def cal_weight(x):
'''熵值法计算变量的权重'''
# 正向化指标
#x = (x - np.max(x, axis=1).reshape((2, 1))) / (np.max(x, axis=1).reshape((2, 1)) - np.min(x, axis=1).reshape((2, 1)))
# 反向化指标
x = (np.max(x, axis=1).reshape((2, 1)) - x) / (np.max(x, axis=1).reshape((2, 1)) - np.min(x, axis=1).reshape((2, 1)))
#计算第i个研究对象某项指标的比重
Pij = x / np.sum(x, axis=1).reshape((2, 1))
ajs = []
#某项指标的熵值e
for i in Pij:
for j in i:
if j != 0:
a = j * np.log(j)
ajs.append(a)
else:
a = 0
ajs.append(a)
ajs = np.array(ajs).reshape((2, 5))
e = -(1 / np.log(5)) * np.sum(ajs, axis=1)
#计算差异系数
g = 1 - e
#给指标赋权,定义权重
w = g / np.sum(g, axis=0)
return w
w = cal_weight(data)
print(w)
result:
[[1.57242561 1.12780429 2.24411338 2.36236155 2.37789035]
[2. 4. 5. 3. 2. ]]
[0.70534397 0.29465603]
Reference:
https://blog.csdn.net/weixin_43425784/article/details/107047869
https://blog.csdn.net/mzy20010420/article/details/127327787